Clear Sky Science · nl
Verbetering van kcat‑voorspelling met een residu‑bewust aandachtmechanisme en voorgetrainde representaties
Waarom snellere enzymvoorspellingen ertoe doen
Enzymen zijn de kleine werkpaarden die cellen – en hele industrieën – draaiende houden. Ze versnellen chemische reacties die onze stofwisseling aandrijven, medicijnen produceren en zorgen voor duurzamere productieprocessen. Een belangrijke grootheid die aangeeft hoe snel een enzym werkt, is het omloopsnelheidgetal, of kcat. kcat in het lab meten is langzaam en duur, dus wenden wetenschappers zich tot kunstmatige intelligentie om het te voorspellen op basis van sequentie- en reactiegegevens. Dit artikel introduceert PMAK, een nieuw AI‑model dat niet alleen kcat nauwkeuriger voorspelt dan eerdere hulpmiddelen, maar ook helpt aanwijzen welke delen van een enzym het belangrijkst zijn voor zijn activiteit.
Van zwaar labwerk naar slimme voorspellingen
Traditioneel betekent kcat bepalen zorgvuldig meten hoe snel een enzym zijn substraat onder strikt gecontroleerde omstandigheden, zoals vaste temperatuur en pH, omzet in product. Dit voor duizenden enzymen doen is onpraktisch, wat de mogelijkheden beperkt om complete metabole netwerken te modelleren of nieuwe biokatalysatoren te ontwerpen. Eerdere computermethoden probeerden dit gat te dichten, maar veel leunden op handgemaakte kenmerken of bekeken een enzym en een enkel substraat op een vereenvoudigde manier. Ze werkten vaak alleen goed als nieuwe enzymen sterk leken op voorbeelden uit de trainingsdata, en hadden moeite met echt nieuwe enzymen, nieuwe reacties of gemuteerde varianten.
Computers het “taalgebruik” van enzymen en reacties leren
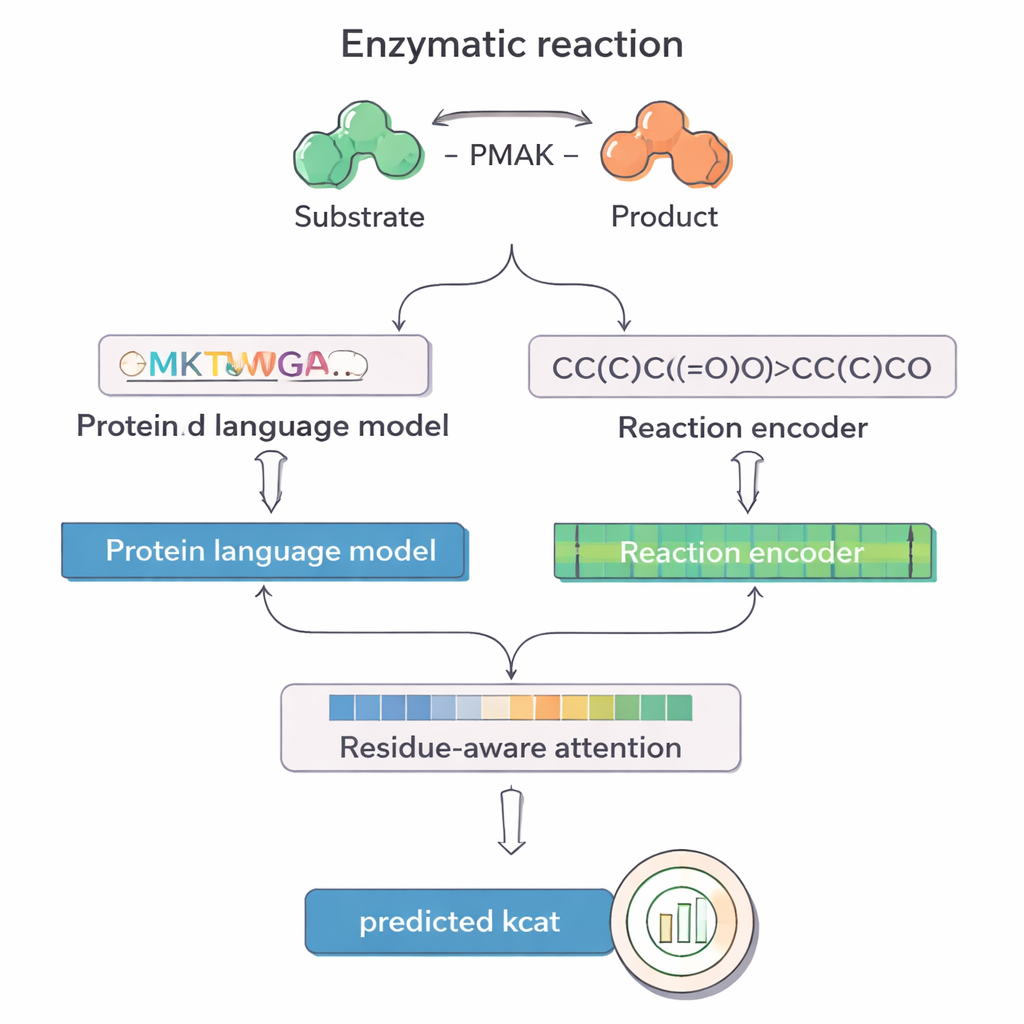
PMAK benut recente vooruitgang in ‘taalmodellen’ die oorspronkelijk voor tekst zijn ontwikkeld, maar worden getraind op enorme verzamelingen van eiwitsequenties en chemische reacties. Een model, ProT5, zet de aminozuursequentie van een enzym om in een rijke numerieke representatie die patronen vangt geleerd uit miljoenen eiwitten. Een ander model, RXNFP, doet hetzelfde voor volledige reacties geschreven als SMILES‑strings, waarin alle reactanten en producten zijn gecodeerd. PMAK voert deze twee geleerde representaties in een neuraal netwerk dat hun dimensies op elkaar afstemt en het model in staat stelt zowel het enzym als de volledige reactiecontext samen te beschouwen, in plaats van ze afzonderlijk te behandelen.
De belangrijkste bouwstenen uitlichten
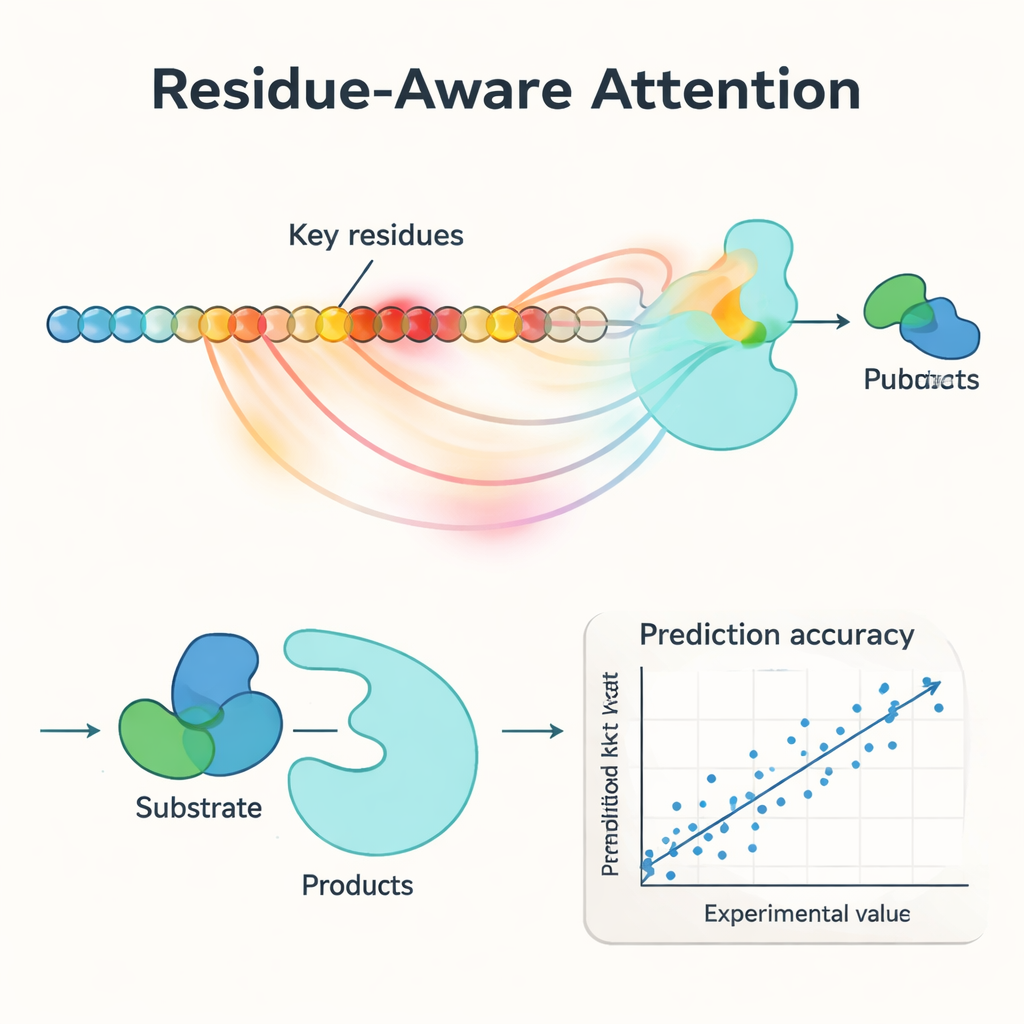
Een centrale innovatie in PMAK is een “residu‑bewust aandachtmechanisme”. In plaats van elk aminozuur in een enzym als even belangrijk te behandelen, leert het model hogere gewichten toe te kennen aan specifieke residuen die het meest relevant zijn voor de betreffende reactie. Deze aandachtsscores werken als een schijnwerper op de sequentie: toen onderzoekers ze vergeleken met bekende actieve en bindingsplaatsen uit eiwitstructuren, vonden ze dat PMAK consequent functionele residuen vaker highlightte dan op basis van toeval te verwachten viel. Het model presteerde ook goed wanneer actieve plekken ruimer werden gedefinieerd om naburige residuen in 3D‑ruimte mee te nemen, wat suggereert dat het subtiele structurele en chemische aanwijzingen relevant voor katalyse vastlegt.
Goede prestaties op nieuwe enzymen, nieuwe reacties en mutants
De auteurs hebben PMAK rigoureus getest op een gekuratteerde dataset van meer dan 4.000 kcat‑waarden die bijna 3.000 enzymen en 2.800 reacties bestrijken. Onder ‘warm‑start’ omstandigheden — waar vergelijkbare enzymen en reacties zowel in trainings‑ als testsets voorkomen — evenaarde of overtrof PMAK de beste bestaande modellen. Nog indrukwekkender was dat PMAK in ‘cold‑start’ tests, waarbij ofwel het enzym of de reactie in de testset nog nooit eerder was gezien, beter presteerde dan een reeks toonaangevende methoden. Het bleef bruikbaar zelfs voor enzymen met zeer lage sequentiegelijkheid ten opzichte van de trainingsdata en voor reacties die er substantieel anders uitzagen dan wat het model geleerd had. PMAK verbeterde ook voorspellingen in realistische toepassingen, zoals het schatten hoe cellen hun beperkte eiwitmiddelen verdelen en het voorspellen van de effecten van mutaties in datasets voor enzymengineering.
Wat dit betekent voor biologie en biotechnologie
Voor niet‑specialisten kan PMAK worden gezien als een slimme assistent die leert uit enorme eiwit‑ en reactiebibliotheken om te raden hoe snel een bepaald enzym in een specifieke reactie zal werken — en om uit te leggen welke aminozuren dat gedrag aandrijven. Door hogere nauwkeurigheid te combineren met inzicht op residuniveau kan deze aanpak onderzoekers helpen betere enzymen te ontwerpen, betrouwbaardere metabole modellen te bouwen en te verkennen hoe mutaties de functie beïnvloeden zonder ieder experiment in het lab uit te voeren. Naarmate vergelijkbare modellen uitbreiden naar andere kinetische eigenschappen, kunnen ze sleutelhulpmiddelen worden voor het ontwerpen van schonere industriële processen, het optimaliseren van microben voor duurzame productie en het verdiepen van ons begrip van hoe de moleculaire machines van het leven hun opmerkelijke snelheid bereiken.
Bronvermelding: Cai, Y., Ge, F., Zhang, C. et al. Enhancing kcat prediction through residue-aware attention mechanism and pre-trained representations. Commun Biol 9, 273 (2026). https://doi.org/10.1038/s42003-026-09551-9
Trefwoorden: enzymkinetiek, deep learning, kcat‑voorspelling, proteïne‑engineering, metabole modellering