Clear Sky Science · nl
Corrigeren van verwerkings-in-geheugen multiply-accumulate rekenfouten met LDPC
Waarom het belangrijk is rekenfouten in het geheugen te herstellen
Moderne kunstmatige intelligentie-chips halen meer snelheid en efficiëntie uit hardware door berekeningen direct in het geheugen uit te voeren, in plaats van voortdurend gegevens heen en weer te sturen naar aparte processors. Deze "processing-in-memory" aanpak bespaart energie maar brengt een ernstig probleem met zich mee: kleine elektrische imperfecties kunnen opgeslagen bits omkeren of analoge signalen vervormen, waardoor de nauwkeurigheid van taken zoals beeldherkenning ongemerkt afneemt. De paper beschrijft een nieuwe manier om deze fouten automatisch en on-the-fly te detecteren en te corrigeren, zodat toekomstige AI-hardware zowel snel als betrouwbaar blijft.
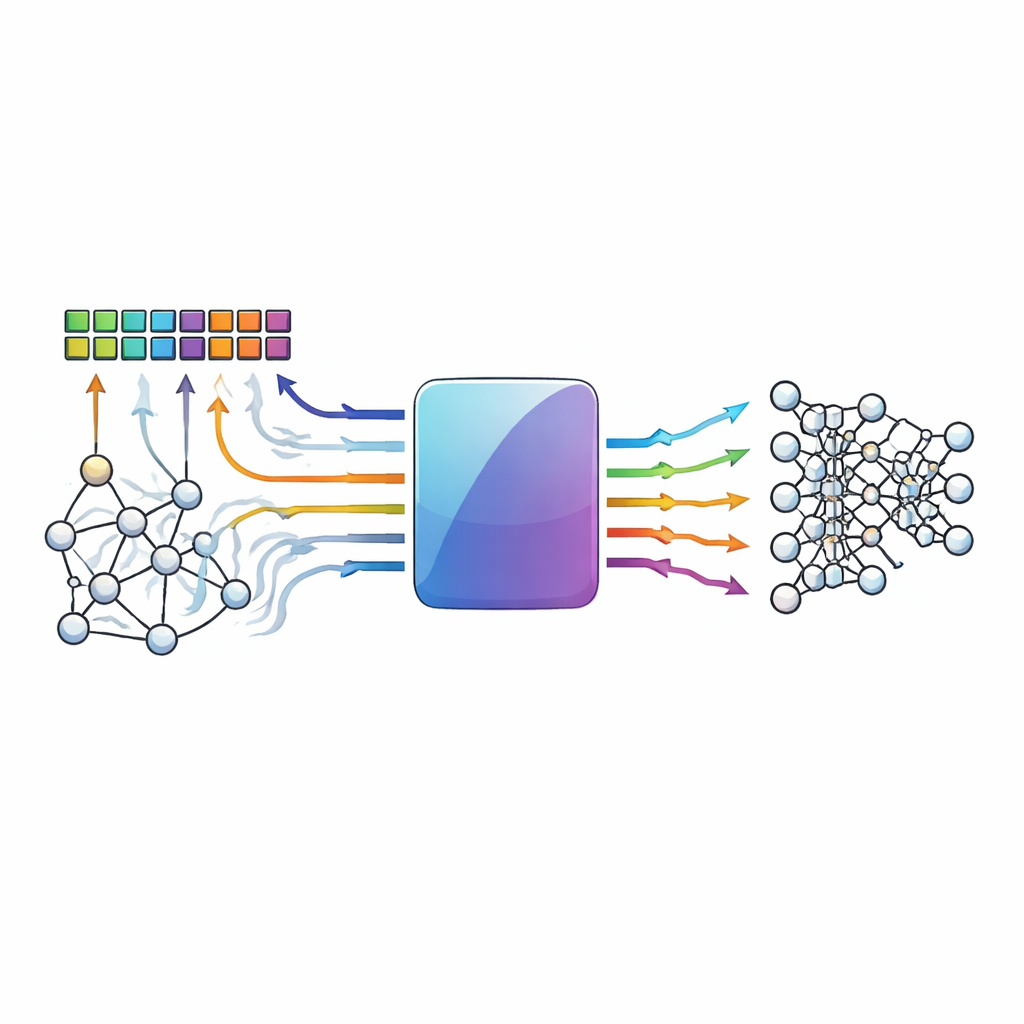
Rekenen waar de data zich bevinden
Conventionele computers worden vertraagd door de noodzaak om data tussen geheugen en processor te verplaatsen. Processing-in-memory-ontwerpen vermijden deze bottleneck door multiply-and-accumulate operaties—de ruggengraat van neurale netwerken—uit te voeren binnen dichte arrays van geheugencellen. Opkomende apparaten zoals resistief RAM en andere memristieve elementen zijn bijzonder aantrekkelijk omdat ze veel waarden kunnen opslaan en analoge rekenkunde zeer efficiënt kunnen uitvoeren. Dezelfde analoge aard en apparaatvariabiliteit die ze krachtig maken, zorgen er echter ook voor dat ze ruisgevoelig zijn: thermische fluctuaties, apparaatmismatches en spanningsvallen kunnen allemaal opgeslagen waarden of berekende resultaten afleiden van waar ze zouden moeten zijn.
Wanneer kleine glitches zich opstapelen
In deze in-memory arrays worden veel rijen cellen tegelijk geactiveerd en hun bijdragen worden op gemeenschappelijke draden opgeteld. Naarmate meer rijen deelnemen, tellen hun individuele imperfecties op en ontstaan er foutpatronen die zowel frequent als complex zijn. In plaats van een enkele verkeerde bit zien ontwerpers vaak meerdere fouten gegroepeerd in dezelfde kolom van een matrix of verspreid over meerdere kolommen op een manier die traditionele foutcorrectietechnieken omzeilt. Standaardcodes veronderstellen meestal eenvoudige foutpatronen en korte woordlengtes; ze kunnen multi-bit glitches missen of geen invoeren in hun lookup-tabellen hebben voor zeldzame maar schadelijke combinaties. Als gevolg hiervan kan de modelnauwkeurigheid van diepe neurale netwerken sterk dalen zodra de onderliggende hardware zelfs maar matig onbetrouwbaar wordt.
Een nieuw soort digitaal vangnet
De auteurs introduceren een niet-binair low-density parity-check (NB-LDPC) code die specifiek is afgestemd op processing-in-memory hardware. In plaats van alleen met nullen en enen te werken, opereert hun schema op kleine groepen bits die worden behandeld als symbolen in een wiskundige structuur genaamd een eindig veld opgebouwd uit een priemgetal (hier: drie). Dit stelt de code in staat zowel gewone binaire opslag als meerniveaus- of differentiële coderingen die veel worden gebruikt in analoge versnelleraars te beschermen. Het systeem voegt een bescheiden aantal extra symbolen—controle-symbolen—toe aan elk datablok. Tijdens zowel normale geheugenlezingen als in-memory multiply-and-accumulate bewerkingen berekent de hardware resultaten voor de data en de controlesymbolen samen, zodat foutdetectie van nature in de berekening is verweven.
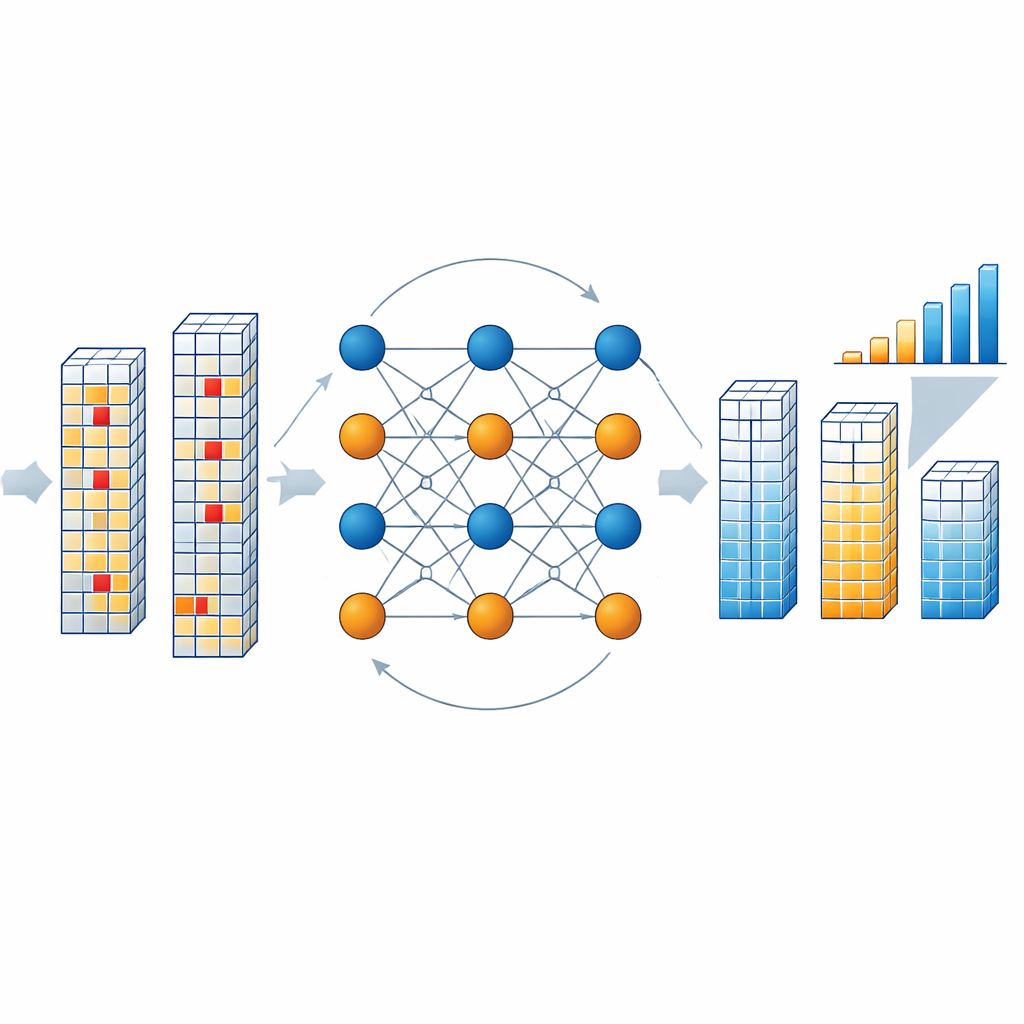
Hoe de correctiemotor binnen de chip werkt
Wanneer de chip een blok resultaten uitleest, onderzoekt een speciale decoder of de gecombineerde data- en controlesymbolen voldoen aan de pariteitsrelaties die door de code zijn gedefinieerd. Als dat zo is, wordt het blok als schoon verondersteld. Zo niet, dan start de decoder een iteratief proces waarbij abstracte "variabele knopen" die elk symbool vertegenwoordigen en "controleknopen" die pariteitsvoorwaarden vertegenwoordigen probabiliteitsberichten uitwisselen. Deze berichten schatten hoe waarschijnlijk het is dat elk symbool elke toegestane waarde aanneemt, op basis van de waargenomen uitgangen en de verwachte bitflip-foutkans van het geheugen. De auteurs vereenvoudigen deze wiskundig zware redenering met Manhattan-afstandbenaderingen, wat de hardwarekosten sterk verlaagt terwijl de prestaties hoog blijven. Na een paar rondes—gewoonlijk drie—convergeert de decoder naar de meest plausibele gecorrigeerde versie van de resultaatvector, zonder ooit het geheugen opnieuw te hoeven uitlezen of de rekenstroom te onderbreken.
Siliciumproef en impact op AI-nauwkeurigheid
Om het idee in de praktijk te testen bouwde het team een prototypechip in een 40-nanometer procestek die een resistief RAM-array, lichte analoog-naar-digitaal converters en de nieuwe NB-LDPC-decoder combineert. Met een configuratie die 256 informatiesymbolen beschermt met 32 controlesymbolen, bereikt de decoder een hoge coderingsgraad (ongeveer 0,8), een beste gemeten energie-efficiëntie van ongeveer 88 terabits gecorrigeerde data per seconde per watt, en slechts een bescheiden oppervlakte-overhead die verder verkleind kan worden door één decoder tussen meerdere geheugenmacro's te delen. Simulaties over vele codegroottes tonen aan dat bij het beschermen van 1024 datasymbolen met 128 controlesymbolen het schema de bitfoutkans bijna 60-voudig kan verbeteren. Toegepast op een ResNet-34 beeldclassificatiemodel dat draait op processing-in-memory hardware, herstelt de correctie meer dan 20 procentpunt verloren nauwkeurigheid onder uitdagende foutcondities.
Wat dit betekent voor toekomstige AI-chips
In eenvoudige bewoordingen levert dit werk processing-in-memory hardware een robuuste "spellchecker" voor zijn rekenwerk, een die rijkere symboolverzamelingen en complexe foutpatronen begrijpt zonder de datastroom te vertragen. Door bescherming te verenigen voor zowel opgeslagen data als on-the-fly berekeningen, en door een efficiënte siliciumimplementatie te demonstreren, toont de studie aan dat hoge-dichtheid, energiezuinige in-memory versnelleraars niet ten koste van betrouwbaarheid hoeven te gaan. Dit soort op maat gemaakte foutcorrectie zou wel eens een sleutelcomponent kunnen worden om toekomstige neuromorfe en AI-versnelleraars zowel energiezuinig als betrouwbaar genoeg te maken voor toepassingen in de echte wereld, van mobiele apparatuur tot grootschalige datacenters.
Bronvermelding: Shi, D., Fu, Y., Zhu, Y. et al. Correcting processing-in-memory multiply-accumulate arithmetic errors with LDPC. npj Unconv. Comput. 3, 14 (2026). https://doi.org/10.1038/s44335-026-00061-9
Trefwoorden: processing-in-memory, foutcorrectie, LDPC-codes, resistief RAM, neurale netwerkhardware