Clear Sky Science · nl
Beoordeling van grondversnellingsvoorspellingen met waarnemingen en informatietheorie: toepassing op het noordoostelijke Tibetaanse Hoogland
Waarom dit belangrijk is voor mensen en plaatsen
Aardbevingen laten niet alleen de grond schudden; ze toetsen ook de veiligheid van steden, dammen en levensaders waarop miljoenen mensen vertrouwen. In het noordoostelijke Tibetaanse Hoogland, een ruw gebied doorsneden door actieve breuken, moeten ingenieurs inschatten hoe heftig de grond zal schudden bij toekomstige bevingen, ook al zijn slechts enkele moderne gebeurtenissen goed geregistreerd. Deze studie onderzoekt hoe te beoordelen welke wiskundige recepten voor het voorspellen van trillingen het meest betrouwbaar zijn in zulke dataarme maar hoogrisicogebieden.
Een onrustige hoek van Azië
Het noordoostelijke Tibetaanse Hoogland ligt op het samenstuitpunt van meerdere korstschotten waar India nog steeds tegen Eurasia schuift. Het gebied wordt doorkruist door een web van grote breuken en heeft tientallen matige tot grote aardbevingen voortgebracht, waaronder enkele van de sterkste in China gedurende de afgelopen eeuw. Kritieke infrastructuur, zoals een keten van grote waterkrachtdammen die een aanzienlijk deel van China’s elektriciteit levert, ligt direct in de gevarenzone. Om dergelijke bouwwerken te ontwerpen en te versterken, vertrouwen planners op grondversnellingsvoorspellingsvergelijkingen—formules die aardbevingsgrootte, afstand, breuktype en bodemcondities omzetten in schattingen van de trillingssterkte. Toch waren voor de meeste eerdere bevingen hier bijna geen sterke-bewegingsinstrumenten aanwezig, waardoor onduidelijk bleef welke bestaande formules daadwerkelijk het beste werken in dit ingewikkelde terrein.
Hoe wetenschappers doorgaans trillingsformules beoordelen
Als genoeg opnamen beschikbaar zijn, testen onderzoekers voorspellingsformules op een eenvoudige manier: zij vergelijken de trillingen die elk model voorspelt met wat instrumenten daadwerkelijk hebben gemeten. Verschillen tussen waargenomen en voorspelde waarden worden samengevat met foutstatistieken, een familie van maatstaven die vaak residuanalyse worden genoemd. Met nieuwe datasets van twee recente gebeurtenissen—the 2022 Menyuan zijschuif-aardbeving en de 2023 Jishishan stuwingsbeving—pasten de auteurs deze aanpak toe op vijf veelgebruikte formules die zijn afgestemd op China en aangrenzende regio’s. Voor Menyuan brachten alle vijf de algemene sterkte van de trillingen goed in kaart, maar één model dat specifiek voor de regio is ontwikkeld toonde de nauwkeurigste overeenkomst. Voor Jishishan hadden echter alle modellen moeite, vooral bij de zwaarste trillingen, en kwam een andere formule als beste uit de bus. De rangorde verschilde per gebeurtenis, wat laat zien dat succes bij het ene type beving geen garantie biedt voor succes bij een ander type.
Informatie gebruiken die in de modellen zelf verborgen zit
Aangezien grote, goed geregistreerde aardbevingen in deze regio zeldzaam zijn, wendde de studie zich ook tot een benadering geworteld in de informatietheorie. In plaats van te vertrouwen op directe vergelijkingen met gegevens bij elk opnamestation, kijkt deze methode naar de bredere statistische patronen van trillingen die elke formule over een ruim gebied rond een aardbeving produceert. Door die patronen te behandelen als kansverdelingen, kwantificeerden de auteurs hoeveel informatie verloren zou gaan door het verkiezen van het ene model boven het andere en zetten dit om in gewichten—getallen die aangeven hoeveel vertrouwen aan elk model gegeven moet worden. Zij testten dit kader eerst op dezelfde twee moderne bevingen om te controleren of de resultaten grotendeels overeenkwamen met de residuanalyse, en breidden het vervolgens uit naar twee grote historische gebeurtenissen uit 1920 en 1927, waarvoor geen instrumentele records bestaan.
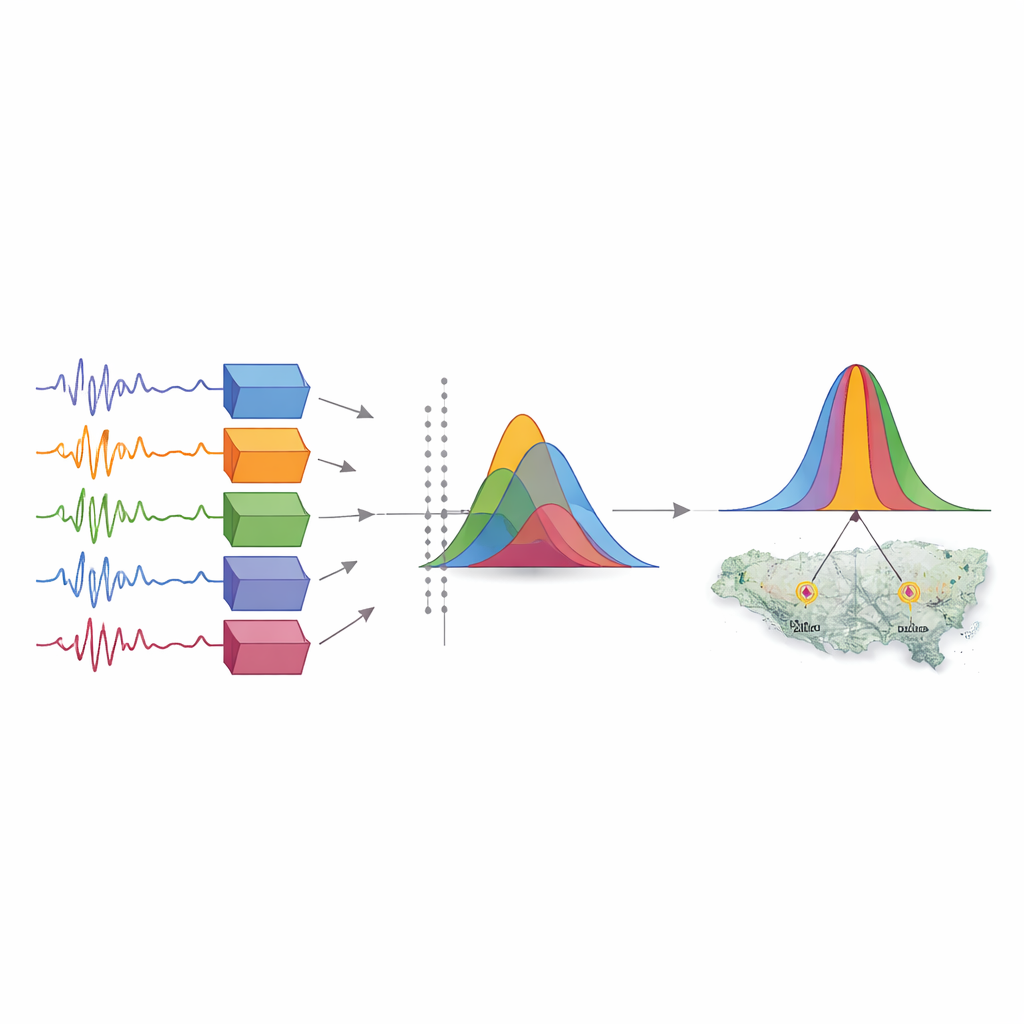
Wat de twee invalshoeken samen onthullen
Bekeken door de informatietheoriebril werden sommige patronen duidelijker. Over de vier aardbevingen kreeg één regiogerichte formule consequent het hoogste gewicht, waarbij twee andere zinvolle maar kleinere bijdragen leverden, terwijl de overgebleven twee herhaaldelijk naar beneden werden gewogen. Deze rangorde bleef stabiel, zelfs voor de historische gebeurtenissen, wat suggereert dat de methode robuuste presteerders kan identificeren wanneer directe waarnemingen schaars zijn. Tegelijkertijd benadrukte de klassieke residuanalyse hoe sterk het succes van een model afhangt van details zoals of een breuk voornamelijk zijwaarts of voornamelijk omhoog beweegt, hoe de breuk door de korst scheurt, en hoe dik zachte oppervlaktelagen zoals leem (loess) in verschillende delen van het plateau zijn. Met andere woorden: residuen belichten gebeurtenis‑tot‑gebeurtenis eigenaardigheden, terwijl informatietheorie de nadruk legt op langetermijnbetrouwbaarheid.
Wat dit betekent voor toekomstige veiligheid
Voor niet‑specialisten is de belangrijkste boodschap dat er geen enkel magisch recept bestaat voor aardbevingschudding—vooral niet in een geologisch ingewikkeld gebied met weinig moderne opnamen. Door twee verschillende manieren om de modellen te beoordelen te combineren, schetsen de auteurs een praktisch recept: gebruik residuen waar gegevens rijk zijn om te zien hoe elk model zich gedraagt voor specifieke bevingen, en gebruik informatietheorie‑gebaseerde gewichten om de beter presterende formules te mengen tot een samengestelde voorspelling die stabieler is over veel mogelijke scenario’s. Deze dubbele strategie kan de schatting van seismisch gevaar voor het noordoostelijke Tibetaanse Hoogland vandaag sturen en kan worden aangepast aan andere aardbevingsgevoelige regio’s waar de grond blijft bewegen maar de gegevens schaars blijven.
Bronvermelding: Yang, Y., Ismail-Zadeh, A. & Wu, J. Assessment of ground-motion prediction equations using observations and information theory: application to the Northeastern Tibetan Plateau. npj Nat. Hazards 3, 32 (2026). https://doi.org/10.1038/s44304-026-00196-6
Trefwoorden: aardbevinggevaar, grondbewegingvoorspelling, Tibetaanse Hoogvlakte, seismisch risico, informatietheorie