Clear Sky Science · nl
Anatomie-gestuurde visual prompt tuning voor cross-modale borstkankerbegrip
Slimmer screenen voor een veelvoorkomende kanker
Borstkanker is een van de belangrijkste oorzaken van kankerdood bij vrouwen, en artsen vertrouwen steeds vaker op computerprogramma’s om complexe medische beelden te helpen lezen. Maar mammogrammen, echografie en MRI tonen de borst op sterk verschillende manieren, wat het moeilijk maakt voor huidige kunstmatige-intelligentiesystemen om betrouwbaar te blijven over verschillende apparaten en ziekenhuizen heen. Deze studie introduceert een nieuwe AI-benadering die rekening houdt met de onderliggende borstanatomie in plaats van alleen met helderheidspatronen in elk beeld, wat leidt tot nauwkeurigere en consistentere detectie van verdachte gebieden.
Waarom verschillende scans computers in verwarring brengen
Mammografie, echografie en MRI gebruiken elk verschillende fysische principes om in de borst te kijken. Een tumor die op een echo als een helder korreltje verschijnt, kan op een mammogram als een subtiele schaduw of op MRI als een oplichtend gebied zichtbaar zijn. Veel moderne AI-systemen, inclusief krachtige vision transformers en vision–language-modellen, leren voornamelijk van het algemene uiterlijk van beelden. Ze missen vaak kleine maar belangrijke details zoals microcalcificaties of onregelmatige randen, en hun prestaties kunnen sterk dalen wanneer ze van het ene type scanner of ziekenhuis naar het andere worden overgedragen. Deze kloof tussen trainingsomstandigheden en de klinische praktijk beperkt het vertrouwen dat artsen in dergelijke hulpmiddelen kunnen stellen.
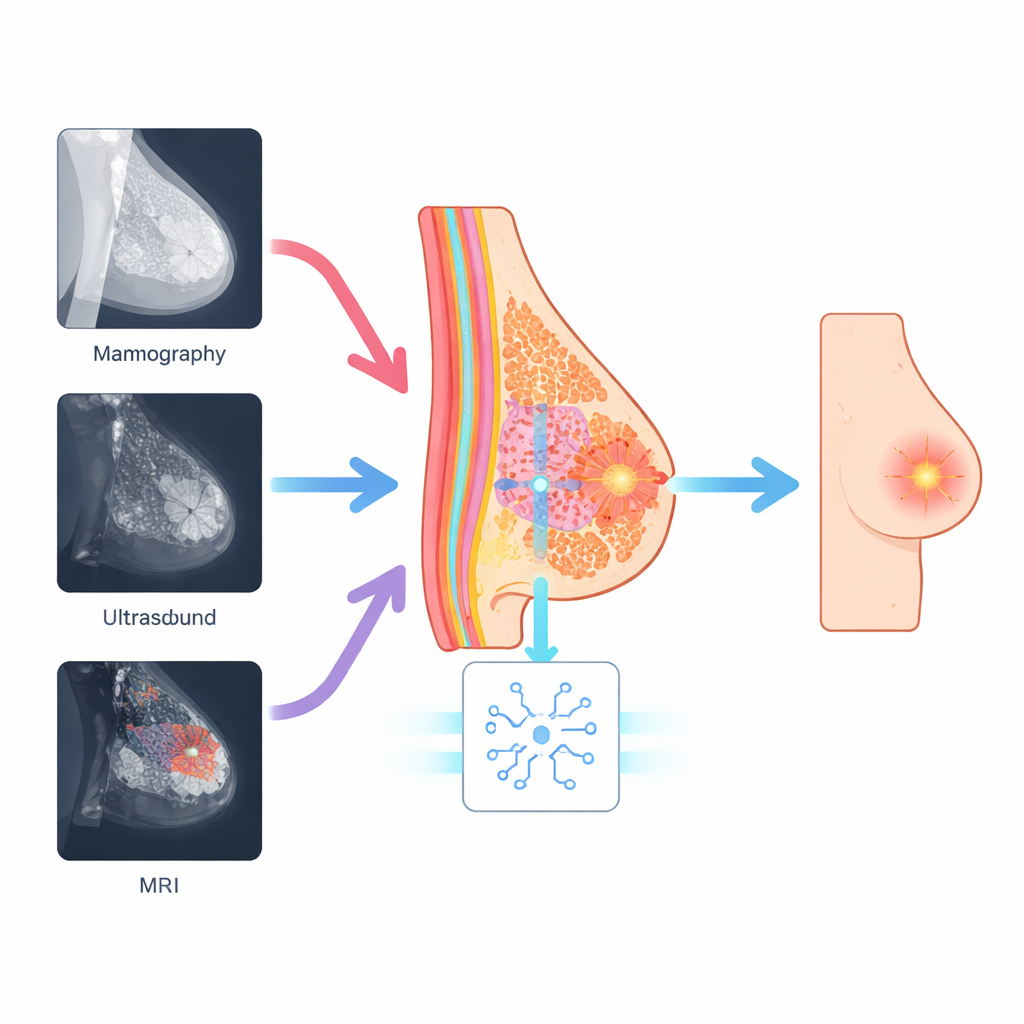
De borst zelf als leidraad gebruiken
De onderzoekers stellen dat, hoewel de beelden er anders uitzien, de daadwerkelijke biologie van de borst tussen scans niet verandert. Elk beeld bevat nog steeds klierweefsel, vet en ductale structuren die in een herkenbaar patroon gerangschikt zijn. Hun methode, Anatomy-Guided Visual Prompt Tuning (A-VPT), bouwt deze basale kaart van de borst rechtstreeks in het AI-model. In plaats van miljoenen interne gewichten aan te passen, voegt het systeem een kleine set extra "prompt"-signalen toe die het netwerk vertellen welke weefselregio’s het bekijkt. Deze prompts worden gegenereerd uit grove anatomische kaarten of geleerd weefselcues en vervolgens laag voor laag geïnjecteerd in een bevroren, voorgetrainde transformer. In feite wordt het model continu herinnerd waar de ducts, klieren en vet liggen, zodat het verdachte gebieden in de juiste context kan beoordelen.
Één systeem leren spreken van vele beeldvormings"talen"
Om het model over beeldvormingstypen heen te laten werken, ontwierp het team een trainingsschema dat de AI dwingt vergelijkbare weefsels op dezelfde manier te behandelen, ongeacht hoe ze gescand zijn. Ze brengen de interne vingerafdrukken van vet-, klier- en ductale regio’s uit mammografie, echografie en MRI op elkaar af, en duwen deze naar een gedeelde representatieruimte. Waar tekstverslagen beschikbaar zijn, koppelt het systeem deze weefselpatronen ook aan korte beschrijvende zinnen, waardoor visuele kenmerken aan medische taal worden verbonden. Tijdens de verwerking laten gespecialiseerde interactiemodules de anatomie-prompts en de beeldkenmerken informatie in beide richtingen uitwisselen, met een gating-stap die regelt hoe sterk de anatomie elke laag beïnvloedt. Deze combinatie helpt het model zich op de juiste structuren te concentreren terwijl het stabiel en efficiënt blijft.
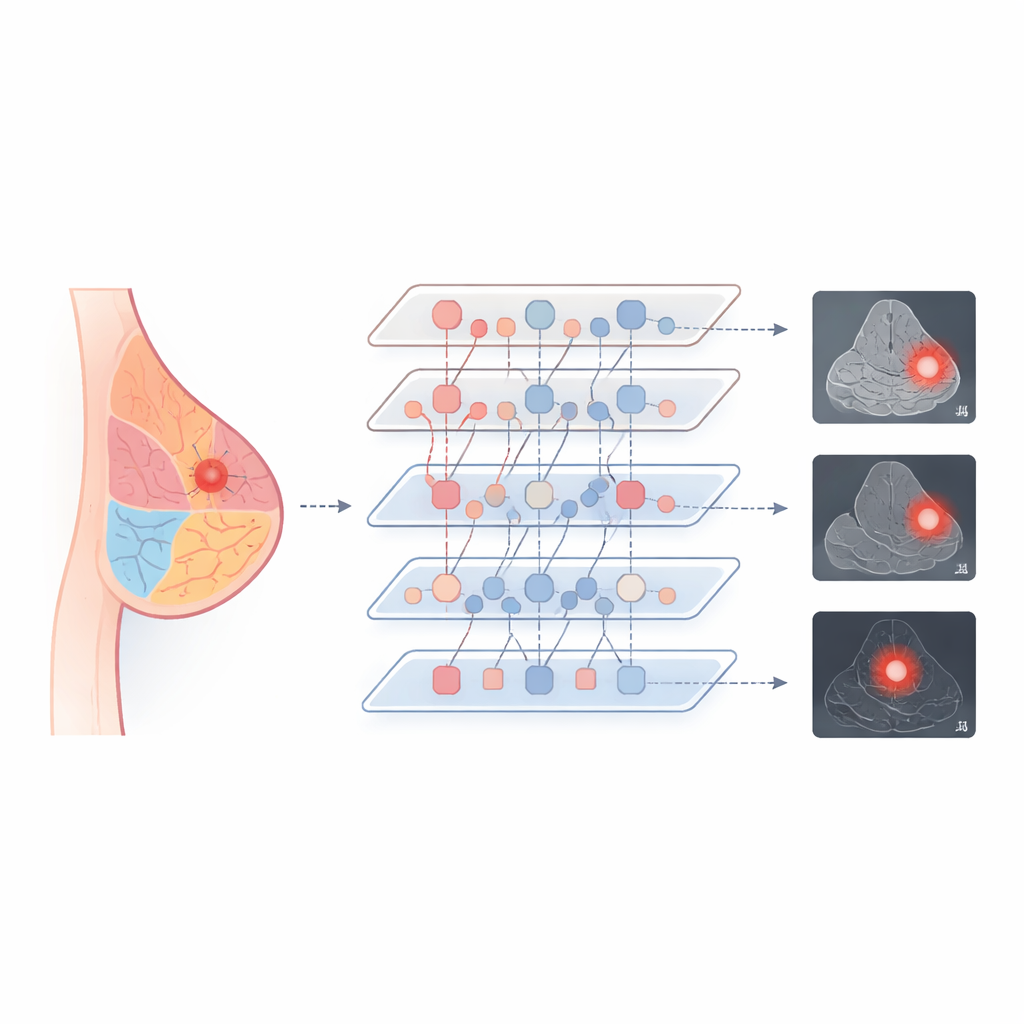
Betere nauwkeurigheid met een lichtere aanpak
De auteurs testten A-VPT op drie bekende borstbeeldverzamelingen die alle drie modaliteiten omvatten. In vergelijking met traditionele diepe netwerken en verschillende gangbare manieren om grote modellen fijn af te stemmen, behaalde hun methode de hoogste scores voor zowel het classificeren van laesies als goedaardig of kwaadaardig en het afbakenen van hun grenzen. Het presteerde bijzonder goed wanneer het werd gevraagd kennis van het ene scantype te gebruiken om het andere te interpreteren — bijvoorbeeld trainen op mammogrammen en vervolgens evalueren op echografie — waar oudere methoden vaak struikelden. Opvallend genoeg bereikte A-VPT deze resultaten terwijl minder dan 2% van de modelparameters werd bijgewerkt, wat de rekenbelasting vermindert en het eenvoudiger maakt om in echte ziekenhuizen te implementeren. Visualisaties van waar het model "keek" toonden aan dat het zich concentreerde op realistische klier- en peritumorele regio’s, wat suggereert dat de beslissingen overeenkomen met het redeneren van radiologen.
Wat dit betekent voor patiënten en klinieken
In eenvoudige bewoordingen laat dit werk zien dat het aanleren van basisanatomie aan AI-systemen ze zowel slimmer als beter begrijpelijk kan maken. Door het redeneren te verankeren in de werkelijke structuur van de borst, is A-VPT beter in het opsporen en afbakenen van tumoren over verschillende beeldvormingsmethoden, met minder aanpassingen en meer transparant gedrag. Als dit verder wordt gevalideerd, kan deze strategie consistentere screening en diagnose ondersteunen in uiteenlopende omgevingen, van grote medische centra tot kleinere klinieken, en kan ze worden uitgebreid naar andere organen zoals long of lever. Uiteindelijk kan anatomie-bewuste AI een sleutelpartner worden bij eerder en betrouwbaarder kankeropsporing.
Bronvermelding: Zhao, S., Meng, Q., He, Y. et al. Anatomy-guided visual prompt tuning for cross-modal breast cancer understanding. npj Digit. Med. 9, 240 (2026). https://doi.org/10.1038/s41746-026-02417-8
Trefwoorden: borstkankerbeeldvorming, medische AI, vision transformers, cross-modale leren, anatomie-gestuurde prompts