Clear Sky Science · nl
Computationele analyse van epitoopheterogeniteit in immunokleuringen uit reeksen met antistofverdunningen
Waarom de kwaliteit van antistofkleuring ertoe doet
Van het volgen van kankercellen tot het diagnosticeren van infecties: de moderne biologie leunt sterk op antistoffen die specifieke moleculen in cellen “verlichten”. Toch worstelen veel laboratoria stilletjes met een hardnekkig probleem: kleuringen die te zwak, te ruisig of misleidend zijn. Dit artikel introduceert een praktische, computerondersteunde manier om meer informatie uit een standaardreeks met antistofverdunningen te halen, waarmee onderzoekers hun kleuring kunnen afstemmen voor helderere beelden, betrouwbaardere metingen en zelfs nieuwe methoden om meerdere doelen in één kleurkanaal te kleuren. 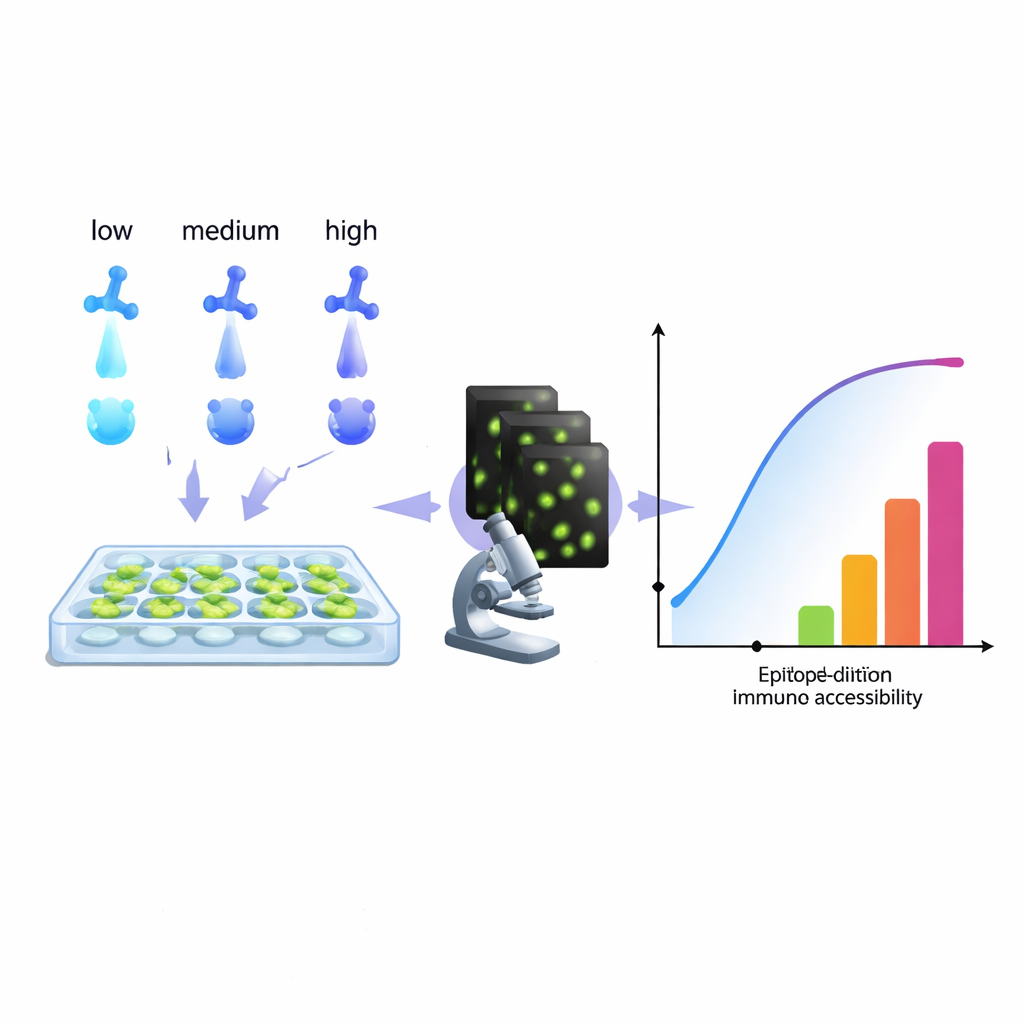
Hoe wetenschappers gewoonlijk antistofkleuringen afstemmen
Wanneer onderzoekers een immunokleuringsexperiment opzetten, kiezen ze meestal een antistofconcentratie gebaseerd op het gegevensblad, proberen een paar verdunningen en kiezen degene die “er goed uitziet”. Achter de schermen beslissen echter talloze kleine factoren—proteïnevorm, drukte in de cel, pH en hoe goed het antistof zich kan manoeuvreren—of een antistof blijft zitten of weggewassen wordt. Traditionele instrumenten die antistofbinding meten, zoals surface plasmon resonance, werken het beste op gezuiverde eiwitten op kunstmatige oppervlakken, niet op dicht opeengepakte cellen of weefsels. Dat betekent dat die cijfers niet altijd overeenkomen met het biologische systeem waarin het antistof daadwerkelijk wordt gebruikt. Als gevolg daarvan kunnen laboratoria onbewust concentraties kiezen die de wazige achtergrond versterken of belangrijke maar minder toegankelijke doelen verbergen.
Een simpele verdunningsreeks omzetten in ‘toegankelijkheidskaarten’
De auteurs stellen een andere benadering voor: beschouw een standaardreeks met antistofverdunningen als een rijke dataset en pas er een model op toe dat weerspiegelt wat het beeld echt ziet—antistoffen die gebonden blijven, zelfs na herhaald wassen. Door te analyseren hoe het signaal groeit over concentraties heen, reconstrueert hun algoritme een “toegankelijkheidshistogram”. In plaats van te proberen pure chemische bindingsconstanten te isoleren, groepeert dit histogram doelplaatsen in technische “epitoopklassen” op basis van hoe gemakkelijk ze onder echte condities te kleuren zijn. Een enkel biologisch epitoop kan in meerdere klassen voorkomen als het bijvoorbeeld op één deel van een cel gemakkelijk te bereiken is en moeilijker in een drukke regio. Belangrijk is dat deze methode direct met de microscoopuitvoer werkt, zonder gezuiverde eiwitten of extra apparatuur, zodat elk laboratorium dat een verdunningsreeks kan uitvoeren en fluorescentie kan kwantificeren in principe zulke histogrammen kan opbouwen. 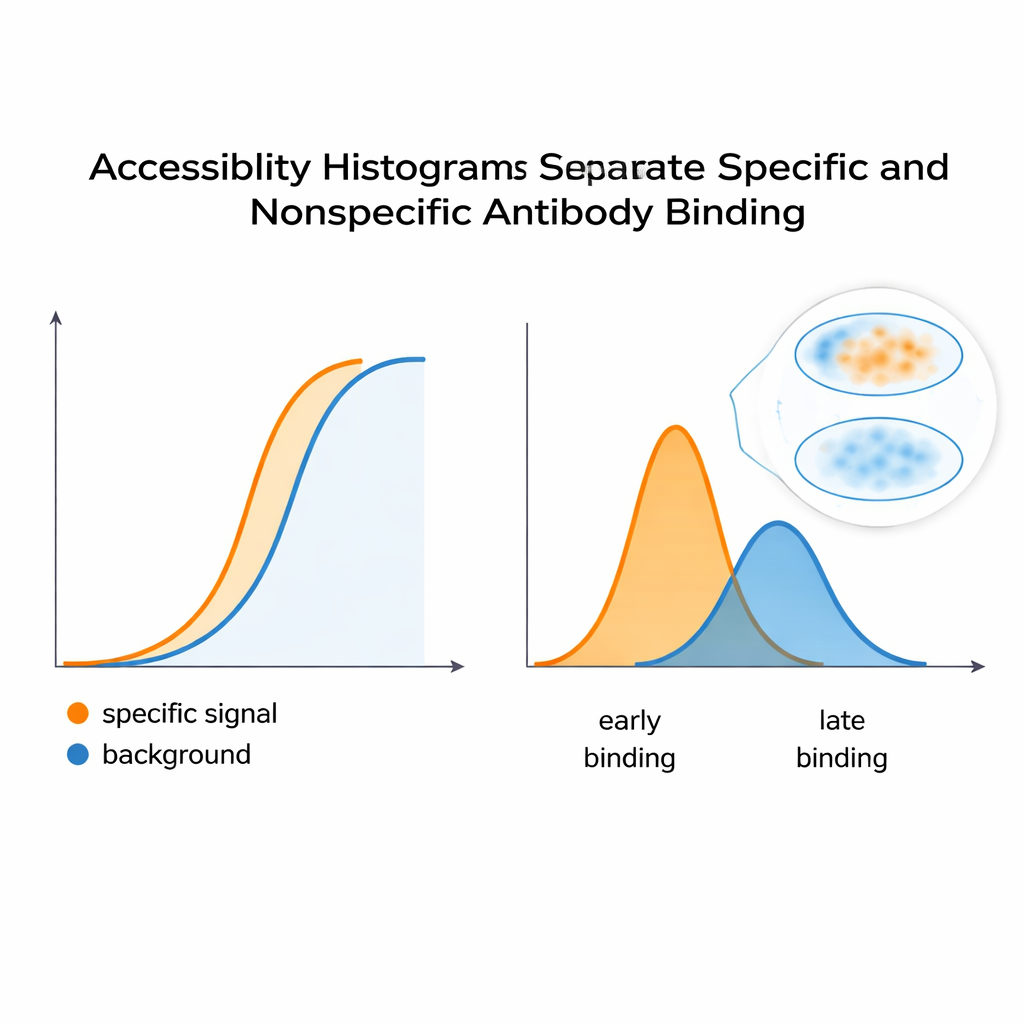
Reëel signaal scheiden van achtergrond
Om te testen of deze histogrammen daadwerkelijk het kleergedrag vangen, bouwde het team een gecontroleerd systeem met HeLa-cellen en twee monoklonale antistoffen: één die een gewenst, specifiek signaal nabootst en een andere die fungeert als ongewenste achtergrond. Wanneer ze werden gemengd, leek de gecombineerde fluorescentiekromme op een enkele, gladde respons—niets wees duidelijk op twee afzonderlijke bijdragers. Maar de computationele analyse splitste deze kromme op in afzonderlijke pieken in het toegankelijkheidshistogram, waarmee minstens twee onderliggende epitoopklassen werden onthuld. Een soortgelijke strategie toegepast op een antistof die een vormgevoelige plaats op een PKA-regulerende subunit herkent, toonde aan dat veranderingen in eiwitconformatie—geïnduceerd door een molecuul genaamd cAMP—de verdeling van toegankelijke epitopen verschoven. Dit suggereert dat de methode kan signaleren wanneer eiwitstructuren opengaan of sluiten, wat verandert hoe gemakkelijk antistoffen in cellen kunnen binden.
Beter verdunnen kiezen en meer kleuren met één kleurkanaal
Aangezien elke piek in het toegankelijkheidshistogram voornamelijk bijdraagt binnen een bepaald concentratiegebied, gebruiken de auteurs deze pieken als leidraad om “sweet spot”-verdunningen te kiezen. Pieken met lage toegankelijkheid die alleen bij zeer hoge antistofniveaus verschijnen, bevatten waarschijnlijk niet-specifieke binding, terwijl vroege pieken vaak het bedoelde doel weerspiegelen. Door te modelleren hoe individuele pieken de totale dosis–responskromme opbouwen, kan het team verdunningen voorstellen die het specifieke signaal maximaliseren voordat problematische pieken optreden—soms veel meer verdund dan leveranciers aanbevelen. Ze breiden dit idee verder uit naar een slimme vorm van “computationele multiplexing”. Door hetzelfde gefixeerde monster herhaaldelijk te kleuren met zorgvuldig gekozen concentraties, na elke ronde te beelden en eerdere beelden van latere af te trekken, isoleren ze signalen die aan verschillende toegankelijkheidsklassen zijn gekoppeld en halen zo effectief meerdere doelen uit één fluorescentiekanaal uiteen.
Wat dit betekent voor alledaags laboratoriumwerk
In eenvoudige bewoordingen verandert dit werk een routinematige probleemoplossingsstap—het uitvoeren van een antistofverdunningsreeks—in een kwantitatief hulpmiddel. De toegankelijkheidshistogrammen helpen wetenschappers verborgen complexiteit in hun kleuringen te ontdekken, verdunningen te kiezen die misleidende achtergrond verminderen en in sommige gevallen overlappende signalen te scheiden zonder extra fluorescentelabels. Hoewel het onderliggende model bewust eenvoudig is en niet elk moleculair detail vastlegt, is het ontworpen om gemakkelijk te gebruiken en robuust genoeg voor gegevens uit de praktijk. Bij brede toepassing zou deze aanpak antistofgebaseerde technieken—van basisbeeldvorming tot diagnostische assays—betrouwbaarder, informatiever en minder afhankelijk van trial-and-error kunnen maken.
Bronvermelding: Tschimmel, D., Saeed, M., Milani, M. et al. Computational epitope heterogeneity analysis in immunostainings from antibody-dilution series. Commun Biol 9, 238 (2026). https://doi.org/10.1038/s42003-026-09517-x
Trefwoorden: antistofkleuring, immunofluorescentie, epitooptoegankelijkheid, doserespons, computationele multiplexing