Clear Sky Science · nl
Grote taalmodellen verbeteren de overdraagbaarheid van voorspellingen op basis van elektronische patiëntendossiers tussen landen en codesystemen
Waarom slimmer delen van medische gegevens belangrijk is
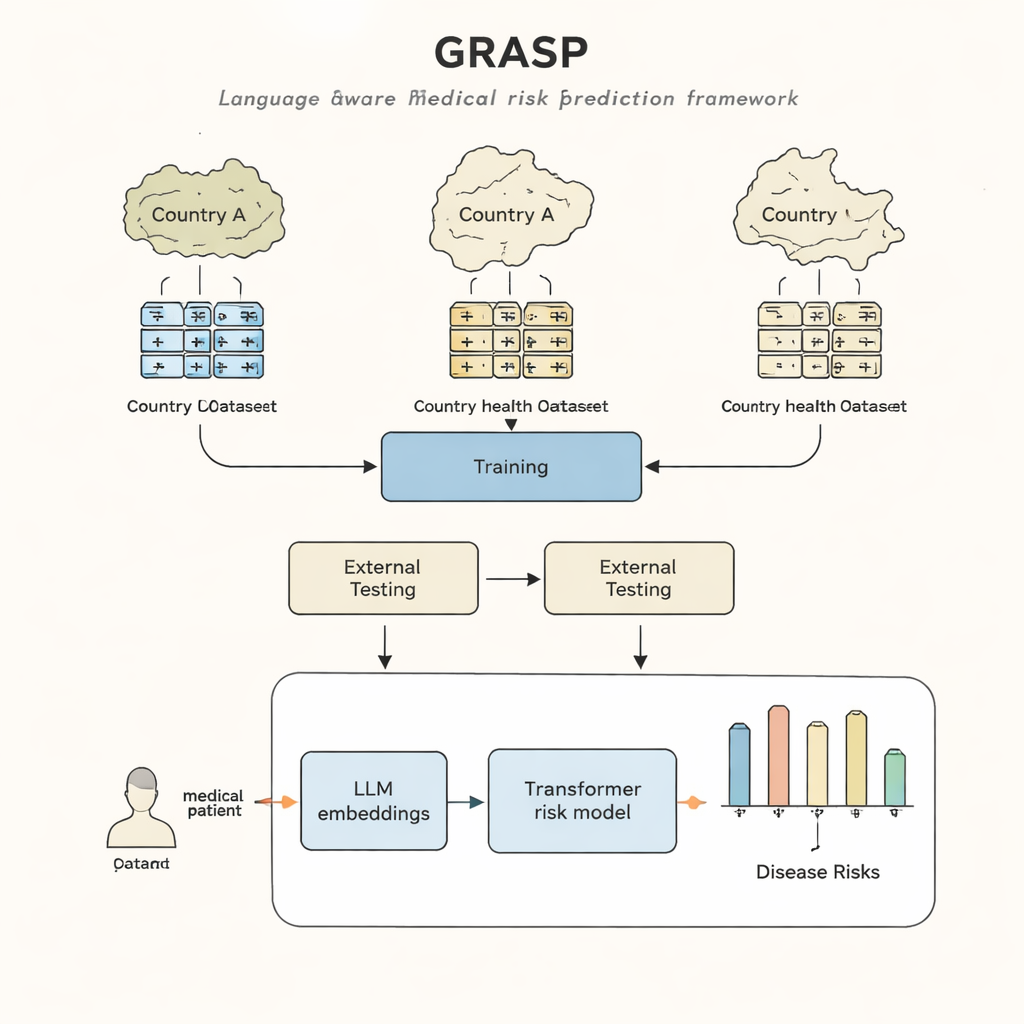
Ziekenhuizen en klinieken wereldwijd zitten op een goudmijn aan informatie: elektronische patiëntendossiers die diagnoses, behandelingen en uitkomsten van mensen over vele jaren vastleggen. In theorie kan deze informatie artsen helpen vroeg te signaleren wie een hoog risico loopt op ernstige ziekten, lang voordat symptomen duidelijk worden. In de praktijk hebben de huidige computermodellen echter moeite om “mee te reizen” van het ene land of zorgsysteem naar het andere, omdat elk systeem gezondheidsgegevens anders vastlegt. Deze studie introduceert een nieuwe benadering, genaamd GRASP, die gebruikmaakt van recente doorbraken in kunstmatige intelligentie om deze kloof te overbruggen, zodat een model dat in één zorgsysteem is getraind betrouwbaar kan werken in andere.
Verschillende ziekenhuizen, verschillende talen
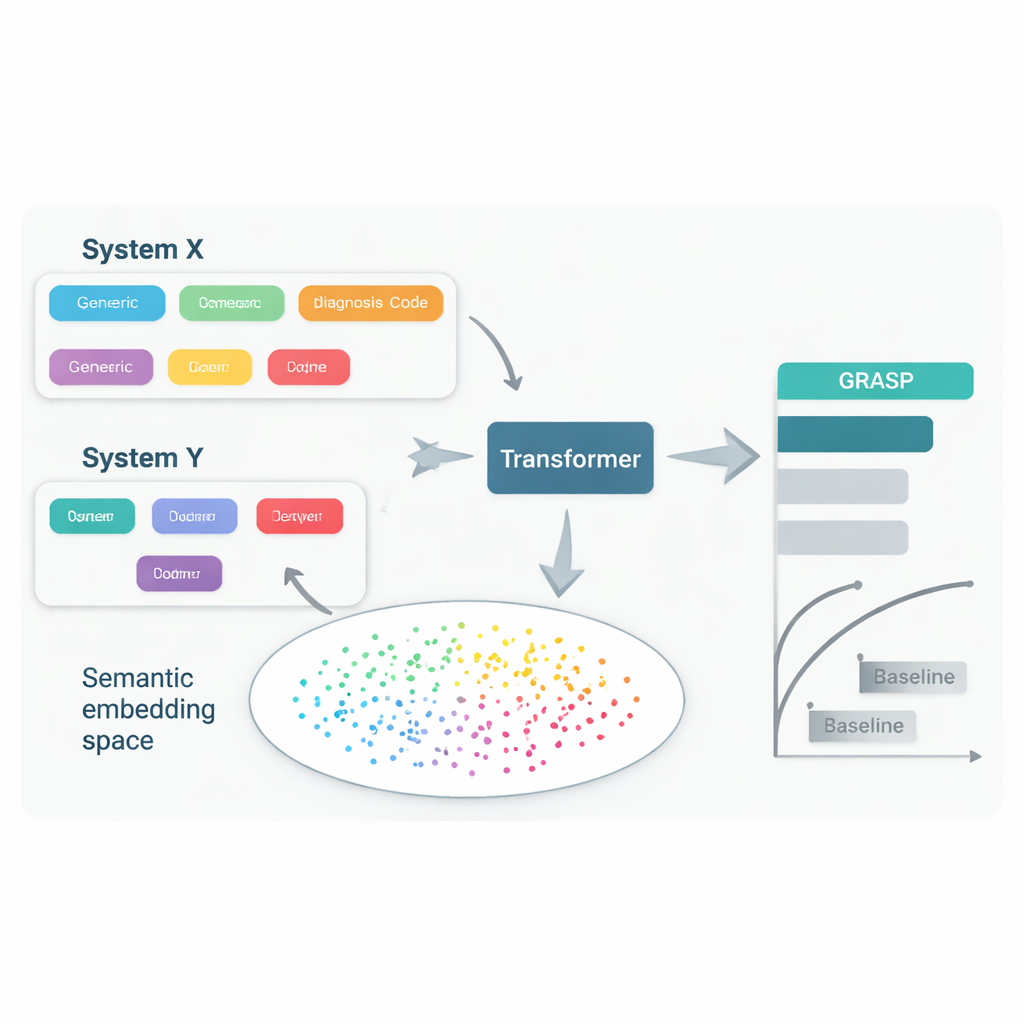
Zelfs wanneer artsen dezelfde ziekte behandelen, gebruiken zij vaak verschillende codesystemen en lokale gewoonten om dit in het medisch dossier vast te leggen. Het ene ziekenhuis kan “hoge bloedsuiker” onder één code opslaan, terwijl een ander een andere code voor “hyperglykemie” gebruikt en een derde een geheel ander systeem hanteert. Pogingen om iedereen naar één gemeenschappelijke standaard te dwingen—zoals grote internationale codeschema’s—zijn nuttig maar traag, duur en laten nog steeds belangrijke verschillen bestaan. Hierdoor kan een computermodel dat ziekte voorspelt op basis van dossiers in het ene land aan nauwkeurigheid verliezen wanneer het elders wordt toegepast, waardoor wie van deze hulpmiddelen kan profiteren beperkt wordt.
AI laten lezen wat het betekent, niet alleen de code
De GRASP-benadering begint bij een eenvoudig idee: in plaats van elke medische code als een betekenisloos ID-nummer te behandelen, laat je een groot taalmodel de menselijke beschrijving erachter lezen, zoals “acute bovenste luchtweginfectie,” en die betekenis omzetten in een numerieke "embedding". Deze embeddings plaatsen gerelateerde concepten dicht bij elkaar in een gedeelde ruimte, zelfs als ze uit verschillende codesystemen of landen komen. GRASP berekent dergelijke embeddings vooraf voor miljoenen standaard medische termen en slaat ze op in een naslagtabel. De medische geschiedenis van een patiënt wordt vervolgens weergegeven als een reeks van deze rijke vectoren, die worden gevoed in een transformer-netwerk—een type neuraal netwerk dat goed geschikt is om verzamelingen van diverse invoer te verwerken—om het risico van die persoon op 21 belangrijke ziekten plus het algemene sterfterisico te schatten.
Testen over landen en dossiersystemen heen
De onderzoekers trainden GRASP met gegevens van bijna 400.000 deelnemers uit de UK Biobank en testten het vervolgens zonder opnieuw te trainen in twee zeer verschillende omgevingen: het FinnGen-project in Finland en een groot ziekenhuissysteem in New York City. GRASP evenaarde of overtrof sterke alternatieven, waaronder een populaire methode genaamd XGBoost en een vergelijkbare transformer die geen taalgebaseerde embeddings gebruikte. In Finland presteerde GRASP bijzonder goed, met duidelijke verbeteringen voor aandoeningen zoals astma, chronische nierziekte en hartfalen. Opmerkelijk genoeg leverde GRASP zelfs betere voorspellingen dan alleen demografische gegevens toen de Amerikaanse ziekenhuisdata in een ander codesysteem werden gelaten in plaats van naar een gedeelde standaard te worden geconverteerd, omdat het codes puur kon afstemmen door de woordkeuze in hun beschrijvingen te begrijpen.
Meer halen uit minder data
Een ander voordeel van GRASP is efficiëntie. Omdat het taalmodel al heeft geleerd dat veel medische concepten gerelateerd zijn, hoeft het voorspellende netwerk deze verbanden niet opnieuw helemaal te ontdekken. Toen de auteurs GRASP trainden op veel kleinere subsets van de Britse data—tot slechts 10.000 mensen—presteerde het nog steeds beter dan concurrerende modellen die op dezelfde beperkte steekproeven waren getraind, zowel in het VK als bij overdracht naar andere landen. De risicoscores van GRASP waren ook beter in lijn met de geërfde genetische risico’s voor meerdere ziekten, wat suggereert dat het diepere aspecten van vatbaarheid voor ziekten vastlegt in plaats van alleen patronen in één dataset te memoriseren.
Wat dit betekent voor toekomstige zorg
Voor niet-specialisten is de kernboodschap dat GRASP laat zien hoe moderne, taalgebaseerde AI verschillende zorgsystemen kan helpen "dezelfde taal te spreken" zonder ze te dwingen in één star codeschema. Door de betekenis van medische termen te lezen, kan GRASP ziektesindicaties genereren die beter generaliseren over landen en dossierformaten, en dat met minder patiëntvoorbeelden. Hoewel de methode nog zorgvuldige tests, herkalibratie en controles op eerlijkheid nodig heeft voordat ze in de dagelijkse zorg wordt gebruikt, wijst ze op een toekomst waarin krachtige risicohulpmiddelen die op één plek zijn ontwikkeld veilig en efficiënt kunnen worden gedeeld met ziekenhuizen en klinieken wereldwijd.
Bronvermelding: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
Trefwoorden: elektronische patiëntendossiers, ziekterisicovoorspelling, grote taalmodellen, deling van medische gegevens, AI in de gezondheidszorg