Clear Sky Science · nl
Voorgeconditioneerde inexacte stochastische ADMM voor diepe modellen
Slimmer trainen voor slimere AI
Moderne kunstmatige-intelligentiesystemen, van chatbots tot afbeeldingsgeneratoren, worden aangedreven door enorme neurale netwerken die berucht moeilijk en duur zijn om te trainen. Nu bedrijven en onderzoekers data verspreiden over veel apparaten en servers, lopen de standaardtrainingsmethoden van vandaag vaak vast, worden onstabiel of kunnen ze simpelweg niet omgaan met de rommeligheid van echte werelddata. Dit artikel introduceert een nieuwe familie van trainingsalgoritmen, gecentreerd rond een methode genaamd PISA, die snellere en betrouwbaardere leerprocessen belooft voor een breed scala aan diepe modellen, terwijl er minder wiskundige aannames over de data nodig zijn.
Waarom huidige trainingsmethoden moeite hebben
De meeste deep-learningmodellen worden getraind met varianten van stochastische gradient descent, een aanpak die modelparameters herhaaldelijk een duwtje in de richting geeft die de fout vermindert. In de loop der jaren hebben veel verfijningen — zoals Adam, RMSProp en anderen — geprobeerd deze stapgrootten slimmer te maken door ze aan te passen of door momentum toe te voegen. Deze methoden gaan er echter meestal van uit dat trainingsdata netjes geschud zijn en statistisch gelijk verdeeld over machines, en dat bepaalde wiskundige grootheden begrensd blijven. In de praktijk, vooral in settings zoals federated learning waar telefoons of edge-apparaten zeer verschillende data bevatten, worden deze aannames vaak geschonden, wat leidt tot trage convergentie of slechte prestaties.
Een nieuwe manier om veel lerende entiteiten te coördineren
De auteurs bouwen voort op een ander optimalisatiekader dat bekendstaat als de alternating direction method of multipliers (ADMM), dat goed is in het opsplitsen van een groot probleem in veel kleinere problemen die parallel opgelost kunnen worden. Hun belangrijkste bijdrage, PISA (preconditioned inexact stochastic ADMM), behoudt de sterke punten van ADMM maar vermijdt de gebruikelijke nadelen — zoals de noodzaak om volledige gradiënten over alle data te berekenen of dure matrixinversies uit te voeren. In plaats daarvan laat PISA elke cliënt of werker zijn eigen kopie van het model bijwerken met slechts een mini-batch data, en coördineert deze updates via een centraal variabele. Zorgvuldig ontworpen "preconditionering"-matrices herschikken de update-richtingen zodat het leren soepeler en efficiënter verloopt. 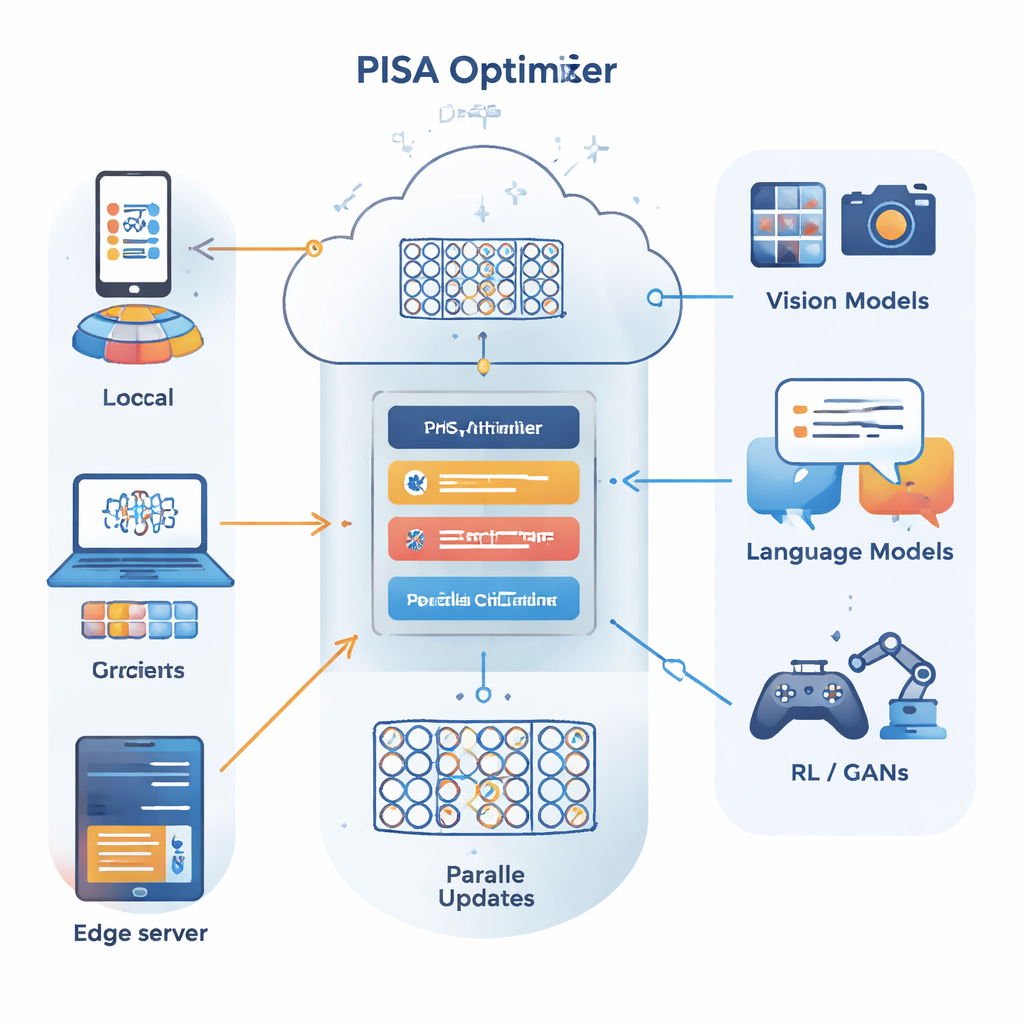
Sterkere garanties met mildere aannames
Een onderscheidend kenmerk van PISA is de theoretische onderbouwing. De auteurs bewijzen dat hun algoritme convergeert onder één relatief milde aanname: dat de gradiënt van de verliesfunctie Lipschitz-continu is binnen een begrensd gebied, een conditie die door veel standaard neurale-netwerkverliezen wordt vervuld. In tegenstelling tot de meeste stochastische methoden vereist PISA niet dat gradiënten onpartijdig zijn, een begrensde variantie hebben of afkomstig zijn van perfect gemixte data. Ondanks deze versoepelde opzet bereikt de methode een lineaire convergentiesnelheid in termen van hoe snel functiewaarden en parameterupdates stabiliseren, wat haar plaatst tussen de best presterende algoritmen in de vergelijkende tabel die is gegeven. Dit maakt PISA vooral aantrekkelijk voor heterogene, niet-uniforme data-distributies die vaak voorkomen in echte uitrolsituaties.
Praktische varianten voor echte diepe netwerken
Om het kader praktisch te maken voor grote neurale netwerken introduceren de auteurs twee efficiënte varianten, SISA en NSISA. SISA gebruikt tweede-momentinformatie — in essentie het bijhouden hoe groot eerdere updates zijn geweest in elke parameterrichting — om eenvoudige diagonale preconditioners te vormen, vergelijkbaar met ideeën achter Adam en RMSProp maar ingebed binnen de ADMM-structuur. NSISA gaat een stap verder door een techniek te incorporeren die bekendstaat als Newton–Schulz-orthogonalizatie, geïnspireerd door de Muon-optimizer, om momentum beter uit te lijnen met nuttige richtingen in de parameter‑ruimte. Beide varianten behouden PISA’s convergentiegaranties terwijl de berekening licht genoeg blijft voor moderne GPU’s en grote modellen.
Prestaties in visie-, taal- en generatieve modellen
De auteurs testen SISA en NSISA op een breed scala aan deep-learningtaken. In federated-learningexperimenten met bewust scheve labelverdelingen — een moeilijke setting waarin elke cliënt slechts een subset van klassen ziet — presteert SISA veel beter dan populaire methoden zoals FedAvg, FedProx, FedNova en Scaffold, en behaalt het veel hogere testnauwkeurigheid op benchmarks zoals MNIST en CIFAR-10. Voor standaard beeldclassificatie met modellen als ResNet en DenseNet op CIFAR-10 en ImageNet evenaart of overtreft SISA sterke optimizers waaronder SGD met momentum, AdaBelief en AdamW. Bij het fine-tunen van GPT-2-taalmodellen van toenemende grootte levert NSISA lagere validatieverlieswaarden in minder wandkloktijd dan gespecialiseerde optimizers zoals Shampoo, SOAP, Adam-mini en Muon, waarbij het voordeel duidelijker wordt voor het grootste model. Het stabiliseert ook de training van generative adversarial networks, met lagere Fréchet Inception Distance-scores, die de visuele kwaliteit en diversiteit van gegenereerde beelden meten. 
Wat dit betekent voor alledaagse AI
In eenvoudige bewoordingen laat dit werk zien dat het mogelijk is krachtige AI-modellen sneller en betrouwbaarder te trainen, zelfs wanneer data rommelig, onevenwichtig of verspreid over veel apparaten zijn. Door het onderliggende optimalisatieproces te herontwerpen in plaats van alleen de leersnelheden bij te stellen, bieden PISA en zijn varianten een uniforme tool die goed werkt voor visie-, taal-, reinforcement-learning- en generatieve taken. Voor eindgebruikers kan dit resulteren in slimmer gepersonaliseerde functies op telefoons, krachtigere taal- en afbeeldingsmodellen en efficiënter gebruik van rekencapaciteit in grote datacenters — allemaal mogelijk gemaakt door een trainingsalgoritme dat beter aansluit op de realiteit van moderne AI-systemen.
Bronvermelding: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
Trefwoorden: optimalisatie voor deep learning, federated learning, stochastische ADMM, grote taalmodellen, heterogene data