Clear Sky Science · nl
Op weg naar een spraakgebaseerde digitale biomarker voor cognitieve achteruitgang: spraak als proxy voor cognitieve beoordeling
Waarom alledaagse gesprekken iets over de hersengezondheid kunnen zeggen
De meesten van ons zien het als vanzelfsprekend om met vrienden te praten of een afbeelding te beschrijven. Maar naarmate we ouder worden, kunnen subtiele veranderingen in woordkeuze, zinsopbouw en pauzes tussen zinnen aanwijzingen geven over hoe goed ons brein functioneert. Deze studie stelt een eenvoudige maar krachtige vraag: kan een korte opname van gewone spraak, thuis gemaakt met een laptop, fungeren als een vroeg waarschuwingssignaal voor problemen zoals dementie — zonder langdurige kliniekbezoeken of pen‑en‑papier‑testen?

Luisteren in plaats van langdurig testen
Vandaag de dag hangt de diagnose van cognitieve achteruitgang meestal af van persoonsgebonden tests door specialisten. Deze sessies zijn tijdrovend, duur en moeilijk vaak of op grote schaal te herhalen. Tegelijk lopen miljoenen ouderen risico op aandoeningen zoals de ziekte van Alzheimer, waarbij vroege detectie belangrijk is: medicijnen en leefstijlveranderingen werken meestal het best voordat ernstige symptomen optreden. Spraak is een aantrekkelijke alternatieve informatiebron. Het is goedkoop om op te nemen, kan op afstand worden vastgelegd en weerspiegelt op natuurlijke wijze veel mentale vaardigheden, van geheugen tot aandacht en planning. De onderzoekers wilden testen of korte, alledaagse spraakmonsters konden dienen als een “digitale biomarker” voor cognitieve gezondheid.
Alledaagse spraak omzetten in meetbare signalen
Het team rekruteerde 1003 Engelssprekende volwassenen van 60 jaar en ouder uit de Verenigde Staten en het Verenigd Koninkrijk. De deelnemers maakten standaard online denktests die vier brede gebieden maten: taal, uitvoerende functies (planning en mentale flexibiliteit), geheugen en snelheid. Ze voerden ook drie eenvoudige spreektaken thuis uit: het beschrijven van twee goed bekende zwart‑wittaferelen die in klinische taaltesten worden gebruikt, en praten over hun afgelopen week. Met automatische spraakherkenningssoftware zetten de wetenschappers audio om in tekst en haalden vervolgens tientallen meetbare eigenschappen uit zowel het geluid als de woorden — zoals spreektijd, pauzefrequentie, woordenschatvariatie en hoe vaak ze verschillende woordsoorten gebruikten zoals zelfstandige naamwoorden, werkwoorden of voornaamwoorden.
Computers leren om denkvaardigheden te schatten
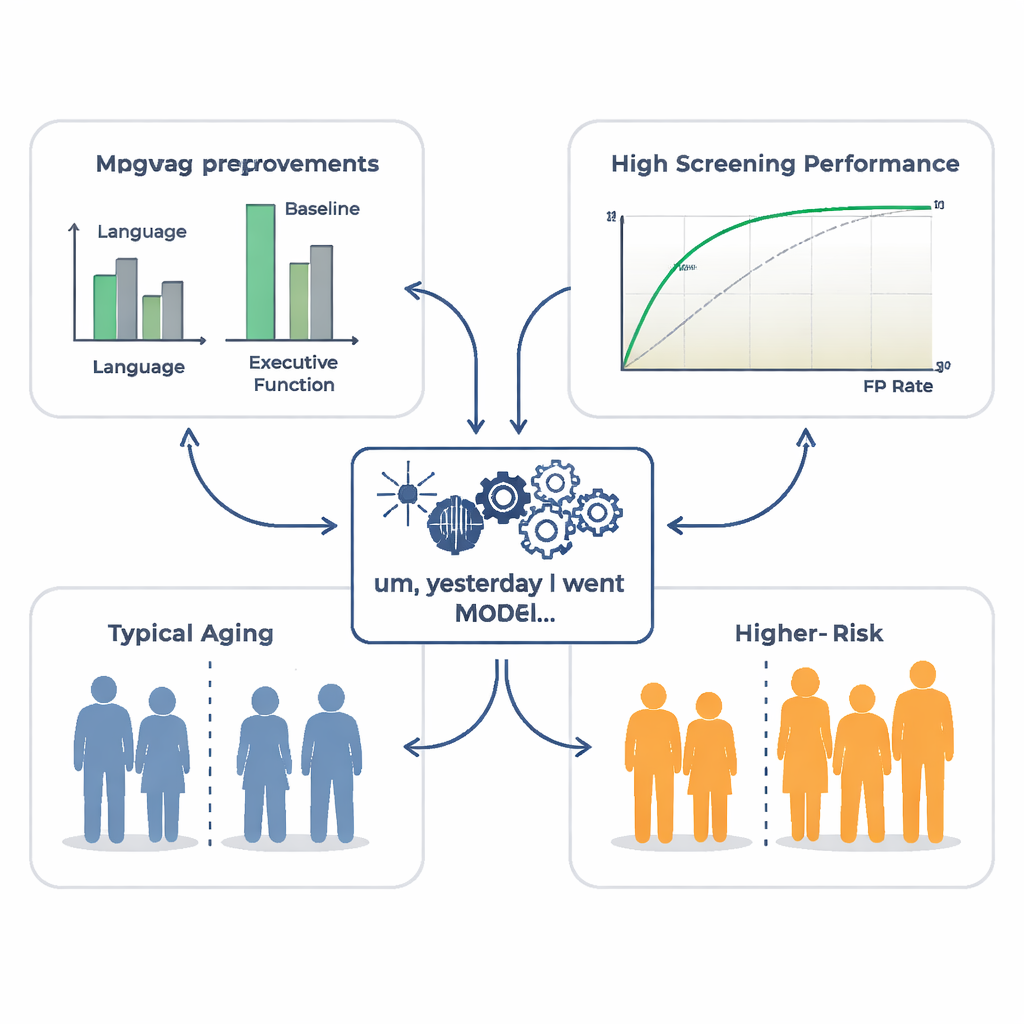
Met deze spraakkenmerken trainden de onderzoekers machine‑learningmodellen om iemands cognitieve testscores te voorspellen. Ze vergeleken modellen die alleen basisachtergrondinformatie gebruikten (leeftijd, geslacht, opleiding en land) met modellen die ook spraakkenmerken bevatten. Het toevoegen van spraak maakte een opvallend verschil: voor taalvaardigheid verklaarde het spraakgebaseerde model ongeveer 27% van de verschillen tussen mensen, meer dan vier keer zoveel als demografische gegevens alleen. Het ving ook een betekenisvol deel van de variatie in uitvoerende functies en denksnelheid op, al veel minder voor geheugen. Gedetailleerde analyse toonde dat rijk en specifiek woordgebruik en vloeiendere, meer vlotte voordracht (snellere spreeksnelheid en minder of kortere pauzes) doorgaans samenhingen met hogere testscores.
Het opsporen van mensen die mogelijk achteruitgaan
Buiten het schatten van scores op een continue schaal vroegen de onderzoekers zich af of spraak kon helpen individuen te signaleren wier prestaties onverwacht laag waren voor hun leeftijd en opleiding — mensen die mogelijk een hoger risico hebben op het ontwikkelen van dementie. Met dezelfde spraakkenmerken trainden ze een apart computermodel om deze “cognitieve laagpresteerders” van anderen te onderscheiden. Met name voor taalvaardigheid toonde het model goede screeningsprestaties, wat betekent dat een eenvoudige opname van een afbeeldingbeschrijving kan helpen een subgroep ouderen te identificeren die nadere klinische aandacht verdienen of sterke kandidaten zouden kunnen zijn voor deelname aan behandelstudies.
De aanpak testen bij echte patiënten
Om te onderzoeken of hun modellen klinisch relevante verschillen vastlegden, pasten de onderzoekers ze, zonder hertraining, toe op een onafhankelijke dataset van mensen met de ziekte van Alzheimer en gezonde leeftijdsgenoten die tientallen jaren eerder dezelfde afbeeldingbeschrijvingstaak hadden uitgevoerd. Zelfs al waren de opnamen ouder en rumoeriger, de spraakgebaseerde scores waren duidelijk lager voor de Alzheimer‑groep over alle vier cognitieve gebieden, vooral taal en uitvoerende functies. Dit suggereert dat de patronen die geleerd zijn van een grote groep grotendeels gezonde ouderen nog steeds zinvol zijn wanneer ze op patiënten met gediagnosticeerde dementie worden toegepast.
Wat dit kan betekenen voor de dagelijkse zorg
Voor niet‑specialisten is de kernboodschap dat korte monsters van gewone spraak verrassend veel informatie bevatten over hoe goed het brein van een oudere functioneert, met name voor taal en hogere denkfuncties. Hoewel deze methode geen volledige klinische evaluatie kan vervangen — en op zichzelf minder informatief is voor geheugen — zou het een goedkope, niet‑intrusieve manier kunnen worden om veranderingen in de tijd te volgen, tijdige controle te stimuleren en onderzoekers te helpen de juiste deelnemers voor klinische onderzoeken te vinden. In de toekomst kan een routine telefoongesprek of videogesprek stilletjes analyseren hoe we spreken en vroegtijdig aansporen om hulp te zoeken, lang voordat ernstige problemen duidelijk worden.
Bronvermelding: Heitz, J., Engler, I.M. & Langer, N. Towards a speech-based digital biomarker for cognitive impairment: speech as a proxy for cognitive assessment. npj Digit. Med. 9, 179 (2026). https://doi.org/10.1038/s41746-026-02360-8
Trefwoorden: spraakgebaseerde cognitieve screening, digitale biomarkers, Ziekte van Alzheimer, veroudering en dementie, machine learning in de geneeskunde