Clear Sky Science · nl
Evaluatie van grote taalmodellen voor het genereren van diagnostische conclusies uit bevindingen van hersen-MRI-rapporten: een multicenter benchmark en lezersonderzoek
Waarom slimme MRI-rapporten ertoe doen voor patiënten
Als u een hersenscan krijgt, moet een radioloog duizenden grijstinten omzetten in een duidelijke uitspraak over wat er mis is — of dat alles normaal lijkt. Deze uiteindelijke “conclusie” stuurt cruciale beslissingen over bijvoorbeeld beroertezorg, hersentumoren en infecties. Maar het lezen van hersen-MRI’s is complex en tijdrovend, en overbelaste artsen kunnen fouten maken, vooral in drukke ziekenhuizen. Deze studie onderzoekt of geavanceerde taalmodellen voor kunstmatige intelligentie radiologen betrouwbaar kunnen helpen om geschreven MRI-bevindingen snel, consistent en nauwkeurig om te zetten in diagnostische conclusies.
Van ruwe scanbeschrijvingen naar duidelijke antwoorden
Hersen-MRI’s leveren een reeks beelden op die radiologen beschrijven in een schriftelijke sectie met “bevindingen”, waarin ze zaken noteren zoals waar een laesie zich bevindt, hoe helder het lijkt en of er zwelling is. De echte uitdaging is daarna al die details te combineren tot een diagnostische conclusie, zoals “acuut infarct” of “hersenabces”. De onderzoekers verzamelden 4293 hersen-MRI-rapporten uit drie ziekenhuizen in China, met 16 diagnostische categorieën die meer dan 95% van de dagelijkse hersenaandoeningen beslaan. Ze testten vervolgens 10 verschillende grote taalmodellen — geavanceerde op tekst gebaseerde AI-systemen — om te zien hoe goed elk model de geschreven bevindingen in de juiste diagnoses kon omzetten.
Grote, goed getrainde AI-modellen kwamen als beste uit de bus
Het team vergeleek modellen met ongeveer 8 miljard tot 671 miljard interne parameters, ruwweg vergelijkbaar met de stap van een geneeskundestudent naar een deskundig team. Het grootste model, DeepSeek‑R1, leverde consequent de beste prestaties wanneer het zowel gestructureerde versies van de bevindingen als belangrijke klinische informatie zoals leeftijd, symptomen of trauma-geschiedenis kreeg. Onder deze omstandigheden identificeerde DeepSeek‑R1 het aanwezig zijn of ontbreken van specifieke hersenaandoeningen met hoge sensitiviteit en specificiteit, en behaalde het een patiëntniveau-nauwkeurigheid van meer dan 87%. Kleinere modellen, vooral die onder de 10 miljard parameters, presteerden slecht en haalden vaak slechts ongeveer 30% correcte classificaties — ver onder wat in de klinische praktijk acceptabel zou zijn.
Waarom structuur en context AI slimmer maken
De onderzoekers voerden de modellen niet alleen ongestructureerde tekst toe. Ze gebruikten ook een ander AI-systeem om de rapporten te herstructureren in duidelijke, gestandaardiseerde elementen: waar elke laesie zat, hoeveel er waren en hoe ze eruitzagen op verschillende MRI-sequenties. Het toevoegen van deze structuur, gecombineerd met korte klinische aantekeningen, maakte een opvallend verschil. Voor DeepSeek‑R1 verbeterde de overgang van ruwe vrije-tekstbevindingen naar gestructureerde bevindingen plus klinische context de sensitiviteit, de algemene nauwkeurigheid en samenvattende prestatiemaatstaven. Simpel gezegd presteerde de AI veel beter wanneer hij schonere, beter georganiseerde informatie en wat patiëntachtergrond kreeg — wat overeenkomt met hoe menselijke radiologen het beste werken als rapporten overzichtelijk zijn en de klinische vraag duidelijk is.
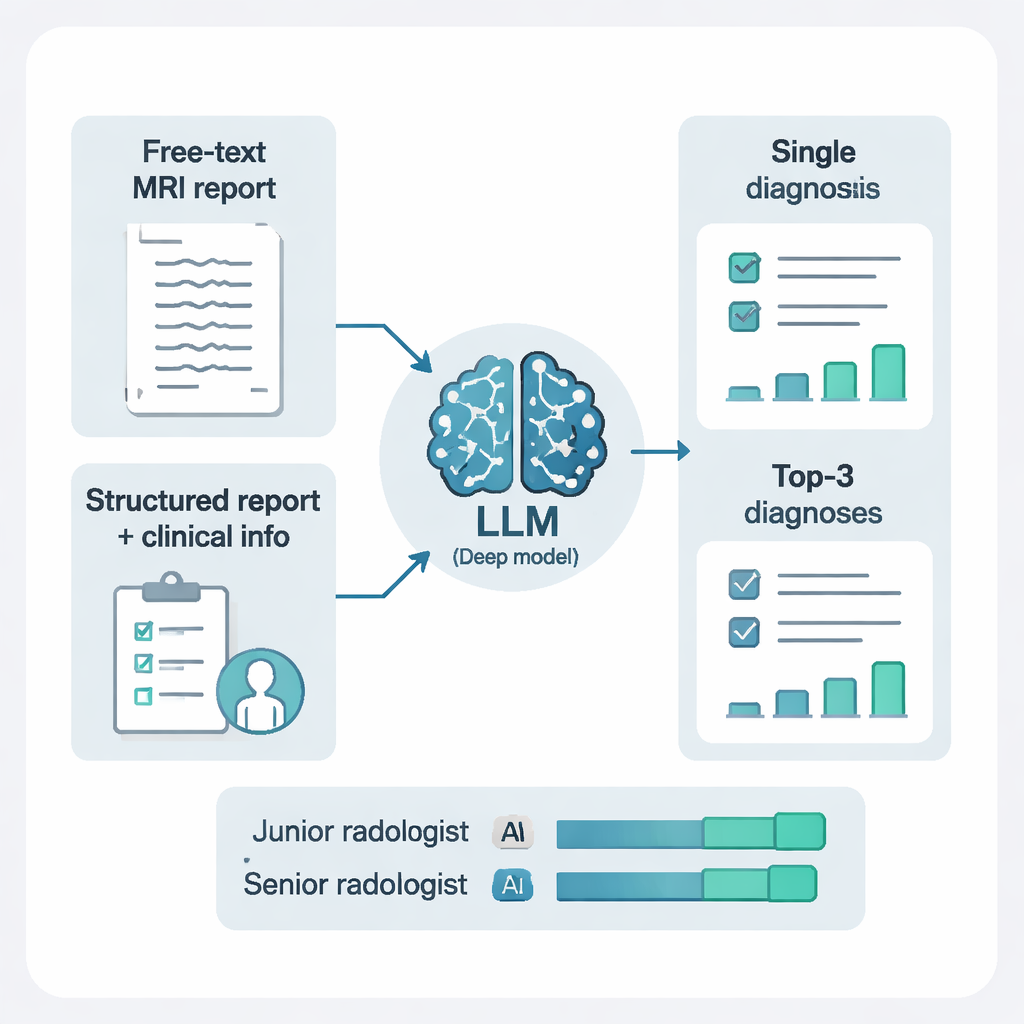
Van één gok naar een gerangschikte korte lijst
In de praktijk geven radiologen bij lastige gevallen vaak meer dan één mogelijke diagnose. De studie testte twee promptstijlen: de AI vragen om slechts één diagnose, of om de drie belangrijkste mogelijkheden, elk met een korte verklaring. Het toestaan van drie gerangschikte diagnoses verbeterde de prestaties aanzienlijk. Met deze “differentiaaldiagnose”-benadering stond het juiste antwoord in meer dan 97% van de patiënten ergens in de top drie suggesties. Dit was vooral nuttig bij complexe gevallen zoals tumoren, bloedingen of inflammatoire aandoeningen, waarbij één geforceerde gok misleidend kan zijn, terwijl een korte, gefundeerde lijst effectief kan sturen bij verder onderzoek en behandeling.
Impact in de echte wereld voor drukbezette radiologen
Om te onderzoeken of deze verbeteringen in de praktijk relevant zijn, voerden de auteurs een lezersonderzoek uit met zes radiologen — drie junioren en drie senioren — die 500 hersen-MRI-rapporten interpreteerden met en zonder hulp van DeepSeek‑R1. Met AI-assistentie steeg de algehele diagnostische nauwkeurigheid van ongeveer driekwart van de gevallen naar meer dan 90%, en een belangrijke kwaliteitsmaat voor precisie en recall verbeterde ook substantieel. De leestijd daalde eveneens, van ongeveer een minuut per casus naar minder dan een minuut, wat voor elke radioloog per jaar tientallen uren kan schelen. De grootste voordelen waren zichtbaar bij junior radiologen, wier prestaties dichter bij die van ervaren experts kwamen, hoewel de studie ook benadrukte dat artsen voorzichtig moeten blijven en AI niet blindelings moeten vertrouwen, vooral bij zeer subtiele aandoeningen zoals bepaalde soorten hersenbloedingen.
Wat dit betekent voor toekomstige hersenscanrapporten
Voor patiënten is de belangrijkste conclusie dat krachtige, op taal gebaseerde AI-systemen radiologen al kunnen helpen om complexe MRI-beschrijvingen om te zetten in duidelijkere, meer nauwkeurige diagnostische conclusies, vooral wanneer ze goed gestructureerde informatie en essentiële klinische details krijgen. Deze hulpmiddelen vervangen menselijke expertise niet, maar kunnen fungeren als een tweede paar zorgvuldige ogen, met goed onderbouwde suggesties en tijdsbesparing. Als ze breder gevalideerd en veilig in ziekenhuissystemen geïntegreerd worden, kan dergelijke AI-ondersteuning hersenscanrapporten sneller, betrouwbaarder en consistenter maken — wat uiteindelijk de zorg voor mensen met beroertes, tumoren, infecties en vele andere hersenaandoeningen kan verbeteren.
Bronvermelding: Wang, ML., Zhang, RP., Wu, WJ. et al. Evaluation of large language models for diagnostic impression generation from brain MRI report findings: a multicenter benchmark and reader study. npj Digit. Med. 9, 187 (2026). https://doi.org/10.1038/s41746-026-02380-4
Trefwoorden: hersenen MRI-diagnose, radiologie kunstmatige intelligentie, grote taalmodellen, klinische besluitvorming ondersteuning, DeepSeek-R1