Clear Sky Science · nl
Gegevensgestuurde ontwerp van LNA-blokkers voor efficiënte verwijdering van verontreinigingen in Ribo-Seq-bibliotheken
Waarom het opschonen van sequencinggegevens belangrijk is
De moderne biologie is vaak afhankelijk van het uitlezen van miljoenen kleine RNA-fragmenten om te begrijpen hoe cellen eiwitten produceren. Maar deze krachtige metingen, in het bijzonder een methode genaamd ribosoomprofilering (Ribo‑Seq), kunnen worden verstoord door irrelevante RNA-deeltjes die sequencingcapaciteit en geld verspillen. Deze studie beschrijft een eenvoudige, gegevensgestuurde manier om gespecialiseerde moleculaire "blokkers" te ontwerpen die selectief die ongewenste fragmenten verwijderen, waardoor de nuttige informatie die onderzoekers uit hetzelfde experiment halen bijna verdubbelt.
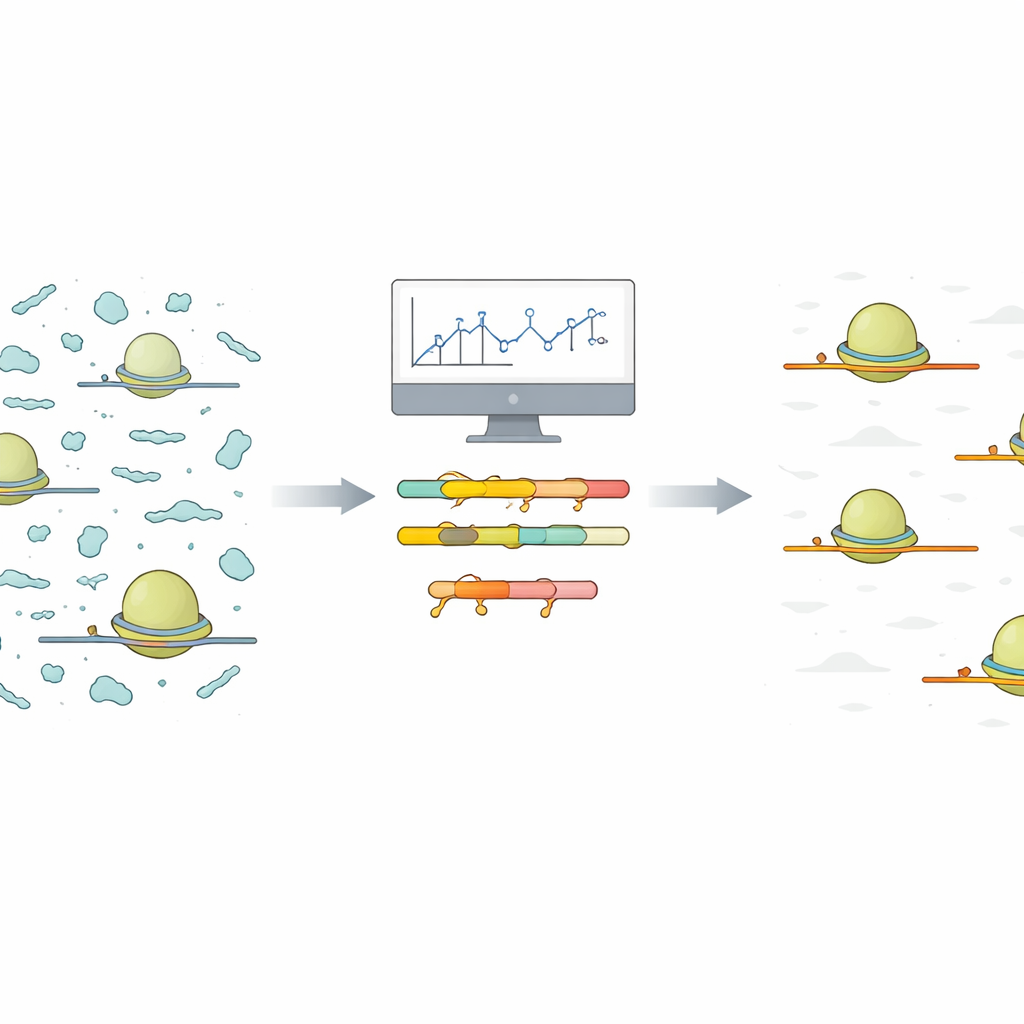
Het probleem van rumoerige ribosoommomentopnames
Ribo‑Seq legt een momentopname vast van welke berichten in een cel actief worden vertaald naar eiwitten. Hiervoor isoleren wetenschappers ribosomen samen met de korte stukken boodschapper-RNA (mRNA) die ze beschermen. Alles wat overblijft wordt afgebroken, en de beschermde snippets worden gesequenced en teruggeplaatst op het genoom. In de praktijk glippen echter veel andere kleine niet-coderende RNA-stukjes door dit proces. Omdat deze verontreinigende fragmenten talrijk en sterk variabel zijn, nemen ze een groot deel van de sequencingreads in beslag, waardoor er minder reads overblijven voor de echte eiwitcoderende signalen waarin onderzoekers geïnteresseerd zijn.
Waarom bestaande opschoningsmethoden tekortschieten
Standaardstrategieën proberen overvloedige ribosomale en andere niet-coderende RNA's te verwijderen met vooraf ontworpen capture-probes of enzymen. Deze methoden werken goed wanneer het doel-RNA intact en voorspelbaar is, maar Ribo‑Seq hakt RNA opzettelijk in vele verschillend lange fragmenten. Die fragmentatie verstoort de doelplaatsen voor vaste probe-sets, waardoor deverwijdering veel minder efficiënt wordt. Bovendien hangt het exacte mengsel van verontreinigingen af van de bestudeerde soort, kweekomstandigheden en zelfs welk nuclease-enzym is gebruikt. Bestaande opschoningsworkflows omvatten ook vaak meerdere incubatie- en zuiveringsstappen, die tijdrovend zijn en kunnen leiden tot monsterverlies of bias.
Aangepaste blokkers ontworpen op basis van echte data
De auteurs stellen een gestroomlijnde aanpak voor die begint met een kleine, goedkope proef-sequencingrun onder dezelfde condities als gepland voor het volledige experiment. Ze leveren een R-script dat de uitgelijnde reads van deze proefrun neemt en automatisch vergelijkbare verontreinigende fragmenten groepeert op basis van sequentie. Voor elke groep rapporteert het script de kortste gemeenschappelijke sequentie die in de fragmenten voorkomt. Deze korte, gedeelde strengen zijn ideale doelplaatsen voor gespecialiseerde moleculen die locked nucleic acid (LNA)-oligonucleotiden worden genoemd. LNAs zijn korte ketens met een chemische modificatie die ze zeer sterk laat binden aan overeenkomend RNA. Het script genereert ook intuïtieve heatmaps en samenvattende plots, zodat gebruikers kunnen zien welke verontreinigingen domineren en hoeveel LNA-doelen nodig zouden zijn voor substantiële opschoning.
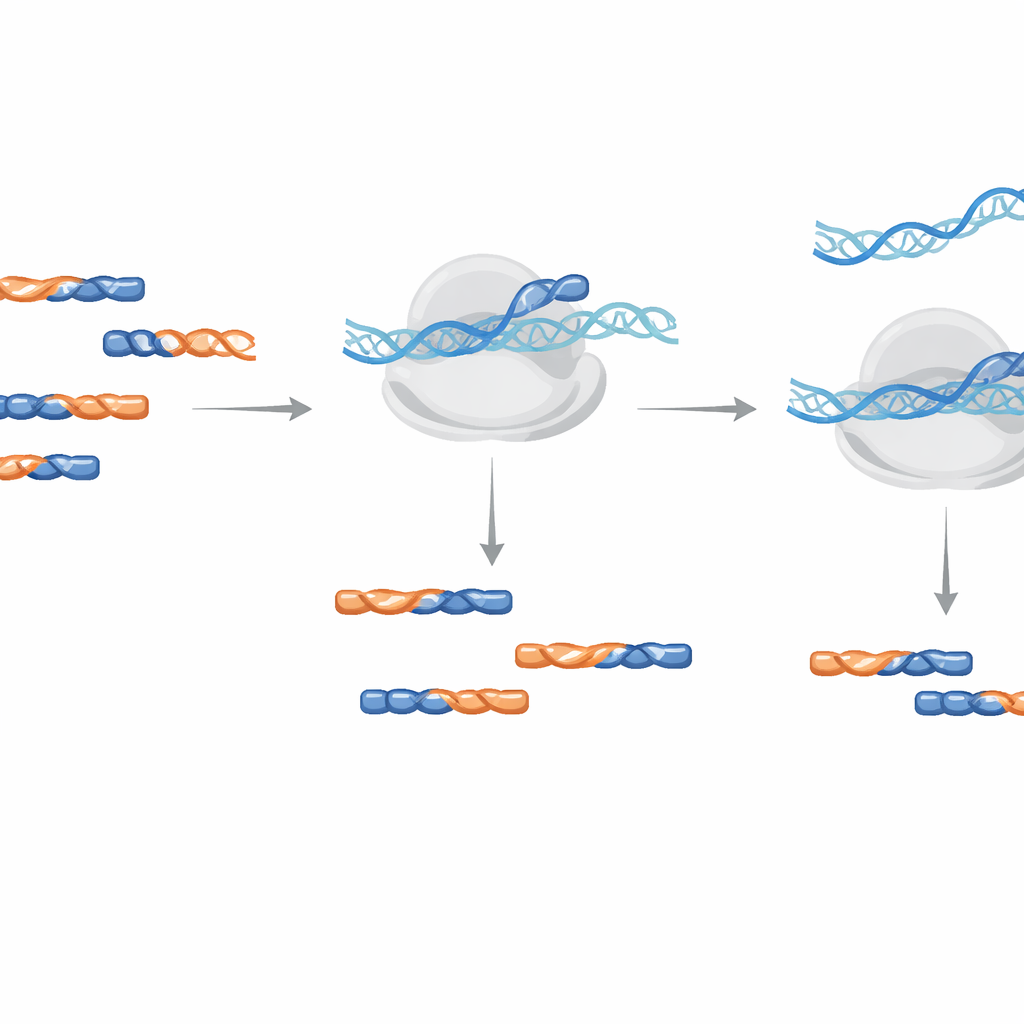
Een éénstaps opschoning tijdens amplificatie
In plaats van verontreinigingen fysiek uit het monster te verwijderen, gebruikt de methode LNA-oligonucleotiden als blokkers tijdens de DNA-amplificatiestap die de sequencingbibliotheek opbouwt. De auteurs testten het toevoegen van deze blokkers tijdens de initiële reverse-transcriptie of tijdens latere PCR-amplificatie. Ze vonden dat toevoegen van LNA's tijdens amplificatie efficiënter was en lagere concentraties vereiste, en een testverontreiniging met meer dan duizendvoud verminderde terwijl het onafhankelijk van strandaardering werkte. Praktische ontwerptips zijn onder meer afwisselen van standaard DNA- en LNA-bouwstenen, een minimumlengte van 14 eenheden aanhouden voor de plant Arabidopsis, en het modificeren van het staartuiteinde zodat de blokker zelf niet per ongeluk verlengd kan worden.
Meer nuttige reads zonder het signaal te vervormen
Om de prestaties in de praktijk aan te tonen, ontwierp het team vijf LNA-blokkers die gericht waren op de meest voorkomende verontreinigingsgroepen die worden gezien onder typische kweekomstandigheden in Arabidopsis-planten. Toen ze dit mengsel tijdens bibliotheekamplificatie toevoegden, daalde het aandeel geïdentificeerde verontreinigingen met meer dan 30% en verdubbelde het aantal nuttige eiwitcoderende reads bijna. Cruciaal was dat bij vergelijking van geniveau-readcounts tussen bibliotheken met en zonder LNA-behandeling de waarden vrijwel perfect overeenkwamen, wat aangeeft dat de blokkers rommelige fragmenten verwijderden zonder het biologische signaal van echte mRNA-voetafdrukken te vervormen.
Wat dit betekent voor toekomstige experimenten
Dit werk toont aan dat een korte proefexperiment, gekoppeld aan een gebruiksvriendelijk analysekrijp en een kleine set op maat gemaakte LNA-blokkers, rommelige Ribo‑Seq-bibliotheken kan veranderen in veel schonere, informatievere datasets in een enkele pipetteringsstap. Onderzoekers krijgen meer betekenisvolle reads per run, wat kosten bespaart en experimenteel ontwerp vereenvoudigt, terwijl nauwkeurige metingen van hoe genen vertaald worden behouden blijven. De auteurs bieden ook kant-en-klare verontreinigingsprofielen en blokkerontwerpen voor veelvoorkomende plantomstandigheden, en suggereren dat vergelijkbare bronnen gebouwd kunnen worden voor vele organismen, waardoor hoogwaardige ribosoomprofilering toegankelijker wordt voor de onderzoeksgemeenschap.
Bronvermelding: Ricciardi, D.A., Peter, F.E. & Böhmer, M. Data-driven design of LNA-blockers for efficient contaminant removal in Ribo-Seq libraries. Sci Rep 16, 8565 (2026). https://doi.org/10.1038/s41598-026-43117-3
Trefwoorden: ribosoomprofilering, RNA-verontreinigingen, locked nucleic acids, opschoning van sequencingbibliotheken, regulatie van translatie