Clear Sky Science · nl
Generalizatie van automatische tumorsegmentatie in histopathologische whole-slide afbeeldingen over meerdere kankertypen
Waarom dit belangrijk is voor kankerzorg
De kankerdiagnose berust nog steeds op experts die glazen preparaten met gekleurd weefsel onder een microscoop bekijken — een tijdrovende taak die zwaarder wordt door toenemende aantallen gevallen en een tekort aan pathologen. Deze studie stelt een eenvoudige maar krachtige vraag: kan één kunstmatig-intelligentiesysteem betrouwbaar kankervlakken vinden in digitale microscoopbeelden voor veel verschillende tumortypen, in plaats van voor elk type kanker een apart hulpmiddel te bouwen? Als dat mogelijk is, kan het de werkdruk verlichten, de diagnose versnellen en geavanceerde analyses ook toegankelijk maken voor zeldzamere kankers waarbij data schaars zijn.
Van glazen preparaten naar digitale helpers
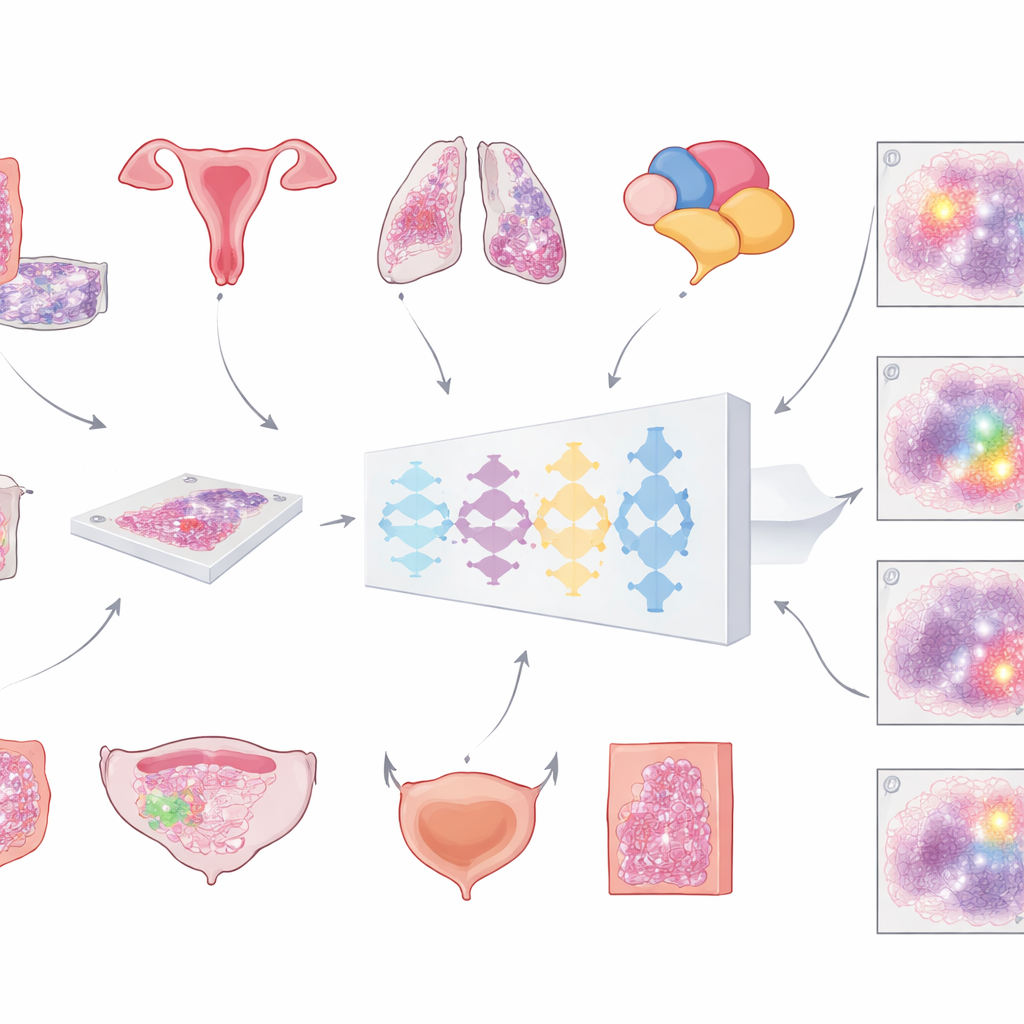
Moderne ziekenhuizen scannen steeds vaker microscooppreparaten om enorme, gedetailleerde “whole-slide afbeeldingen” van tumoren te maken. De eerste cruciale stap voor elke computergebaseerde analyse is het scheiden van kankergezwel van de rest — normale cellen, vet, lege glazen en artefacten. Tot nu toe zijn de meeste geautomatiseerde hulpmiddelen getraind op slechts één kankertype, wat hun toepasbaarheid beperkt. Het team achter dit werk wilde één universeel model bouwen dat tumorgebieden kan herkennen over meerdere veelvoorkomende kankers in preparaten gekleurd met de routine haematoxylin- en eosine-kleuringen. Hun visie was een algemeen hulpmiddel dat in veel diagnostische werkstromen ingeplugd kan worden zonder telkens te moeten herontwerpen.
Één model trainen om veel kankers te zien
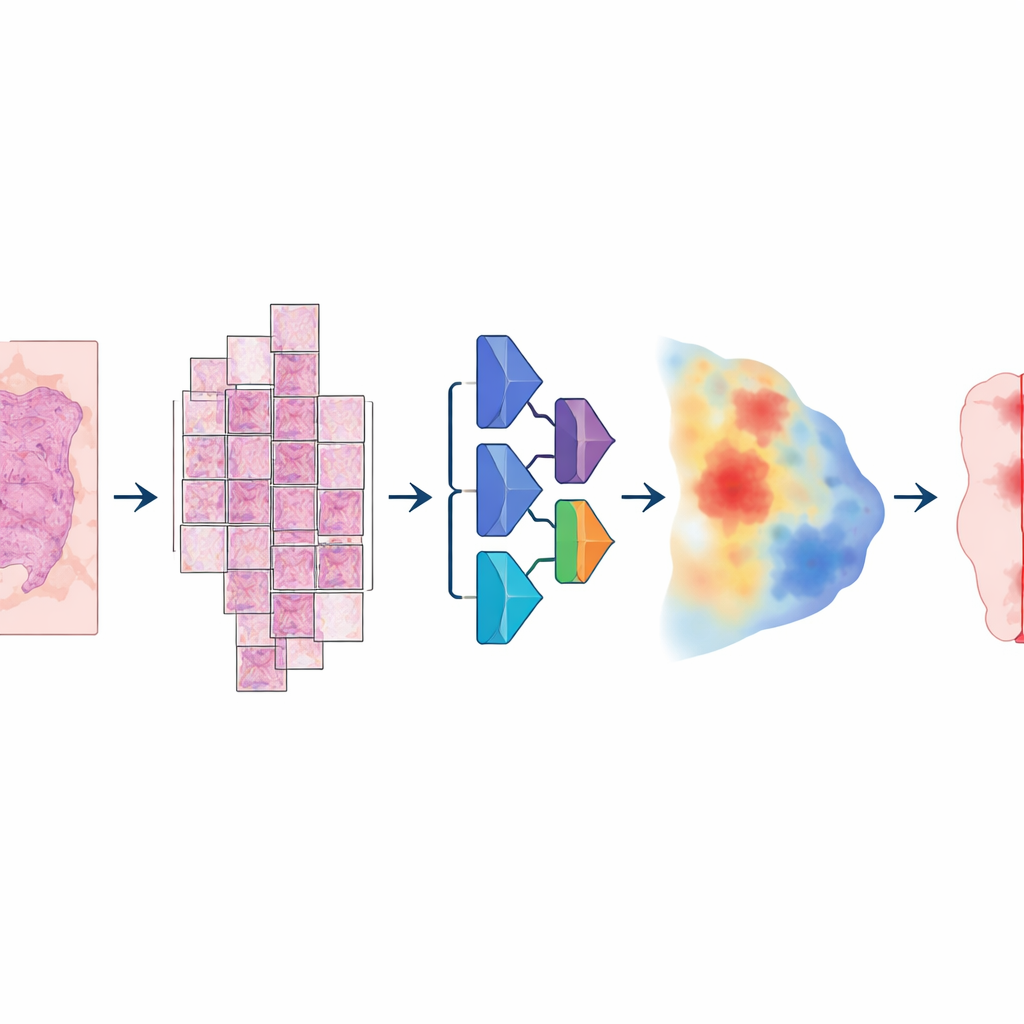
Om dit model te bouwen, verzamelden de onderzoekers een uitzonderlijk grote en gevarieerde verzameling digitale slides: meer dan 20.000 whole-slide afbeeldingen van meer dan 4.000 patiënten met colorectale-, endometrium-, long- en prostaatkanker. Alle monsters kwamen uit standaard gefixeerd en paraffine-ingebed weefsel en werden gescand op twee verschillende hoogresolutie scanners. Een patholoog tekende zorgvuldig tumorgebieden aan op elke slide, wat de “waarheid op de grond” leverde waarvan de computer kon leren. Het model volgde een meerstappen-pijplijn: elke enorme afbeelding werd opgesplitst in grote overlappende tegels, door een diep neuraal netwerk gehaald dat voor elke pixel een inschatting maakte van de kans dat het tumor was, en vervolgens opnieuw samengevoegd tot een vloeiende kaart die uiteindelijk werd omgezet in een duidelijke tumor-tegen-niet-tumor mask.
Het systeem op de proef stellen
Belangrijk is dat het team niet bij de trainingsprestaties bleef. Ze testten hetzelfde model op meer dan 3.000 aanvullende patiënten verdeeld over zes kankertypen — inclusief borst- en blaaskankers die nooit tijdens de training waren gebruikt — en op slides van meerdere ziekenhuizen en scanners. De nauwkeurigheid werd voornamelijk gemeten met een standaard overlapscore (de Dice-coëfficiënt), die 100% bereikt wanneer de tumorlijn van de computer precies overeenkomt met die van de patholoog. Voor grote, intacte tumormonsters bij colorectale-, endometrium-, long-, prostaat- en borstkanker overschreed de gemiddelde overlap 80% en vaak 90%. In grote externe verzamelingen van The Cancer Genome Atlas, afkomstig uit vele laboratoria en scanners wereldwijd, bleef de prestatie opnieuw boven 80%, wat suggereert dat het model goed generaliseert buiten de thuisinstelling.
Waar het moeite mee heeft en hoe het zich verhoudt
De belangrijkste zwakte trad op bij vroegstadium blaaskankers die worden bemonsterd met een procedure die kleine, gefragmenteerde weefselstukjes oplevert. In deze gevallen mislukte het model vaak om überhaupt tumorgebied aan te geven, vooral wanneer het tumorgebied zeer klein was. Wanneer het wel tumor detecteerde, was de overlap met de patholoog hoog, en eenvoudige aanpassingen van de uiteindelijke drempels verbeterden de resultaten — wat erop wijst dat het onderliggende netwerk het patroon herkende maar de nabehandeling te strikt was. De onderzoekers bouwden ook vier “specialistische” modellen, elk getraind op één kankertype, en vonden dat geen van deze significant beter presteerde dan het algemene model binnen zijn eigen domein. Daarentegen faalden deze specialistische systemen grotendeels wanneer ze op andere kankertypen werden toegepast, terwijl het algemene model robuust bleef. Vergeleken met een populair, generieker medisch segmentatiehulpmiddel dat gebruikersaanwijzingen vereist, presteerde het nieuwe model meestal even goed of beter en bleef het volledig automatisch.
Wat dit betekent voor patiënten en artsen
Voor niet-experts is de kernboodschap dat één goed ontworpen AI-systeem betrouwbaar kankergezwel kan markeren op digitale slides voor meerdere belangrijke tumortypen, zonder dat er voor elke ziekte of scanner aangepaste versies nodig zijn. Het vervangt de patholoog niet, maar het kan waarschijnlijke tumorgebieden vooraf markeren, consistente metingen ondersteunen en specialisten vrijmaken om zich te concentreren op de meest uitdagende gevallen. De huidige versie mist nog enkele zeer kleine of vroegtijdige tumoren — met name gefragmenteerde blaasklachten en waarschijnlijk andere biopsie-achtige weefsels — dus het is nog niet geschikt om de allerkleinste sporen van kanker op te sporen. Desalniettemin toont de studie aan dat brede, ‘pan-kanker’ tumorsegmentatie haalbaar is onder realistische omstandigheden en een robuuste eerste stap kan vormen voor toekomstige geautomatiseerde hulpmiddelen die kankerstadium beoordelen, therapierespons voorspellen of precisietherapieën begeleiden.
Bronvermelding: Skrede, OJ., Pradhan, M., Isaksen, M.X. et al. Generalisation of automatic tumour segmentation in histopathological whole-slide images across multiple cancer types. npj Precis. Onc. 10, 107 (2026). https://doi.org/10.1038/s41698-026-01311-6
Trefwoorden: digitale pathologie, deep learning, tumorsegmentatie, whole-slide imaging, pan-kanker model