Clear Sky Science · nl
Eerlijkheidsanalyse van machine learning-voorspellingen van agressie in acute psychiatrische zorg
Waarom dit belangrijk is voor echte mensen
Ziekenhuizen zetten kunstmatige intelligentie in om te signaleren welke patiënten mogelijk agressief kunnen worden, in de hoop schade te voorkomen zonder te moeten grijpen naar traumatische vrijheidsbeperkende maatregelen. Maar als deze voorspellende hulpmiddelen oneerlijk zijn, kunnen ze de ongelijkheden verergeren die al bepalen wie als “gevaarlijk” wordt gezien. Deze studie stelt een urgente vraag: behandelt een machine die meehelpt bepalen wie in een psychiatrische eenheid hoog risico heeft, alle patiënten gelijk?
Gebruik van ziekenhuisgegevens om kortetermijnrisico te signaleren
Onderzoekers analyseerden dossiers van meer dan 17.000 patiënten die tussen 2016 en 2022 werden behandeld op acute psychiatrische afdelingen van een groot Canadees geestelijk gezondheidsziekenhuis. Voor elk van maximaal drie dagen tijdens een opname noteerden medewerkers een standaard bedzijde-checklist, de Dynamic Appraisal of Situational Aggression (DASA), die gedragingen als prikkelbaarheid of verbale dreigementen beoordeelt en signalen van dreigende agressie weergeeft. Het team combineerde deze scores met bij opname verzamelde informatie — zoals diagnose, leeftijd, geslacht, ras of etniciteit, woonsituatie en hoe de persoon in het ziekenhuis was gekomen — om een machine-learningmodel te trainen dat voorspelde of de patiënt binnen de volgende 24 uur bij een agressief incident betrokken zou zijn (inclusief het gebruik van vrijheidsbeperkende maatregelen of separatie).
Hoe het voorspellingsinstrument het in het algemeen deed
Het best presterende systeem gebruikte een veelgebruikt machine-learningalgoritme genaamd random forest. Op achtergehouden testdata rangschikte het in veel gevallen dagen met hoger risico correct hoger, met een “area under the curve” van ongeveer 0,81 — vergelijkbaar met soortgelijke hulpmiddelen in de psychiatrie. Agressie kwam echter weinig voor — er waren grofweg 33 dagen zonder incidenten voor elke dag met een incident — dus het model miste nog steeds veel echte gebeurtenissen en genereerde ook enkele valse alarmen. Belangrijkheidsmetingen lieten zien dat momentane klinische factoren, vooral DASA-items zoals prikkelbaarheid en recente eerdere incidenten, het sterkst bijdroegen aan de voorspellingen, meer dan demografische kenmerken alleen. Dat betekent dat het model klinisch relevante waarschuwingssignalen oppikte, maar de prestatiemaatstaven alleen lieten niet zien of het model voor iedereen even betrouwbaar was.
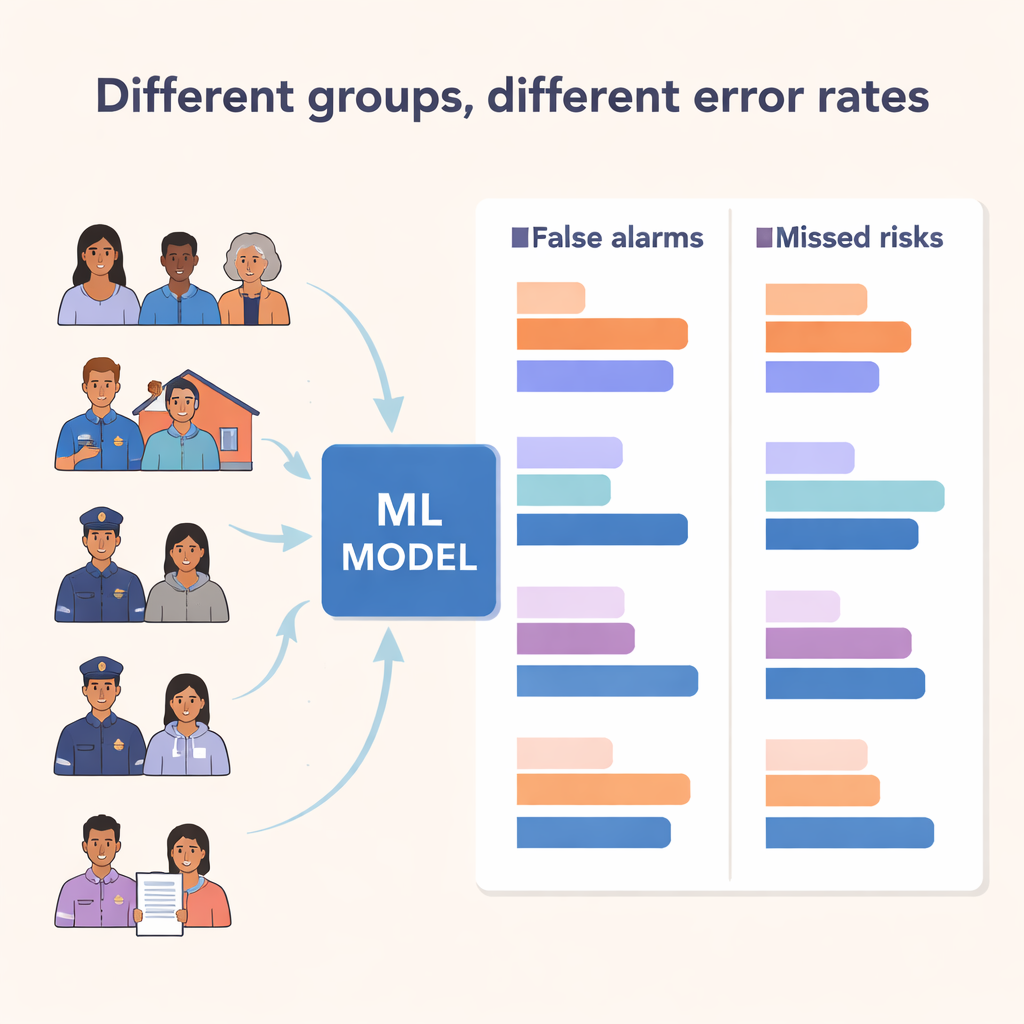
Ongelijke fouten tussen verschillende groepen
De kern van de studie was een eerlijkheidscontrole. Het team richtte zich op twee fouttypen: false positives, waarbij het model risico signaleert maar er niets gebeurt, en true positives, waarbij het juist een incident voorspelt. Een eerlijk model — volgens een veelgebruikte standaard genaamd “equalized odds” — zou vergelijkbare false positive- en true positive-percentages over groepen heen moeten hebben. In plaats daarvan vonden de onderzoekers grote verschillen. False positives waren hoger voor Midden-Oosterse en zwarte patiënten, mannen, mensen die door de politie naar het ziekenhuis waren gebracht, en mensen zonder vaste woonplek of in begeleid wonen. Sommige groepen — zoals patiënten opgenomen door de politie of mensen met instabiele huisvesting — hadden zowel hogere detectiepercentages als meer valse alarmen, wat suggereert dat het model extra gevoelig was voor hen. Andere groepen, zoals zwarte patiënten, ervoeren een verontrustende combinatie: meer valse alarmen en een slechtere capaciteit om echt risico correct te identificeren.
Wanneer identiteiten elkaar kruisen, worden de kloven groter
Aangezien iemands ervaringen door meer dan één kenmerk tegelijk worden gevormd, onderzochten de onderzoekers ook overlappende identiteiten, met name de combinatie van ras of etniciteit en geslacht. Hier stak de grootste waarschuwing af voor Midden-Oosterse mannen, die het hoogste false positive-percentage van alle groepen hadden, terwijl Midden-Oosterse vrouwen dat niet hadden. Zwarte en inheemse mannen kregen ook verhoogde false positives vergeleken met vrouwen van dezelfde achtergrond. Deze patronen weerspiegelen goed gedocumenteerde ongelijkheden in de geestelijke gezondheidszorg, zoals hogere politie-inmenging, gedwongen opnames en verkeerde diagnose bij bepaalde geracialiseerde groepen en bij mannen. Het machine-learningstelsel heeft die ongelijkheden niet veroorzaakt, maar het leerde van data die erdoor doordrongen zijn — en liep het risico ze bij klinische beslissingen te versterken.
Wat dit betekent voor toekomstige AI in de psychiatrie
De auteurs betogen dat eerlijkheidsanalyse als een kernveiligheidscontrole moet worden behandeld, niet als een optionele toevoeging, voordat een voorspellend hulpmiddel in de praktijk wordt genomen. Ze merken op dat technische “debiasing”-methoden — zoals het aanpassen van trainingsdata of het instellen van verschillende waarschuwingsdrempels voor verschillende groepen — kunnen helpen, maar beperkt zijn als de onderliggende dossiers al ongelijke behandeling en dwingende praktijken weerspiegelen. Uiteindelijk is bepalen wat een “eerlijk” model is niet alleen een wiskundig probleem; het is een sociale en ethische kwestie die input vraagt van patiënten, clinici en gemeenschappen. Deze studie laat zien dat hoewel machine learning kan helpen kortetermijnrisico op agressie te identificeren, het ook stilletjes structureel racisme, seksisme en huisvestingsongelijkheden kan reproduceren tenzij eerlijkheid rigoureus wordt gemeten, bediscussieerd en aangepakt.
Bronvermelding: Wang, Y., Sikstrom, L., Xiao, R. et al. Fairness analysis of machine learning predictions of aggression in acute psychiatric care. npj Mental Health Res 5, 16 (2026). https://doi.org/10.1038/s44184-026-00194-6
Trefwoorden: algorithmische eerlijkheid, psychiatrische agressie, machine learning in de gezondheidszorg, gezondheidsongelijkheid, risicovoorspellingsmodellen