Clear Sky Science · nl
Machine learning-modellen voor voorspelling van geneesmiddel-geneesmiddelinteracties: van computationele ontdekking tot klinische toepassing
Waarom het combineren van medicijnen risico’s kan geven
De moderne geneeskunde berust vaak op het gelijktijdig innemen van meerdere geneesmiddelen—voor kanker, hartziekten, infecties of gewoon om de vele aandoeningen die met ouderdom komen te beheersen. Maar wanneer medicijnen elkaar in het lichaam ontmoeten, kunnen ze elkaars effecten veranderen, soms waardoor de behandeling minder effectief wordt of zelfs gevaarlijk. Deze review onderzoekt hoe kunstmatige intelligentie, met name moderne machine-learningmethoden, wordt gebruikt om deze geneesmiddel–geneesmiddelinteracties vooraf te voorspellen, zodat artsen veiligere combinaties kunnen kiezen en behandelingen kunnen afstemmen op individuele patiënten.
Van trial-and-error naar datagestuurde veiligheid
Traditioneel werden problematische geneesmiddelcombinaties op de harde manier ontdekt—tijdens late fase klinische onderzoeken of nadat een middel al op de markt was en patiënten schade ondervonden. Laboratoriumtesten op cellen, dieren en vrijwilligers blijven de gouden standaard, maar ze zijn traag, duur en onuitvoerbaar voor het enorme aantal mogelijke geneesmiddelparen. De auteurs bepleiten dat computationele voorspelling uit deze knelpositie kan helpen. Door te leren van enorme digitale verzamelingen met geneesmiddelinformatie—zoals chemische structuren, doelwitten in het lichaam, bekende bijwerkingen en meldingen uit de praktijk—kunnen machine-learningsystemen risicovolle paren signaleren lang voordat ze veel patiënten bereiken.
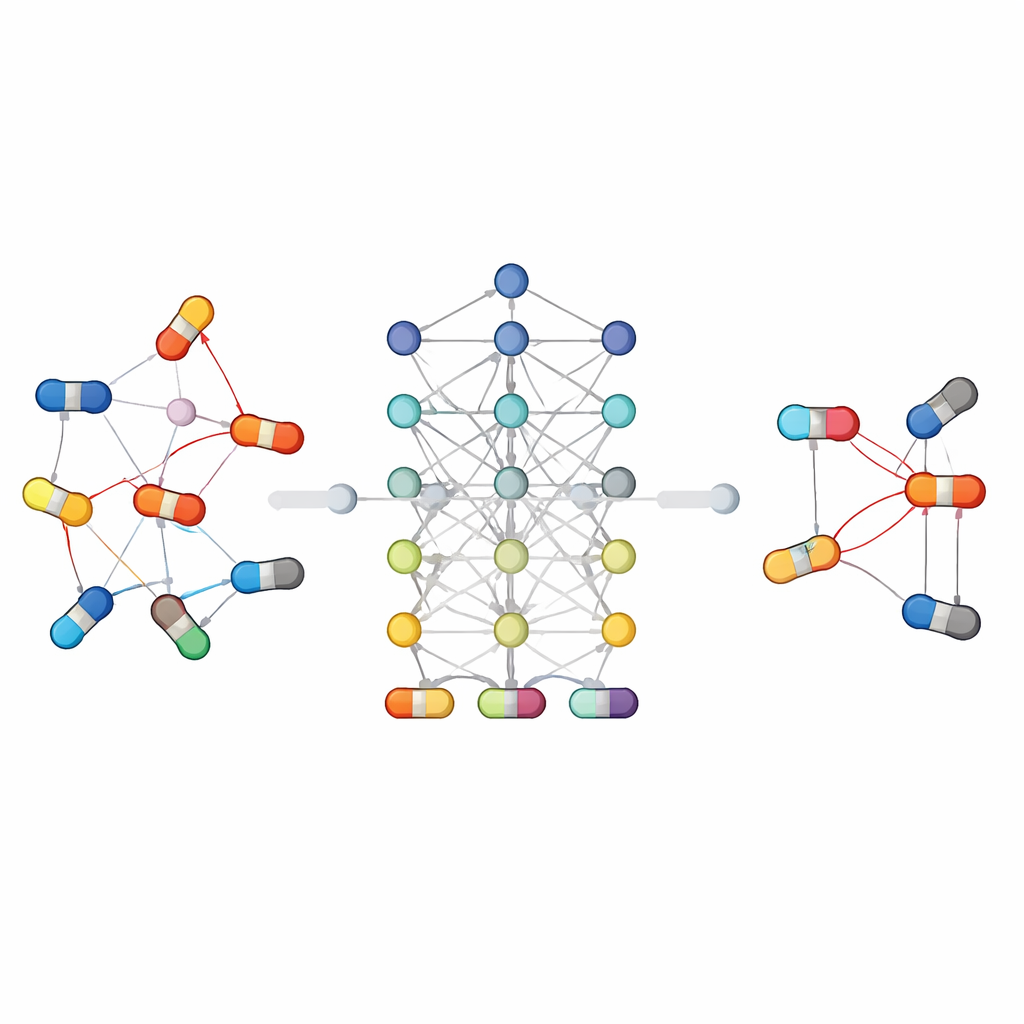
Hoe machines leren van verschillende soorten geneesmiddelinformatie
De review legt een veelgebruikte workflow uit voor deze voorspellingssystemen. Eerst wordt informatie verzameld uit grote biomedische databanken: chemische bibliotheken die beschrijven hoe elke molecule eruitziet, routekaarten die laten zien hoe geneesmiddelen in het lichaam worden verwerkt, en gecureerde lijsten van bekende interacties en bijwerkingen. Vervolgens zetten algoritmen deze ruwe informatie om in numerieke patronen die computers kunnen begrijpen—bijvoorbeeld door te meten hoe vergelijkbaar twee geneesmiddelen zijn, of door elk geneesmiddel te representeren als een knoop in een netwerk die verbonden is met zijn doelwitten, routes en eerdere reacties. Verschillende machine-learningmodellen worden daarna getraind om te herkennen welke paren problemen veroorzaken, en hun prestaties worden gecontroleerd aan de hand van benchmarkdatasets met standaard nauwkeurigheidsmaten.
Verschillende algoritmegroepen pakken het probleem op hun eigen manier aan
Omdat geneesmiddelinteracties complex zijn, is geen enkel modeltype in alle situaties het beste. Sommige benaderingen vertrouwen op traditionele classifiers die werken met handgemaakte kenmerken, terwijl andere rechtstreeks leren van de structuur van moleculen of het netwerk van verbindingen tussen geneesmiddelen en biologische entiteiten. Grafgebaseerde en deep-learningmethoden zijn bijzonder succesvol geweest: ze behandelen geneesmiddelen en hun relaties als een netwerk, waardoor het algoritme kan "redeneren" over ketens van verbindingen die voor eenvoudigere modellen onzichtbaar blijven. Andere strategieën delen informatie over verwante taken, zoals zowel voorspellen of twee geneesmiddelen interacteren als welk soort effect ze veroorzaken, wat helpt wanneer data schaars zijn. Het artikel belicht ook nieuwe richtingen zoals grote taalmodellen die wetenschappelijke teksten en klinische aantekeningen lezen, en generatieve modellen die mogelijke interactiepatronen verkennen in zeer grote, schaars gevulde datasets.
Computer-voorspellingen koppelen aan echte patiënten
Voorbij de methoden benadrukt het artikel hoe deze hulpmiddelen de zorg in de echte wereld kunnen ondersteunen. De auteurs bespreken hoe modellen die getraind zijn op gecureerde databanken en klinische dossiers clinici aan het bed kunnen waarschuwen voor gevaarlijke combinaties, kunnen helpen bij het ontwerpen van veiligere multidrug-regimes in oncologie, cardiologie en infectieziekten, en kunnen prioriteren welke voorspelde interacties laboratoriumtesten verdienen. Ze behandelen ook klassieke klinische voorbeelden—zoals antibiotica die de niveaus van cholesterolverlagende middelen veranderen, pijnstillers die elkaars werking blokkeren, of vruchtensappen die onverwacht de geneesmiddelconcentraties verhogen—om de vele paden te tonen waarlangs interacties ontstaan. Machine-learningsystemen die deze patronen vastleggen, kunnen zo fungeren als vroegtijdige waarschuwingssystemen, vooral bij oudere patiënten die veel medicijnen gebruiken.
Uitdagingen op weg naar betrouwbare AI voor medicijnen
Ondanks indrukwekkende nauwkeurigheid op testdatasets benadrukken de auteurs dat huidige modellen nog belangrijke hobbels tegenkomen voordat ze breed in klinieken vertrouwd kunnen worden. Veel modellen zijn "black boxes" die weinig inzicht geven waarom een specifiek paar als risicovol wordt beoordeeld, wat het moeilijk maakt voor artsen om de aanbeveling te evalueren of uit te leggen. Modellen kunnen struikelen wanneer data ruisig of onevenwichtig zijn—bijvoorbeeld wanneer schadelijke interacties zeldzaam zijn vergeleken met veilige paren. Het integreren van informatie over chemie, genetica, elektronische patiëntendossiers en gepubliceerde literatuur is technisch uitdagend, en regelgevende kaders vereisen sterk bewijs voordat dergelijke hulpmiddelen voorschrijfbeslissingen kunnen beïnvloeden. Toekomstig werk, zo betogen de auteurs, moet zich richten op beter interpreteerbare modellen, verbeterde omgang met bevooroordeelde en onvolledige data, en systemen die continu kunnen leren van nieuwe klinische ervaring met respect voor privacy- en veiligheidsregels.
Wat dit betekent voor de dagelijkse behandeling
Kort gezegd laat deze review zien dat kunstmatige intelligentie een krachtige bondgenoot wordt bij het veilig houden van medicijncombinaties. Door bergen digitale data te doorzoeken die veel verder reiken dan wat een menselijk expert kan overzien, kunnen machine-learningmodellen gevaarlijke paren belichten, veiligere alternatieven voorstellen en meer gepersonaliseerde voorschriften ondersteunen. Deze hulpmiddelen zullen het klinische oordeel of zorgvuldig laboratoriumonderzoek niet vervangen, maar ze kunnen helpen ervoor te zorgen dat de toenemende complexiteit van moderne therapie niet ten koste gaat van de veiligheid van patiënten.
Bronvermelding: Lu, Y., Chen, J., Fan, N. et al. Machine learning models for drug-drug interaction prediction from computational discovery to clinical application. npj Digit. Med. 9, 198 (2026). https://doi.org/10.1038/s41746-026-02400-3
Trefwoorden: geneesmiddel–geneesmiddelinteracties, machine learning in de geneeskunde, graph neural networks, klinische farmacologie, veiligheid van kunstmatige intelligentie