Clear Sky Science · nl
Hybride evolutionair‑gradienttraining verbetert langetermijnvoorspellingen van tijdreeksen
Waarom betere voorspellingen op lange termijn belangrijk zijn
Van elektriciteitsvraag en snelwegverkeer tot wisselkoersen en lokaal weer: ons leven wordt gevormd door systemen die in de tijd veranderen. Deze patronen met dagen of weken vooruit nauwkeurig voorspellen kan energie besparen, congestie verminderen en bedrijven veerkrachtiger maken. Maar hoe verder we in de toekomst kijken, hoe moeilijker het voor huidige AI‑instrumenten wordt om om te gaan met veranderende omstandigheden, ruis in meetgegevens en beperkte rekencapaciteit. Dit artikel introduceert een nieuwe manier om voorspellingsmodellen te trainen zodat ze nauwkeurig en stabiel blijven, zelfs wanneer de wereld niet stilzit.
Leren van vele modellen in plaats van één
De meeste moderne tijdreeksvoorspellers vertrouwen op één enkel diep neuraal netwerk dat met gradient descent wordt getraind, de standaardmethode die modelparameters stapsgewijs bijstuurt om de fout te verkleinen. Dat werkt goed wanneer data consistent zijn, maar kan falen als omstandigheden verschuiven, metingen ruis bevatten of de trainingstijd krap is. In plaats van een nieuw netwerkontwerp te verzinnen, stellen de auteurs Evolutionary‑Guided Module Fusion with Gradient Refinement (EGMF‑GR) voor, een trainingskader dat rond bestaande architecturen kan worden toegepast. Het kernidee is om een kleine “populatie” van modellen aan te houden die allemaal dezelfde structuur delen maar vanuit verschillende willekeurige startsituaties beginnen. Tijdens de training verkennen deze modellen verschillende manieren om de data te fitten, en het op dat moment best presterende model wordt gebruikt om verbeteringen bij de anderen te sturen.
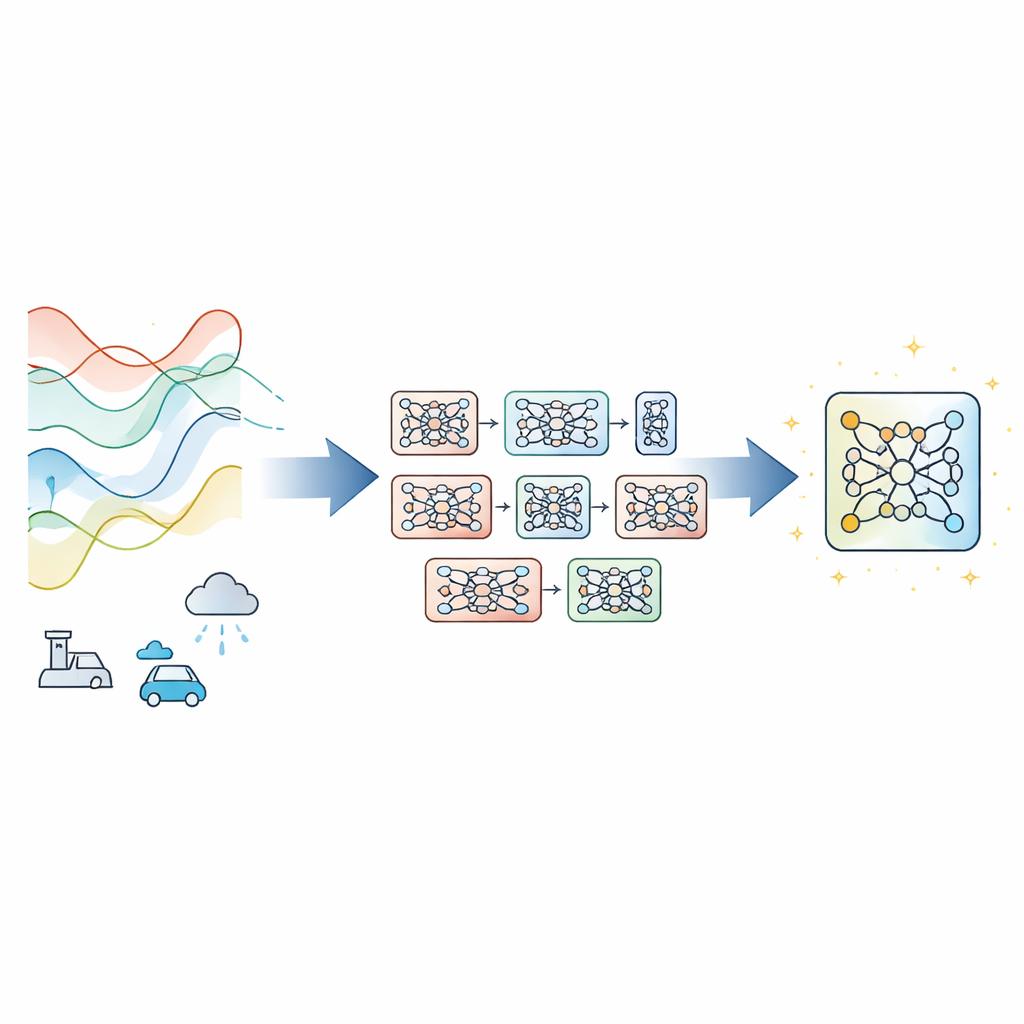
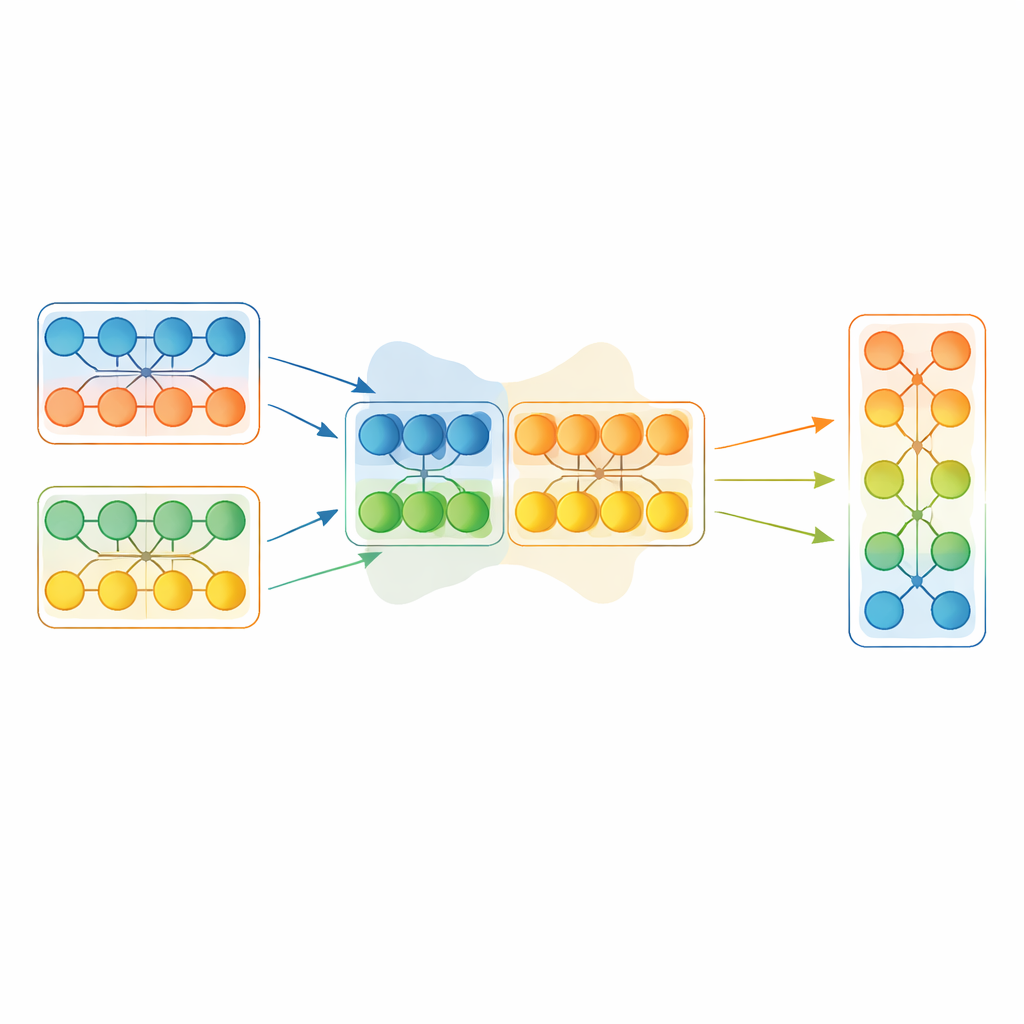
Goede onderdelen lenen en toch nuttige diversiteit behouden
In plaats van een heel winnend model klakkeloos te kopiëren, werkt EGMF‑GR op module‑niveau—herhaalde bouwblokken binnen een netwerk, zoals stapels lagen. Voor elk model in de populatie zet het kader corresponderende modules uit één model tegenover die in het huidige beste model en vergelijkt hun interne signalen terwijl ze dezelfde inputbatch verwerken. Het gebruikt verschillende eenvoudige maatstaven voor verschil, die zowel vangen hoe de activiteitspatronen zijn gevormd als hoe groot ze zijn. Deze module‑gewijze afwijkingen worden vervolgens samengevat, en alleen modules waarvan het gedrag als sterke uitschieters ten opzichte van hun soortgenoten lijkt te zijn, komen in aanmerking voor bijwerken. Wanneer dat gebeurt, wordt de achterblijvende module in de richting van de corresponderende module in het beste model bijgestuurd via een gewogen mix van hun parameters, plus een kleine willekeurige verstoring om diversiteit te bewaren.
Degradienten laten opruimen na de grote zetten
Het mengen van delen uit verschillende netwerken kan abrupte veranderingen introduceren. Om destabilisatie van de training te voorkomen, ondergaat elk gefuseerd model daarna een korte, conventionele gradient‑descentfase op de trainingsdata. Deze verfijningsstap laat het netwerk soepel heraanpassen aan zijn nieuwe interne configuratie terwijl de voordelen van de geleende kennis behouden blijven. De algehele procedure wisselt af: selecteer het huidige beste model op basis van een apart gehouden deel van de data, fuseer selectief modules van die leider in de rest van de populatie, en fijnstem vervolgens iedereen kort met gradients. Cruciaal is dat de methode ook interne boekhoudingsstaten synchroniseert, zoals lopende gemiddelden die door bepaalde lagen worden gebruikt; die worden in eenvoudigere model‑samenvoegingsschema’s vaak genegeerd maar kunnen de stabiliteit sterk beïnvloeden.
De voordelen aantonen over veel echte signalen
Om het kader te testen pasten de auteurs EGMF‑GR toe op verschillende populaire voorspellingsbackbones, waaronder Transformer‑achtige modellen en een recent convolutioneel ontwerp, zonder hun kernstructuren te veranderen. Ze evalueerden de prestaties op acht openbare benchmarks die energieverbruik, verkeersstroom, wisselkoersen en weer bestrijken, en op meerdere voorspellingshorizons variërend van enkele uren tot enkele dagen vooruit. Bij een strikt gelijkgestelde budget van dure backward‑pass updates verminderde de hybride training consequent de voorspellingsfouten en maakte het het trainingsgedrag vloeiender voor de meeste model–datasetcombinaties, vooral in hoogdimensionale of rumoerige omgevingen. Het team vergeleek hun aanpak ook met gebruikelijke enkelmodeltrucs zoals exponentiële voortschrijdende gemiddelden en stochastic weight averaging, en vond dat populatiegebaseerde modulefusie extra voordelen bood boven eenvoudige gewichtsvervlakking.
Betrouwbaar blijven als de omstandigheden verslechteren
Echte systemen gedragen zich zelden als schone lesboekvoorbeelden, dus de auteurs testten ook de robuustheid onder zwaardere scenario’s: kunstmatig gecorrumpeerde inputs, ontbrekende datablokken en periodes waarin de onderliggende dynamiek plotseling verandert. EGMF‑GR hielp duidelijk wanneer inputs ruisig of gedeeltelijk afwezig waren, wat suggereert dat het lenen van stabiel modulegedrag van het huidige beste model lokale glitches kan tegengaan. Tijdens plotselinge regimewisselingen was het voordeel kleiner, wat erop wijst dat te veel uitlijning soms de aanpassing aan nieuwe patronen kan vertragen. Dit wijst op toekomstige verfijningen waarbij de fusiekracht wordt teruggeschroefd wanneer de omgeving zeer volatiel wordt.
Wat dit betekent voor alledaagse voorspellingshulpmiddelen
In eenvoudige termen toont de studie aan dat het trainen van meerdere samenwerkende versies van hetzelfde voorspellingsmodel, en het hen alleen laten delen van die onderdelen die echt als beter blijken, langetermijnvoorspellingen nauwkeuriger en stabieler kan maken zonder de modellen zelf opnieuw te ontwerpen. EGMF‑GR werkt als een gedisciplineerde teamsport: leden nemen af en toe elkaars sterkste zetten over, en oefenen daarna even zelf om bij te passen op het huidige spel. Voor praktijkmensen biedt dit een plug‑in trainingsstrategie die bestaande voorspellingssystemen in financiën, energie, transport en klimaattoepassingen kan versterken, vooral wanneer data rommelig zijn en rekencapaciteit schaars is.
Bronvermelding: Zhao, L., Chen, Z., Wu, N. et al. Hybrid evolutionary-gradient training improves long-term time series forecasting. Sci Rep 16, 10697 (2026). https://doi.org/10.1038/s41598-026-45017-y
Trefwoorden: tijdreeksvoorspelling, evolutionaire training, neurale netwerken, modelfusie, distributieverschuiving