Clear Sky Science · nl
Menselijke en algoritmische visuele aandacht bij rijsituaties
Waarom dit belangrijk is voor dagelijks rijden
Naarmate auto’s steeds meer geautomatiseerd raken, blijft een cruciale vraag: "zien" zelfrijdende systemen de weg op dezelfde manier als mensen? Deze studie onderzoekt hoe menselijke bestuurders en kunstmatige intelligentie hun visuele aandacht richten in het verkeer, en toont aan dat het zorgvuldig toevoegen van een stukje mensachtige aandacht rij-algoritmes zowel slimmer als veiliger kan maken—zonder gigantische, energie-intensieve AI-modellen.
Hoe menselijke ogen zich op de weg bewegen
De onderzoekers plaatsten eerst onervaren en ervaren bestuurders in een gesimuleerde rijomgeving en volgden hun oogbewegingen terwijl ze drie veelvoorkomende veiligheidstaken uitvoerden: het ontdekken van gevaar, het inschatten of het veilig was om te draaien of van rijstrook te wisselen, en het detecteren van vreemde, niet-thuis-horende objecten. Ze vonden dat de aandacht van bestuurders een betrouwbaar drie-stappenritme volgt. In de scanningsfase, direct nadat een scène verschijnt, zwiepen de ogen breed over het beeld, grotendeels geleid door waar dingen zich bevinden. In de onderzoekendefase richt de aandacht zich op het ene meest informatieve gebied—zoals een overstekende voetganger of een blokkerende auto—en bestudeert de details en betekenis ervan. Ten slotte vergelijken bestuurders in de herbeoordelendefase dat sleutelobject met anderen, waarbij ze hun blik heen en weer verschuiven om hun oordeel te bevestigen.
Waar machines naar kijken versus waar mensen naar kijken
Het team bouwde vervolgens een op aandacht gebaseerd deep learning-model voor rijsituaties en vergeleek de interne “aandachtskaarten” daarvan met die van menselijke oogbewegingen. Het trainen van het model op algemene objectdetectie maakte de aandacht enigszins menselijker, maar het fijn afstemmen voor specifieke rijtaken bracht het vaak weg van menselijke patronen, vooral in de rijke, betekenisgerichte onderzoekende fase. Over het algemeen bleven de correlaties tussen menselijke en algoritmische aandacht bescheiden, wat suggereert dat huidige rij-AI moeite heeft om de organiserende principes te ontdekken achter waar mensen kijken en waarom.
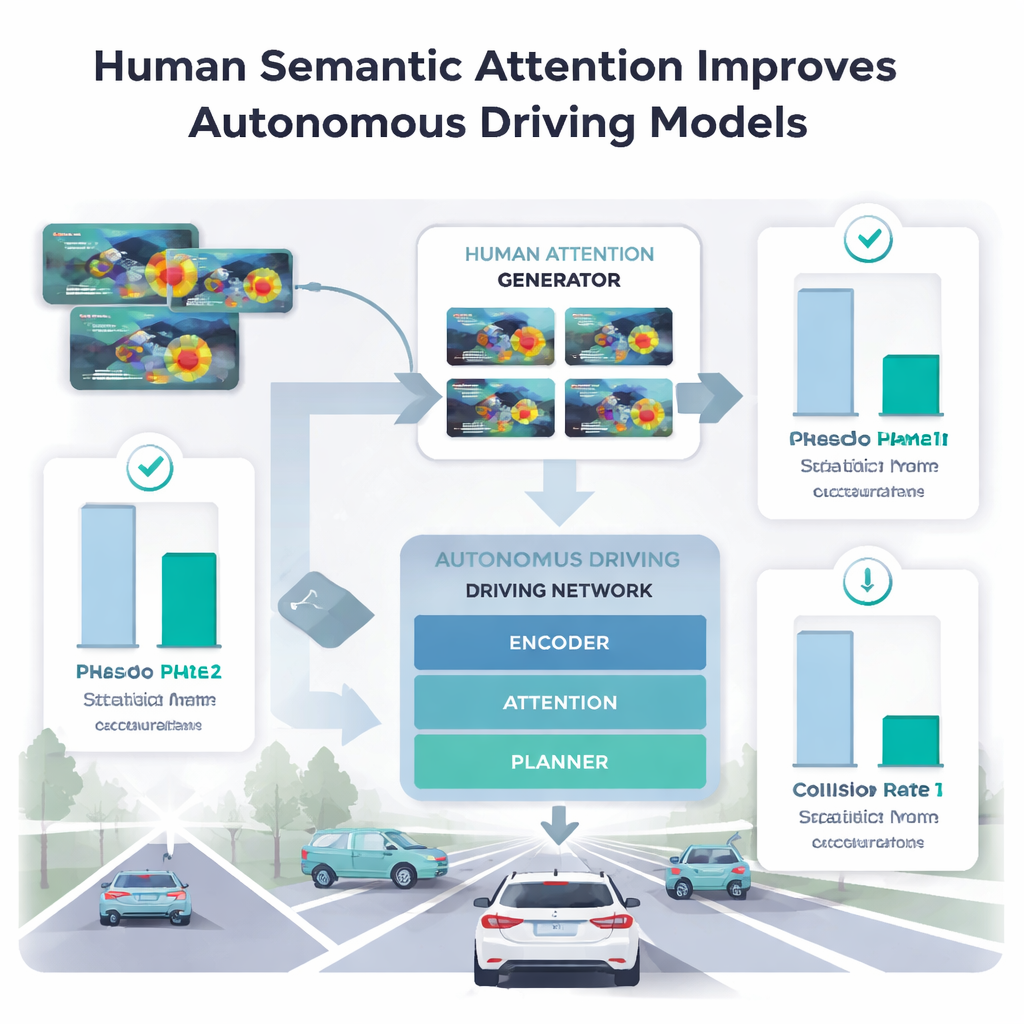
Auto’s leren mensgerichte focus te lenen
Om te onderzoeken welke onderdelen van menselijke aandacht machines daadwerkelijk helpen, voedden de auteurs verschillende fasen van menselijke blik in hun rijmodel. Direct oogvolggegevens verzamelen voor miljoenen afbeeldingen is onpraktisch, dus trainden ze een apart "genererend model voor menselijke aandacht" op een kleine steekproef van slechts vijf bestuurders. Deze generator leerde menselijke-achtige aandacht-heatmaps te voorspellen voor nieuwe scènes. Wanneer het hoofdmodel voor rijden alleen de ruimtelijke, vroege scanningsfase gebruikte, verslechterde de prestatie op anomaliëndetectie en trajectplanning vaak of resulteerde het in ogenschijnlijk veiligere paden die juist meer aan aanrijdingen blootstonden. Daarentegen, wanneer het de onderzoekende fase gebruikte—waar mensen zich concentreren op het ene meest betekenisvolle gebied—verbeterde de nauwkeurigheid voorbij eerdere methoden die volledige blik-lengtes gebruikten, en daalden de aanrijdingspercentages in planningsopgaven.
Wat grote vision-language modellen nog missen
De onderzoekers testten ook grote vision–language modellen die rijvragen beantwoorden of gedetailleerde bijschriften genereren voor 3D-straatbeelden. Voor een vraag-en-antwoordsituatie die sterk leunt op abstract redeneren, bracht het toevoegen van menselijke aandacht nauwelijks winst en soms zelfs nadeel, wat impliceert dat dergelijke modellen reeds veel van de benodigde abstracte kennis bevatten. Maar voor een veeleisende captioning-taak die precieze woorden aan precieze objecten moet koppelen, leverde de menselijke onderzoekende-fase nog steeds grote voordelen op. Dit suggereert dat grote modellen in het algemeen goed kunnen redeneren, maar nog steeds struikelen wanneer ze woorden strak moeten verbinden met exact die plekken in een drukke visuele scène—een kloof die menselijke blik kan helpen dichten.
Wat dit betekent voor veiliger geautomatiseerde auto’s
Eenvoudig gezegd betoogt de studie dat wat mensen echt onderscheidt van de huidige rij-AI niet alleen is waar we naar kijken, maar hoe we onmiddellijk inschatten wat telt in een scène. Die compacte uitbarsting van semantische aandacht—wanneer we dat ene gebied onderzoeken dat een situatie veilig of gevaarlijk maakt—lijkt precies het signaal te zijn dat veel algoritmes missen. Door te leren deze fase na te bootsen op basis van een kleine hoeveelheid eye-trackingdata, kunnen rijsystemen mensachtige begrip van wegscènes verwerven zonder uitsluitend te vertrouwen op steeds grotere, duurdere AI-modellen. Deze “semantische snelkoppeling” zou een efficiënte manier kunnen zijn om toekomstige geautomatiseerde auto’s betrouwbaarder te maken in de rommelige, onvoorspelbare omstandigheden van het echte verkeer.
Bronvermelding: Zheng, C., Li, P., Jin, B. et al. Human and algorithmic visual attention in driving tasks. npj Artif. Intell. 2, 23 (2026). https://doi.org/10.1038/s44387-026-00079-1
Trefwoorden: autonoom rijden, visuele aandacht, menselijke eye-tracking, vision-language modellen, verkeersveiligheid