Clear Sky Science · nl
Decentraal machine learning en AI-klinische modellen vergelijken met lokale en gecentraliseerde alternatieven: een systematische review
Waarom het delen van medische inzichten zonder het delen van data ertoe doet
De moderne geneeskunde vertrouwt steeds meer op kunstmatige intelligentie om ziekten eerder te herkennen, de juiste behandeling te kiezen en te voorspellen wie het hoogste risico loopt. Toch hebben de beste AI‑tools enorme hoeveelheden patiëntgegevens nodig, en ziekenhuizen kunnen hun dossiers niet eenvoudig samenvoegen vanwege strikte privacywetgeving en ethische bezwaren. Dit artikel beoordeelt meer dan een decennium onderzoek naar “gedecentraliseerd” leren—manieren waarop ziekenhuizen samen AI kunnen trainen zonder ooit ruwe patiëntgegevens te delen—en stelt een praktische vraag: hoe goed presteren deze privacy‑besparende methoden in vergelijking met traditionele benaderingen?
Nieuwe manieren om van patiënten te leren en tegelijk privacy te beschermen
Bij traditioneel gecentraliseerd leren kopiëren ziekenhuizen al hun data naar één grote database en trainen daar één model. Bij lokaal leren bouwt elke instantie een eigen model op basis van eigen gegevens, zonder samenwerking. Gedecentraliseerd leren biedt een tussenweg. Bij federated learning bijvoorbeeld traint elk ziekenhuis lokaal een model; alleen de modelinstellingen (zoals de “knoppen” van een neuraal netwerk) worden vervolgens gedeeld om te worden samengevoegd tot een gedeeld model; patiëntendossiers verlaten de locatie nooit. Swarm learning verwijdert de centrale coördinator en laat instellingen modelupdates direct uitwisselen. Andere gedecentraliseerde benaderingen combineren voorspellingen van meerdere lokale modellen of splitsen het model over sites. Deze methoden zijn getest op problemen variërend van kankerdetectie en COVID‑19‑diagnose tot hartziekten, diabetes, hersenaandoeningen en psychiatrische aandoeningen.
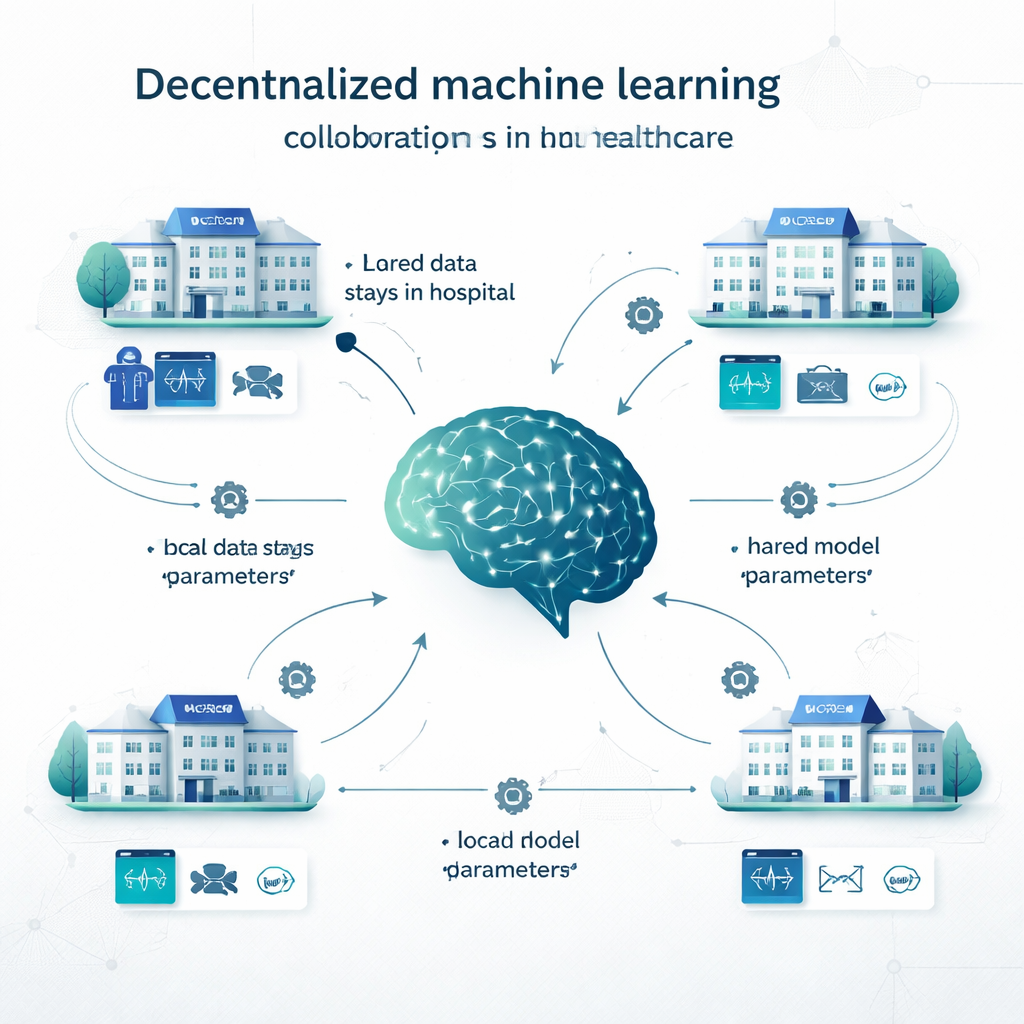
Wat de onderzoekers onderzochten
De auteurs doorzochten systematisch 11 grote databanken en screenden 165.010 studies gepubliceerd tussen 2012 en maart 2024. Na het verwijderen van duplicaten en studies die geen echte klinische beslissingen betrokken, bleven 160 artikelen over. Samen rapporteerden deze artikelen 710 gedecentraliseerde modellen en 8.149 directe prestatievergelijkingen met gecentraliseerde of lokale modellen. De meeste studies richtten zich op diagnose, maar er waren er ook veel over beeldsegmentatie (bijvoorbeeld het omlijnen van tumoren), het voorspellen van toekomstige uitkomsten zoals overleving of complicaties, en gecombineerde taken. De datatypen omvatten vrijwel alle belangrijke bronnen die in de geneeskunde worden gebruikt: elektronische patiëntendossiers, CT‑ en MRI‑scans, röntgenfoto’s, digitale pathologiedia’s, hart‑ en hersensignalen en zelfs genetische data.
Hoe privacy‑vriendelijke modellen zich verhouden tot gecentraliseerde AI
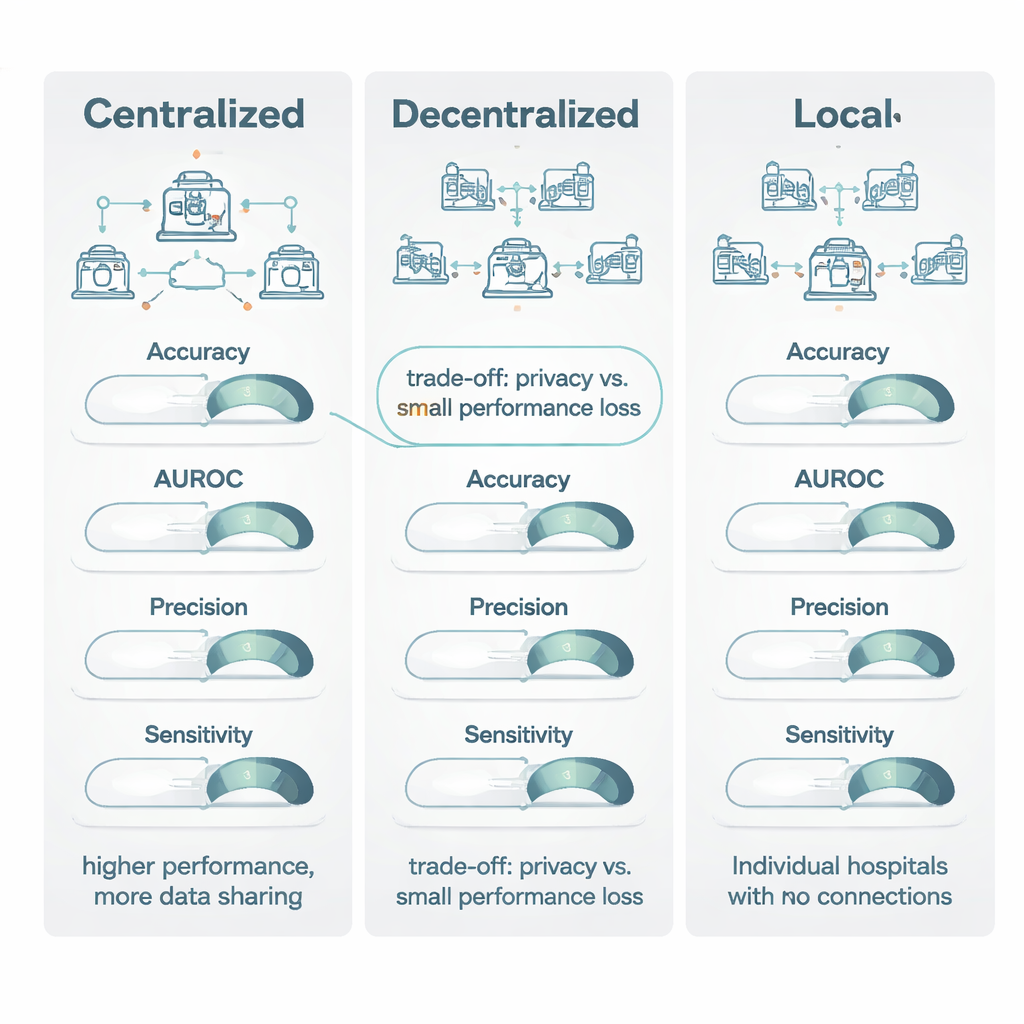
Wanneer gedecentraliseerde modellen werden vergeleken met gecentraliseerde modellen die op samengevoegde data waren getraind, kwam gecentraliseerd leren meestal iets beter uit de bus. Het presteerde vooral goed op “drempelgebaseerde” maatstaven zoals accuracy en een veelgebruikte beeldscore genaamd de Dice‑coëfficiënt, en won in ongeveer driekwart van de gevallen en met een verschil dat als een matig tot groot voordeel werd beschouwd. Voor rangschikkingsmaatstaven—zoals de area under the ROC‑curve (AUROC), die vastlegt hoe goed een model patiënten van lager naar hoger risico rangschikt—lagen gedecentraliseerde en gecentraliseerde modellen echter veel dichter bij elkaar, met slechts een kleine voorsprong voor gecentraliseerde training. Belangrijk is dat wanneer beide modellen een door de auteurs ‘klinisch levensvatbare’ prestatie bereikten (een score van ten minste 0,80), de typische winst van het gecentraliseerde model bescheiden was: vaak minder dan 1–1,5 procentpunt. In veel situaties kwam dit neer op “uitstekend versus acceptabel”, niet “bruikbaar versus waardeloos”.
Waarom gedecentraliseerd leren beter is dan het alleen doen
Het sterkste signaal in de review verscheen bij de vergelijking van gedecentraliseerde modellen met puur lokale modellen. Over alle belangrijke meetwaarden—accuracy, AUROC, F1‑score, sensitiviteit, specificiteit en vooral precisie—presteerden gedecentraliseerde methoden bijna altijd beter, vaak met ruime marges. In directe vergelijkingen versloeg gedecentraliseerd leren lokale modellen in meer dan 80% van de vergelijkingen voor kernmaatstaven zoals accuracy, precisie en AUROC. In veel gevallen slaagden lokale modellen er niet in de 0,80‑drempel voor klinische bruikbaarheid te halen, terwijl het overeenkomstige gedecentraliseerde model die drempel ruimschoots overschreed, waarbij de sensitiviteit met maar liefst 27 procentpunt toenam. De auteurs schrijven dit toe aan de bredere ervaring die multisite‑modellen opdoen: door patronen van vele ziekenhuizen te “zien” worden ze minder misleid door locatie‑specifieke eigenaardigheden in scanners of administratie en beter afgestemd op ziektekenmerken die werkelijk generaliseerbaar zijn.
Balanceren van prestatie, privacy en praktische inzet
De review concludeert dat gecentraliseerd leren de gouden standaard blijft wanneer privacyregels en logistiek het toestaan om data te combineren en wanneer iedere fractie van een procentpunt in prestatie telt, zoals bij zeer zeldzame ziekten. Gedecentraliseerd leren biedt echter een krachtig en klinisch aanvaardbaar alternatief voor situaties waarin het delen van data wordt beperkt door wetten zoals de AVG en de EU AI‑verordening, of door institutionele beleidsregels. Vergeleken met volledig lokale modellen bieden gedecentraliseerde benaderingen grote winsten in zowel nauwkeurigheid als betrouwbaarheid terwijl de data binnen de muren van het ziekenhuis blijven. De auteurs pleiten ervoor dat toekomstig werk privacytechnieken en computationele kosten duidelijker rapporteert, zodat zorgsystemen weloverwogen keuzes kunnen maken over wanneer kleine prestatieafwegingen de substantiële voordelen op het gebied van privacy en samenwerking waard zijn.
Bronvermelding: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
Trefwoorden: federated learning, gezondheidszorg AI, privacy van medische gegevens, gedecentraliseerd machine learning, klinische voorspellingsmodellen