Clear Sky Science · nl
Verbeteren van few-shot named entity recognition voor grote taalmodellen met gestructureerde dynamische prompting en retrieval-augmented generation
Waarom slimmer lezen van medische tekst ertoe doet
De moderne geneeskunde produceert enorme hoeveelheden tekst—van intensivecare-aantekeningen tot online discussies over medicijngebruik. In die woorden schuilen cruciale aanwijzingen over ziekten, behandelingen en bijwerkingen. Het automatisch vinden en labelen van zulke tekstfragmenten, een taak die bekendstaat als “named entity recognition”, kan onderzoekers helpen uitbraken te volgen, medicijnproblemen eerder te signaleren en artsen in realtime te ondersteunen. Traditionele systemen hebben echter grote handgelabelde datasets nodig, die duur zijn om op te bouwen en vaak ontbreken voor zeldzame of opkomende gezondheidsproblemen. Deze studie onderzoekt hoe grote taalmodellen, zoals die achter hedendaagse chatbots, gestuurd kunnen worden met zorgvuldig ontworpen prompts en slimme terughaalmechanismen, zodat ze deze labeltaak goed uitvoeren ook wanneer er maar een paar geannoteerde voorbeelden beschikbaar zijn.
Machines leren belangrijke woorden te herkennen
De auteurs richten zich op biomedische named entity recognition—het vinden van vermeldingen van ziekten, geneesmiddelen, symptomen en sociale invloeden in tekst. Dit is lastig omdat medische taal sterk gespecialiseerd is, per ziekenhuis of subspecialisme kan verschillen en vaak zeldzame aandoeningen bevat die in een dataset maar weinig voorkomen. Bestaande machine-learningmodellen kunnen menselijke prestaties benaderen, maar vereisen doorgaans grote, goed geannoteerde corpora die kostbaar zijn om te maken en te delen, vooral onder strikte privacyregels. Few-shot learning, waarbij modellen leren van slechts een handvol gelabelde voorbeelden, biedt een manier om dit knelpunt te omzeilen. Grote taalmodellen zijn hiervoor bijzonder veelbelovend omdat ze patronen rechtstreeks kunnen oppikken uit instructies en voorbeelden die in de prompt worden gegeven, zonder hun interne gewichten te hertrainen.
Beter instructies samenstellen voor taalmodellen
Het eerste deel van het werk ontwerpt een sterk gestructureerde “statische” prompt—een herbruikbaar blok met instructies en voorbeelden dat aan het model wordt voorgelegd voor elke zin die gelabeld moet worden. In plaats van het model alleen op te dragen entiteiten te taggen, is de prompt opgesplitst in zes elementen: een duidelijke taakbeschrijving en definities van entiteitstypen; een korte beschrijving van de herkomst en het thema van de dataset; veelvoorkomende voorbeeldwoorden typisch voor elk entiteitstype; optionele medische achtergrondkennis; samengevatte feedback uit eerdere model fouten; en een handvol volledig geannoteerde voorbeeldzinnen. Het team testte dit kader met drie grote taalmodellen—GPT-3.5, GPT-4 en LLaMA 3-70B—op vijf biomedische datasets die klinische dossiers, wetenschappelijke abstracten en Reddit-posts over opioïdengebruik omvatten. Het zorgvuldig lagen van deze componenten verhoogde de F1-scores (een evenwicht tussen precisie en recall) met ongeveer 11–12 procentpunt ten opzichte van een basale prompt, waarbij GPT-4 de beste algehele prestaties behaalde.
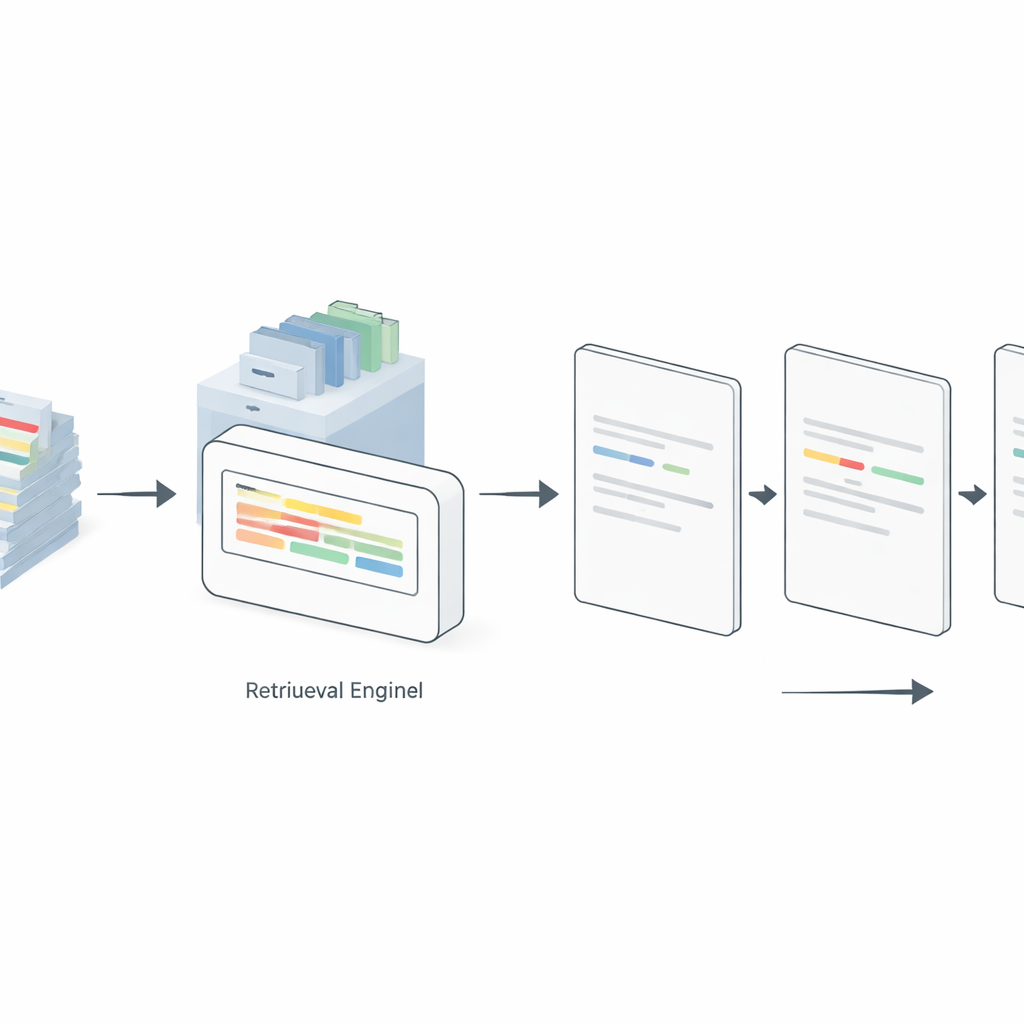
Het model voorbeelden laten opzoeken terwijl het werkt
Statische prompts tonen echter altijd dezelfde voorbeelden, zelfs wanneer die slecht aansluiten bij de nieuwe zin die gelabeld moet worden. Om dit aan te pakken introduceren de auteurs een “dynamische” promptingstrategie aangedreven door retrieval-augmented generation. Hierbij indexeert een aparte retrieval-engine alle beschikbare geannoteerde voorbeelden. Voor elke nieuwe invoerzin zoekt het systeem in deze verzameling naar de meest vergelijkbare gelabelde zinnen en voegt alleen die aan de prompt toe. De studie vergelijkt verschillende retrievalmethoden, van een eenvoudige termfrequentieschema (TF–IDF) tot neurale embed-modellen zoals Sentence-BERT (SBERT), ColBERT en Dense Passage Retrieval. Over GPT-4, LLaMA 3 en een open-weight model genaamd GPT-OSS-120B presteerde het dynamisch selecteren van relevante voorbeelden consequent beter dan statische prompting in 5-, 10- en 20-shot settings. Verrassend genoeg benaderde of overtrof de eenvoudige TF–IDF-methode vaak complexere benaderingen, vooral op schonere, meer gestandaardiseerde datasets, terwijl SBERT uitblonk bij ruisigere sociale-mediateksten.
Meer halen uit minder gelabelde voorbeelden
Aangezien het annoteren van medische tekst duur is, onderzochten de auteurs ook hoeveel gelabelde voorbeelden de retrieval-engine moet indexeren om nuttig te zijn. Met LLaMA 3-70B varieerden ze de retrievalpool van 50 voorbeelden tot de volledige trainingsset. De prestaties verbeterden over het algemeen naarmate de pool groeide, maar de winst vlakte snel af: pools van ongeveer 100–200 voorbeelden bereikten bijna dezelfde nauwkeurigheid als het indexeren van alle beschikbare data, vaak binnen de statistische foutmarge. In sommige gevallen schaadden extreem grote pools de prestaties lichtelijk, waarschijnlijk omdat ze meer irrelevante of verwarrende voorbeelden introduceerden en de prompt verlengden. Deze bevindingen suggereren dat, wanneer ze worden gecombineerd met een sterk taalmodel en goed ontworpen prompts, zelfs bescheiden annotatie-inspanningen robuuste biomedische entiteitsherkenning kunnen opleveren, waardoor de aanpak haalbaar wordt voor zeldzame ziekten, nieuwe klinische concepten of instellingen met beperkte middelen.
Wat dit betekent voor de praktijk in de geneeskunde
Alles bij elkaar laat de studie zien dat grote taalmodellen betrouwbaar belangrijke medische concepten uit tekst kunnen halen met slechts een handvol geannoteerde voorbeelden, mits ze worden geleid door gestructureerde prompts en een retrievalsysteem dat de meest relevante eerdere gevallen naar voren brengt. GPT-4 biedt de sterkste algemene prestaties, terwijl open en kleinere modellen nog steeds aanzienlijk profiteren van hetzelfde prompting- en retrievalrecept. Voor praktijkmensen betekent dit dat ze niet elke keer enorme datasets hoeven op te bouwen wanneer een nieuw entiteitstype of gezondheidsprobleem opduikt; een compacte, zorgvuldig samengestelde set voorbeelden plus slimme prompting kan voldoende zijn. Naarmate zorgsystemen aantekeningen blijven digitaliseren en patiënten hun ervaringen online delen, kunnen zulke efficiënte, aanpasbare tools het veel makkelijker maken klinisch bruikbare kennis te ontsluiten uit de enorme, rommelige wereld van medische tekst.
Bronvermelding: Ge, Y., Guo, Y., Das, S. et al. Improving few-shot named entity recognition for large language models using structured dynamic prompting with retrieval augmented generation. npj Artif. Intell. 2, 39 (2026). https://doi.org/10.1038/s44387-025-00062-2
Trefwoorden: biomedische named entity recognition, few-shot learning, grote taalmodellen, retrieval-augmented generation, klinische tekstmining