Clear Sky Science · nl
De rol van grote taalmodellen in spoedeisende hulp: een uitgebreide benchmarkstudie
Waarom dit ertoe doet voor iedereen die mogelijk de SEH bezoekt
Spoedeisende hulpafdelingen zijn drukker dan ooit, met langere wachttijden en minder personeel om een groeiend aantal ernstig zieke patiënten te verzorgen. Deze studie stelt een vraag die bijna iedereen raakt: kunnen moderne AI-systemen, bekend als grote taalmodellen, artsen en verpleegkundigen op een veilige manier helpen om sneller en slimmer te werken op de spoedeisende hulp? Door meerdere toonaangevende AI’s door een reeks medische tests en gesimuleerde SEH‑casussen te halen, onderzoeken de onderzoekers hoe dicht deze hulpmiddelen in de buurt komen van betrouwbare "co‑piloten" in de acute zorg.
Spoedeisende hulpafdelingen onder zware druk
Het artikel begint met het schetsen van een toenemende crisis in de spoedeisende zorg, vooral in de Verenigde Staten. Een vergrijzende bevolking en een toename van chronische ziekten drijven het aantal SEH‑bezoeken naar recordhoogtes, ongeveer 155 miljoen in 2022 alleen al. Tegelijk kampen ziekenhuizen met ernstige tekorten aan verpleegkundigen en artsen, en het aantal bedden per persoon is de afgelopen decennia afgenomen. Een gefragmenteerd zorgsysteem bemoeilijkt de coördinatie van zorg, wat het risico op vertragingen en fouten vergroot. Tegen deze achtergrond betogen de auteurs dat nieuwe hulpmiddelen dringend nodig zijn om clinici te helpen bij triage, het nemen van snelle beslissingen en het documenteren van zorg zonder hun werklast te vergroten.
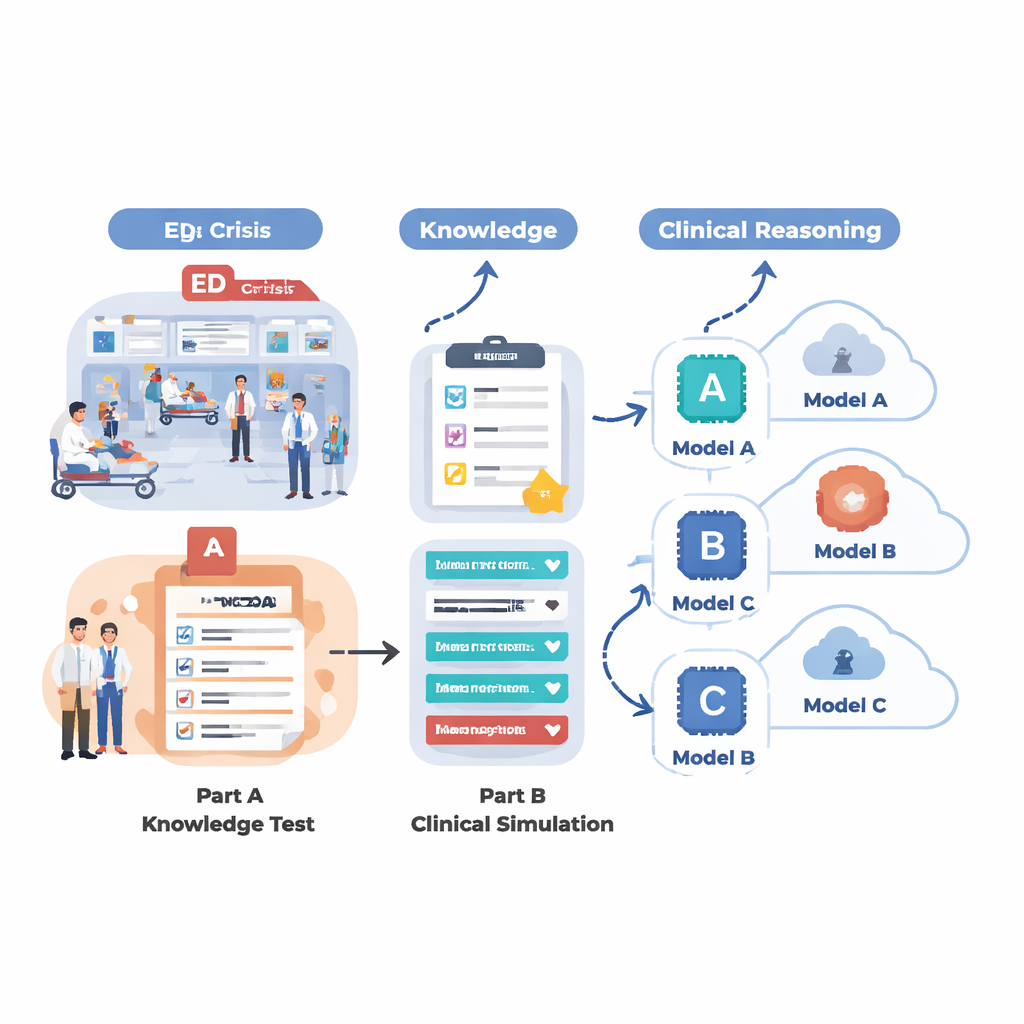
Hoe de onderzoekers medische AI hebben getest
Om te onderzoeken wat de AI‑systemen van vandaag echt kunnen in een SEH‑achtige omgeving, ontwierp het team een beoordeling in twee delen. Eerst testten ze 18 verschillende taalmodellen op een grote set meerkeuzevragen afkomstig uit MedMCQA, een medisch examen‑achtige dataset met 12 veelvoorkomende SEH‑klachten zoals pijn op de borst, kortademigheid, hoofdpijn en buikpijn. Deze fase mat basiskennis: kon de AI het juiste antwoord kiezen uit vier opties over duizenden vragen? Ten tweede namen ze de vijf sterkste modellen uit die ronde en lieten die 12 realistische spoedeisende gevallen stap voor stap uitwerken, zoals een arts dat zou doen. Voor elk geval moest de AI de patiënt samenvatten, een triage‑urgentiegraad toekennen, belangrijke vervolgvragen voorstellen, beheersstappen aanbevelen en waarschijnlijke diagnoses opsommen naarmate nieuwe informatie (vitale functies, anamnese, onderzoeksvondsten, laboratorium‑ en beeldvormingsresultaten) geleidelijk werd onthuld.
Welke AI‑modellen kenden de feiten — en welke konden redeneren
Op puur feitelijke kennis presteerden verschillende modellen indrukwekkend. Een gespecialiseerd systeem genaamd LLaMA 4 Maverick scoorde ongeveer 91 procent algemene nauwkeurigheid op de medische vragen, gevolgd door LLaMA 3.1, GPT‑4.5, GPT‑5 en Claude 4. Deze topmodellen waren consequent sterk over verschillende hoofdklachten heen, wat suggereert dat grensverleggende AI’s mogelijk een plafond naderen in boekwerkachtige medische kennis. Middelmatige systemen bleven duidelijk achter, sommige met scores rond 60 procent en moeite in belangrijke gebieden zoals wondzorg en ademhalingsproblemen. Wanneer de taak echter verschoof van het beantwoorden van geïsoleerde vragen naar het redeneren door rijke, evoluerende patiëntverhalen, werden de verschillen groter. In deze klinische simulaties stak GPT‑5 er duidelijk bovenuit: het produceerde de meest accurate en volledige samenvattingen, stelde de behulpzaamste vervolgvragen, raadde verstandige en veilige volgende stappen aan en leverde de meest grondige en goed geordende lijsten van mogelijke diagnoses.
Sterke punten, zwaktes en veiligheidszorgen
Clinici beoordeelden zorgvuldig de output van elke AI op nauwkeurigheid, relevantie en veiligheid. GPT‑5 behaalde niet alleen de hoogste scores in het algemeen; het was ook het enige model wiens prestaties stabiel bleven of verbeterden naarmate de casussen complexer werden, terwijl hallucinaties en ernstige fouten onder ongeveer 2 procent bleven. Andere modellen toonden kenmerkende zwaktes. Sommige neigden ernaar secundaire diagnoses te missen of kleine problemen vóór gevaarlijke te plaatsen. Weer anderen werden overdreven voorzichtig of vaag, of concludeerden te snel op één enkele diagnose. Over het geheel genomen onderschatten de meeste systemen hoe ziek patiënten waren bij het toekennen van triageniveaus, een conservatieve bias die urgente zorg zou kunnen vertragen als deze niet wordt gecorrigeerd. De bevindingen benadrukken een belangrijk punt: medische feiten kennen is niet hetzelfde als die feiten betrouwbaar in veilige, stapsgewijze beslissingen verweven wanneer informatie onvolledig, rommelig en veranderlijk is.

Wat dit kan betekenen voor toekomstige SEH‑bezoeken
De auteurs concluderen dat, hoewel verschillende moderne AI’s elkaar nu in medische kennis benaderen, GPT‑5 in het bijzonder een nieuw niveau van redeneervermogen laat zien dat het nuttig zou kunnen maken als een beslissingsondersteunend hulpmiddel op spoedeisende hulpafdelingen. Ze benadrukken dat deze systemen nog niet klaar zijn om clinici te vervangen of zelfstandig beslissingen te nemen. In plaats daarvan is de meest veelbelovende rol op korte termijn die van een begeleide assistent — het helpen van triageverpleegkundigen bij het inschatten van urgentie, het opstellen van patiëntsamenvattingen, het suggereren van vragen of tests en het controleren of ernstige diagnoses zijn overwogen. De studie onderstreept ook dat meer onderzoek nodig is in live klinische omgevingen, met sterke veiligheidscontroles en duidelijke gebruiksregels. Voor patiënten is de boodschap voorzichtige optimisme: AI wordt beter in het doordenken van medische problemen, maar veilig gebruik op de SEH zal afhangen van zorgvuldige ontwerpkeuzes, toezicht en een blijvende focus op het ondersteunen — niet vervangen — van het menselijke oordeel van artsen en verpleegkundigen.
Bronvermelding: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Trefwoorden: spoedeisende geneeskunde, grote taalmodellen, klinische beslissingsondersteuning, triage, benchmarking van medische AI