Clear Sky Science · nl
Operationele veiligheid definiëren in klinische systemen voor kunstmatige intelligentie
Waarom veilige AI in de geneeskunde ertoe doet
Ziekenhuizen nemen snel kunstmatige intelligentie in gebruik om scans te lezen en ziekten te signaleren, maar er is een vraag waarop gewone nauwkeurigheidsscores geen antwoord geven: wanneer is het werkelijk veilig om de machine de beslissing te laten nemen? Dit artikel introduceert een praktische manier om te beslissen wanneer artsen met vertrouwen op een AI-systeem kunnen vertrouwen, wanneer ze het moeten negeren en wanneer ze zelf nader moeten kijken. Het doel is niet alleen om slimmere algoritmen te bouwen, maar ze in het dagelijkse zorgproces te verankeren op een manier die patiënten beschermt, onnodige diagnostiek vermindert en de last voor zorgverleners verlicht in plaats van vergroot.
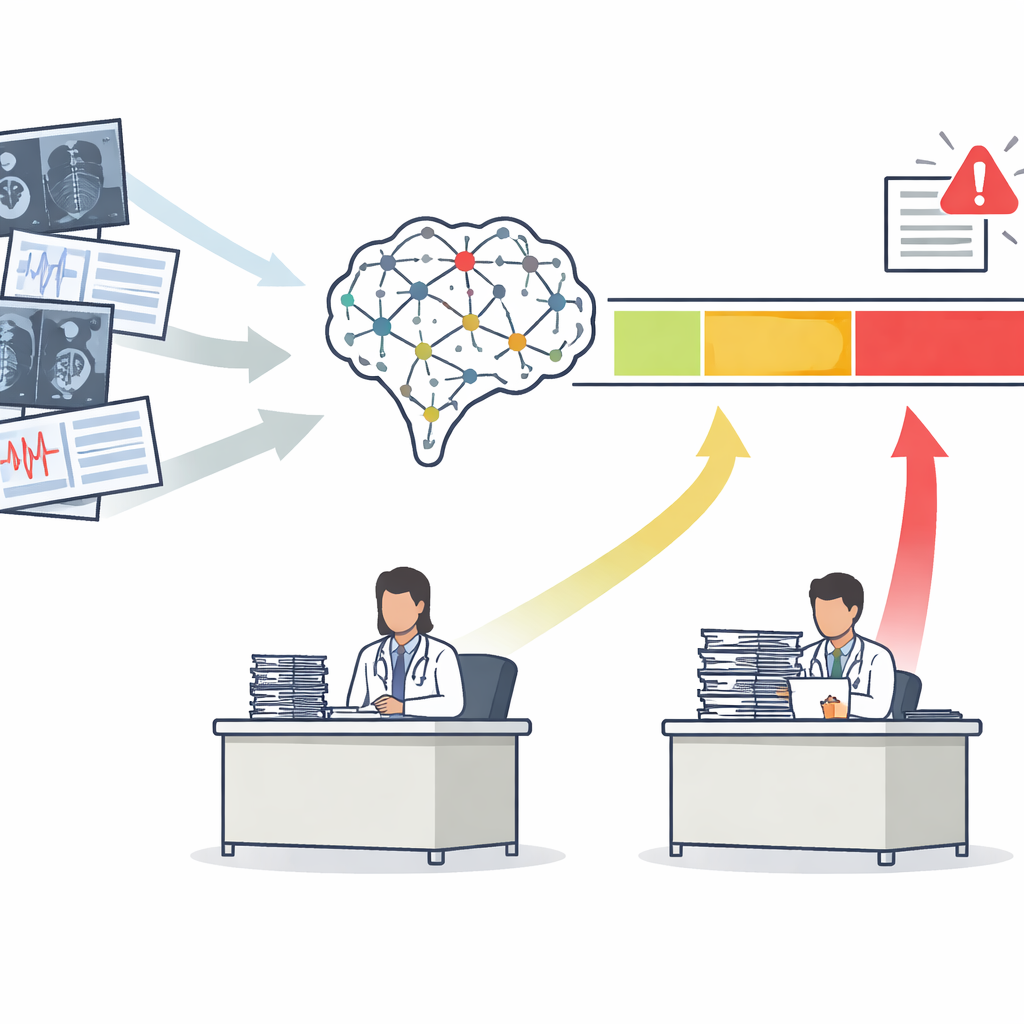
Van één score naar drie duidelijke actiezones
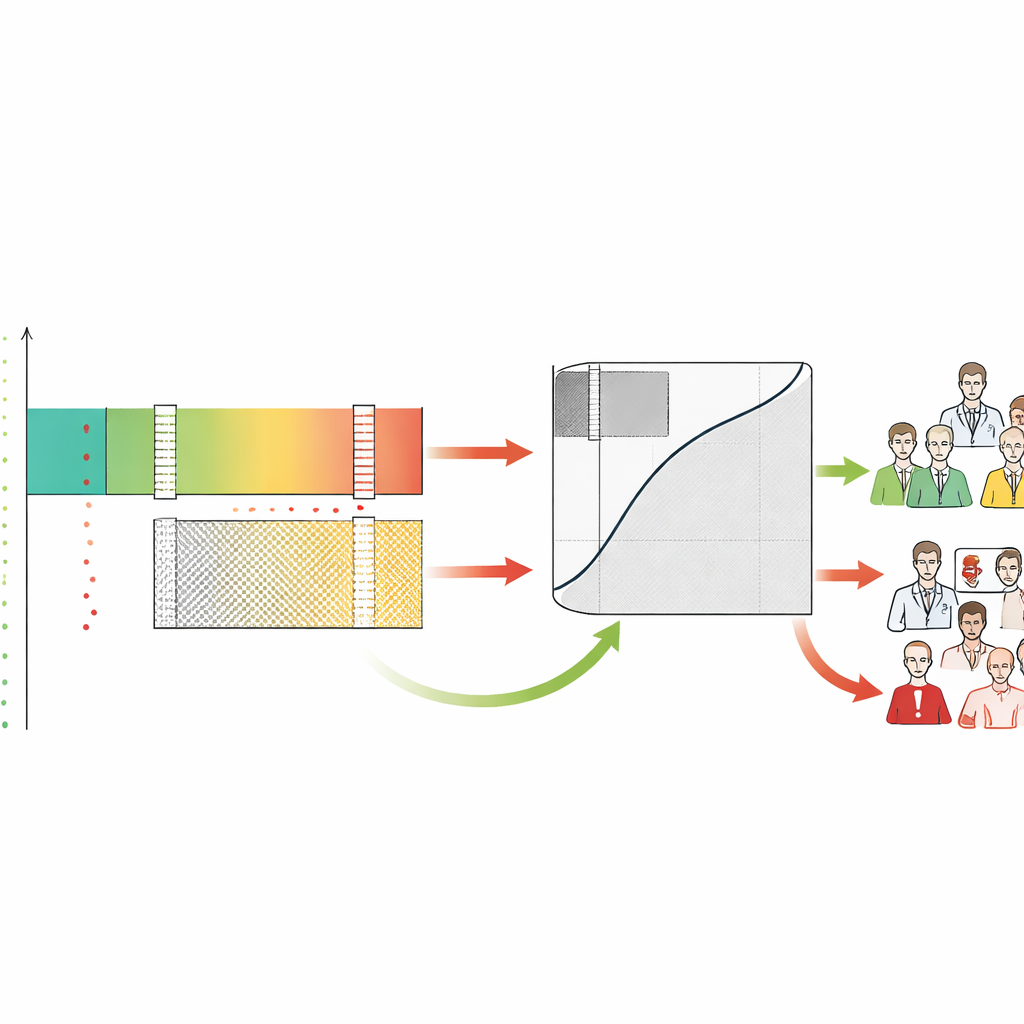
De meeste medische AI-tools geven één risico‑score uit, bijvoorbeeld de kans dat een mammogram kanker toont. Traditioneel beoordelen ontwikkelaars deze tools met een curve die samenvat hoe goed ze zieke van gezonde patiënten onderscheiden in het algemeen. De auteurs stellen dat dat niet genoeg is. Ze stellen het Safety‑Aware ROC (SA‑ROC) raamwerk voor, dat begint met dezelfde risico‑scores maar deze herschikt in drie praktische regio’s. Een hoge‑score “rule‑in” zone bevat patiënten bij wie de uitslag betrouwbaar genoeg is om actie te rechtvaardigen, zoals dringende vervolgdiagnostiek. Een lage‑score “rule‑out” zone bevat patiënten bij wie de uitslag betrouwbaar genoeg is om veilig te de-prioriteren. Tussen beide ligt een “grijze zone” van onzekerheid, waar de AI niet betrouwbaar genoeg is en een menselijke expert de zaak moet beoordelen.
Clinici laten de veiligheidslat bepalen
Cruciaal is dat SA‑ROC clinici en instellingen in staat stelt hun eigen veiligheidstargets vooraf vast te leggen. Ze kiezen hoe zeker ze willen zijn voordat ze op een positief resultaat handelen (de minimaal aanvaardbare kans dat een aangeduid bevinding echt afwijkend is) en hoe zeker ze willen zijn voordat ze bij een negatief resultaat versoepelen (de minimaal aanvaardbare kans dat een vrijgegeven geval echt normaal is). Gegeven deze targets doorzoekt het raamwerk de modelscores om de exacte grenzen te vinden die eraan voldoen. Scores boven de bovenste grens vormen de rule‑in veilige zone, scores onder de onderste grens vormen de rule‑out veilige zone, en alles daartussen wordt de grijze zone. Het raamwerk kwantificeert vervolgens hoeveel patiënten in elke regio vallen en hoeveel onzekere werklast — zaken teruggestuurd naar mensen — de AI onopgelost laat.
Verborgen verschillen tussen ogenschijnlijk vergelijkbare AI’s blootleggen
De auteurs tonen aan dat twee AI‑systemen met vrijwel identieke traditionele nauwkeurigheid zich zeer verschillend kunnen gedragen wanneer ze door deze veiligheidsbril worden bekeken. In simulaties produceerden modellen met dezelfde algemene prestatie heel verschillende groottes van rule‑in, rule‑out en grijze zones, afhankelijk van hoe hun scores verdeeld waren. De ene kon uitblinken in het met hoge zekerheid bevestigen van ziekte, terwijl de andere uitblonk in het veilig vrijgeven van grote aantallen laag‑risico patiënten. In een casestudy in de praktijk van twee door de Amerikaanse Food and Drug Administration goedgekeurde tools voor borstkankerscreening bleek het systeem met de hogere standaard nauwkeurigheidsscore in feite slechter voor screenings met hoge betrouwbaarheid. Bij de strengste veiligheidsinstelling — waarbij geen gemiste kankers in de laag‑risico groep werden toegestaan — verwijderde het ogenschijnlijk zwakkere systeem vrijwel twee keer zoveel vrouwen veilig uit de radioloogwachtrij. SA‑ROC maakt daarmee een soort “prestatiereversie” zichtbaar die conventionele maatstaven verbergt.
Inzicht in spanning tussen mens en AI en werklast
Door elk geval te labelen als rule‑in, rule‑out of grijs onthult het raamwerk ook hoe menselijke artsen zich in deze zones gedragen. De auteurs constateerden dat radiologen vaak gevallen overbepalen die de AI als veilig laag‑risico beoordeelde, waardoor veel vals alarm ontstaat in juist de regio waar de machine het meest betrouwbaar was. Daarentegen hadden zowel mensen als AI moeite in de grijze zone, waarmee deze wordt gevalideerd als het gebied dat echt deskundige aandacht nodig heeft. SA‑ROC vangt de omvang van deze grijze zone in één getal, dat de kosten van besluiteloosheid representeert. Een kleine grijze zone betekent meer veilige automatisering en minder menselijke werklast; een grote grijze zone betekent dat veel gevallen nog steeds zorgvuldige handmatige beoordeling vereisen en dat het systeem eerder kan bijdragen aan uitputting dan het te verlichten.
Veiligheidsregels omzetten in dagelijkse praktijk
Buiten meting is het raamwerk ontworpen als een governance‑instrument dat beleid omzet in concreet AI‑gedrag. Ziekenhuizen kunnen het op twee manieren gebruiken. Ten eerste kunnen ze rechtstreeks veiligheidsvereisten of limieten opgeven voor hoeveel gevallen ze bereid zijn naar de grijze zone te sturen en het raamwerk de bijbehorende drempels laten berekenen. Ten tweede kunnen ze waarden en straffen toekennen aan verschillende uitkomsten — het opsporen van een kanker, het missen ervan, het aanvragen van een onnodig onderzoek, of het uitwijken naar menselijke beoordeling — en het raamwerk laten zoeken naar het beleid dat het totale voordeel maximaliseert. Deze strategieën kunnen worden afgestemd op zeer verschillende doelen, zoals massale screeningsprogramma’s, specialistische verwijzingen of onderzoekspopulaties, allemaal gebruikmakend van hetzelfde onderliggende model.
Wat dit betekent voor patiënten en zorgverleners
Eenvoudig gezegd biedt dit werk een manier om niet alleen te zeggen “deze AI is nauwkeurig”, maar “dit is precies wanneer en hoe hij in de kliniek vertrouwd kan worden”. Door AI‑uitvoer te verdelen in veilige, onveilige en onzekere regio’s die gekoppeld zijn aan expliciete veiligheidsbeloften, helpt SA‑ROC zorginstellingen te beslissen wanneer machines zelfstandig mogen handelen en wanneer mensen duidelijk de controle moeten houden. Het benadrukt dat traditionele nauwkeurigheidsscores misleidend kunnen zijn en dat echte veiligheid afhangt van hoe een model zich gedraagt in de extremen waar fouten het duurst zijn. Als het breed wordt aangenomen en gevalideerd in grotere, reële settings, kan dit raamwerk bijdragen aan betrouwbaardere automatisering, minder onnodige alarmen en onderzoeken, en de moeilijkste AI‑gevallen — de grijze zone — veranderen in een gefocuste bron van leren en verbetering voor zowel algoritmen als de geneeskunde zelf.
Bronvermelding: Kim, YT., Kim, H., Bahl, M. et al. Defining operational safety in clinical artificial intelligence systems. npj Digit. Med. 9, 281 (2026). https://doi.org/10.1038/s41746-026-02450-7
Trefwoorden: klinische kunstmatige intelligentie, operationele veiligheid, medische beeldvorming, beslissingsondersteuning, risicostratificatie