Clear Sky Science · nl
IMFLKD: een stimulansmechanisme voor gedecentraliseerd federated learning gebaseerd op knowledge distillation
Waarom delen veilig en eerlijk kan zijn
Moderne kunstmatige intelligentie leeft van gegevens, maar het merendeel van onze data staat op persoonlijke telefoons, ziekenhuisservers of bedrijfsclouds en kan niet zomaar worden gekopieerd en gedeeld. Federated learning biedt een manier waarop veel apparaten samen een model kunnen trainen zonder hun ruwe data prijs te geven, maar de huidige systemen hebben nog steeds moeite met privacylekken, centrale faalpunten en oneerlijke beloningen voor degenen die het meest bijdragen. Dit artikel introduceert een nieuw raamwerk, IMFLKD, dat drie krachtige ideeën — blockchain, knowledge distillation en reputatiescores — combineert om dit soort collectief leren op de lange termijn privéter, robuuster en rechtvaardiger te maken.
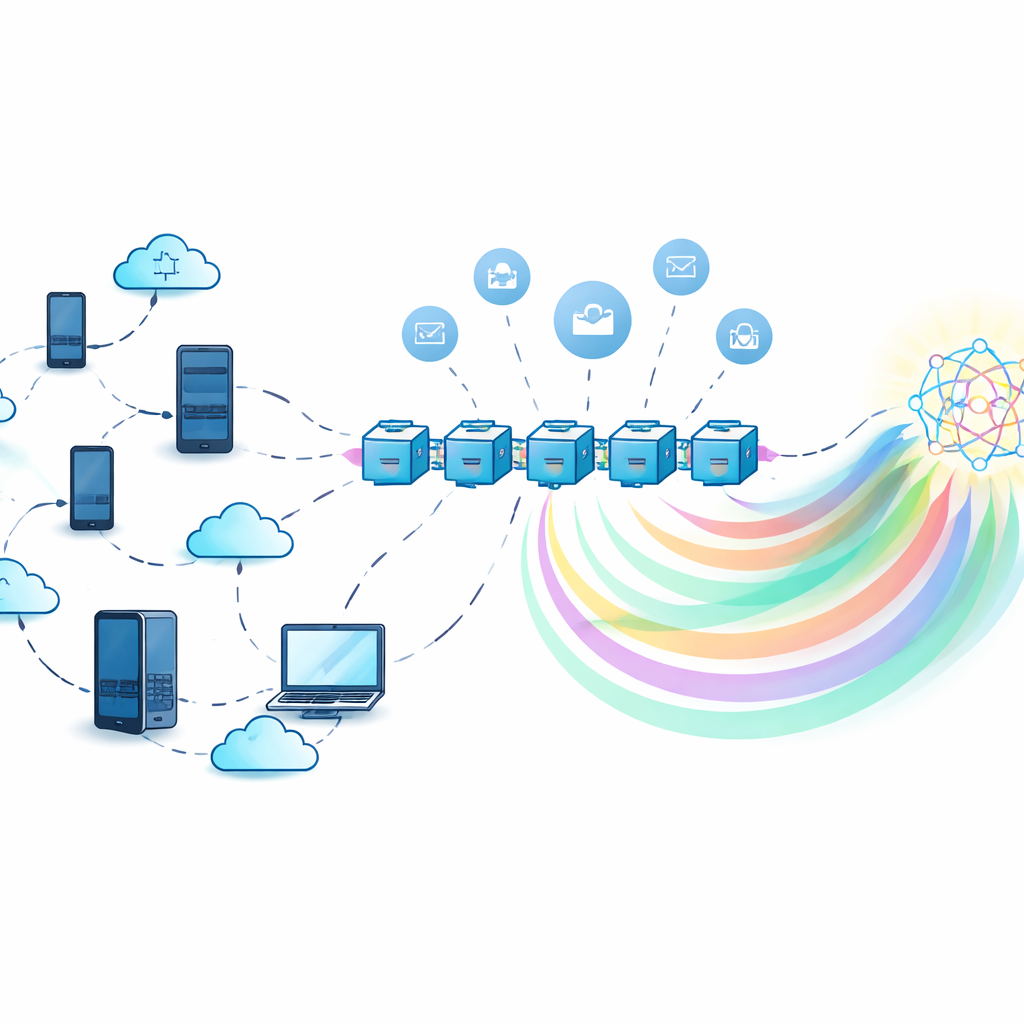
Samen trainen zonder geheimen te delen
In klassiek federated learning verzamelt een centrale server modelupdates van veel deelnemers en combineert die. Dit voorkomt dat ruwe data rondreist, maar de server zelf wordt zo een aantrekkelijk doelwit: als hij uitvalt stokt het hele systeem, en als hij onbetrouwbaar is, kan hij informatie uit modelupdates misbruiken of lekken. De auteurs gebruiken in plaats daarvan een gedecentraliseerd blockchain-ledger om de training te coördineren. Elke deelnemer traint een lokaal model op zijn eigen data en interacteert vervolgens met smart contracts op de blockchain die bijdragen registreren, informatie aggregeren en beloningen uitdelen, allemaal zonder te vertrouwen op één centrale autoriteit.
Kennis delen, niet zware modellen
Om communicatielasten te verminderen en privacy verder te beschermen, maakt het raamwerk gebruik van knowledge distillation. In plaats van volledige modelparameters te versturen, stuurt iedere deelnemer alleen "zachte labels" — de voorspelde waarschijnlijkheden van het model voor een set gedeelde inputs — die veel lichter zijn en minder prijsgeven over iemands data. Omdat er mogelijk geen echt gedeelde dataset bestaat, gebruikt het systeem een generatief model, een conditional variational autoencoder, om een synthetische "pseudo-publieke" dataset te maken die ongeveer overeenkomt met de algemene labelverdeling zonder originele records bloot te geven. Deelnemers trainen op hun eigen data, doen voorspellingen op deze synthetische dataset en verfijnen hun modellen vervolgens met een geaggregeerd signaal dat is afgeleid van ieders gecombineerde kennis.
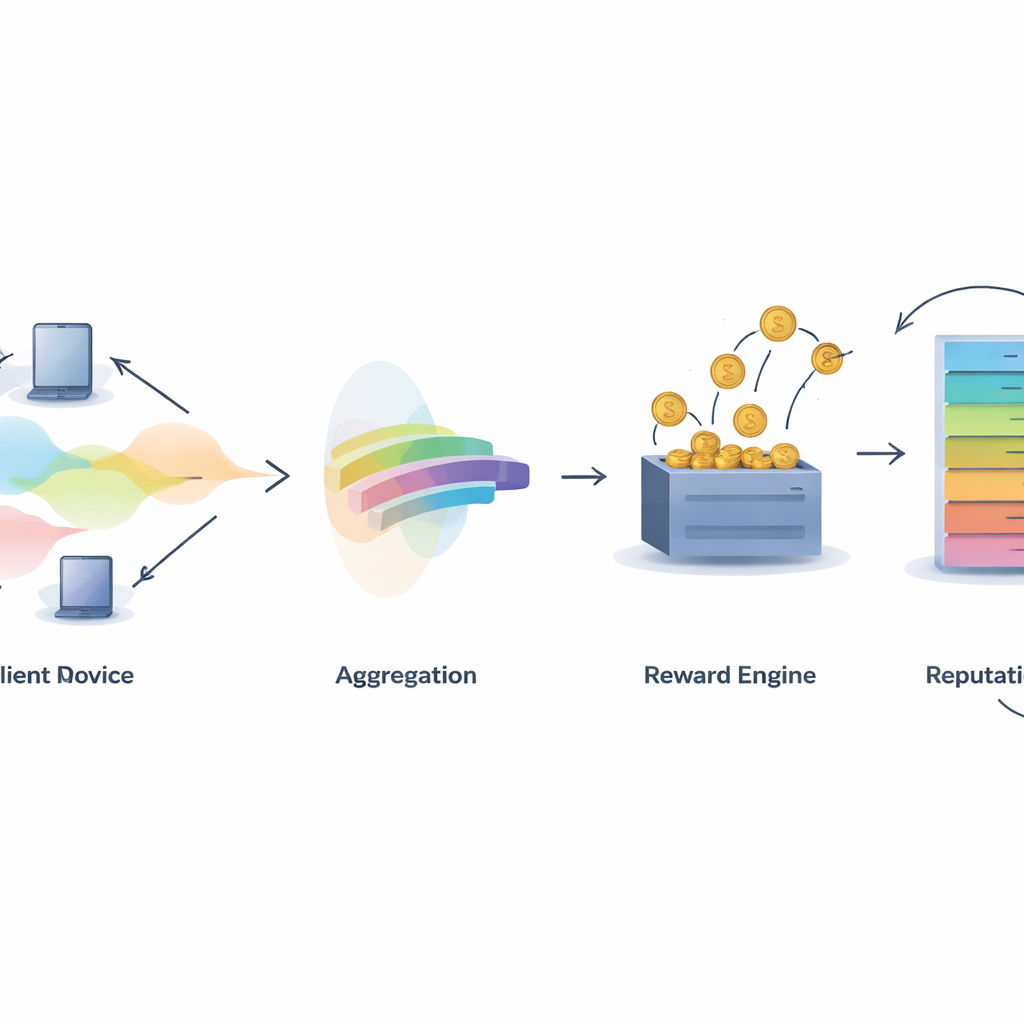
Meten wie echt helpt
Een centrale uitdaging in elk collaboratief systeem is bepalen wie krediet verdient. IMFLKD pakt dit aan met een tweefasige methode voor bijdrage-evaluatie gebaseerd op labelaggregatie. Eerst bekijkt een lichtgewicht Bayesiaans algoritme de voorspellingen van alle deelnemers en leidt zowel het meest waarschijnlijke ware label per voorbeeld als een kwaliteitsscore per model af, en werkt deze scores bij naarmate er meer taken binnenkomen. Deze aanpak werkt online, zonder eerder opgeslagen data, en gaat om met lawaaierige of kwaadaardige bijdragers door modellen die vaak afwijken van de opkomende consensus lager te wegen. Experimenten tonen aan dat deze labelaggregatie de nauwkeurigheid met ongeveer 10 procent verbetert vergeleken met eenvoudige meerderheidstemming, terwijl het snel genoeg blijft voor grootschalige, hulpbronbeperkte omgevingen.
Kwaliteit omzetten in beloningen en reputatie
Als de bijdragekwaliteit bekend is, gebruikt IMFLKD een stimulansschema genaamd een gewogen peer truth serum om deze om te zetten in beloningen. Deelnemers worden vergeleken met een kwaliteitsgeweegde peer-consensus: wie overeenkomt met hoogkwalitatieve peers verdient meer, terwijl wie afwijkt of vaak in tegenspraak is, wordt bestraft. Dit maakt eerlijk rapporteren op de lange termijn de meest winstgevende strategie, zelfs bij collusie. Daarbovenop bouwt het systeem een multidimensionale reputatiescore voor elke deelnemer, die datakwaliteit, activiteitsniveau en gedragsstabiliteit combineert, en ouder gedrag afbouwt met een tijdsvervalfactor. Reputatie voedt vervolgens latere ronden terug door te beïnvloeden hoeveel gewicht iemands voorspellingen krijgen en of iemand wordt geselecteerd voor toekomstige taken.
Vertrouwen opbouwen in collectieve intelligentie
Al met al laat het IMFLKD-raamwerk zien dat het mogelijk is om leren te coördineren over veel onafhankelijke apparaten op een manier die efficiënt, privacybewust en bestand tegen freeloaders en aanvallers is. Door synthetische datageneratie, rigoureuze bijdragebeoordeling, speltheoretische beloningen en dynamische reputatietracking op een blockchain te combineren, moedigt het systeem deelnemers aan om eerlijk en consistent te handelen over vele trainingsrondes. Voor een leek is de boodschap dat we de collectieve kracht van gedistribueerde data — zoals medische dossiers, sensormetingen of persoonlijke apparaten — kunnen benutten zonder alles aan één bedrijf of server te geven, terwijl we tegelijk waarborgen dat degenen die de meest nuttige informatie leveren ook het meest profiteren.
Bronvermelding: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
Trefwoorden: federated learning, blockchain, knowledge distillation, incentive mechanisms, reputation systems