Clear Sky Science · nl
Herdenk context-engineering met een op aandacht gebaseerde architectuur
Waarom slimmere softwarehulpen ertoe doen
Elke klik die u doet in een zakelijke applicatie—inloggen, een bestand uploaden, een rapport draaien—laat een spoor achter. Als software betrouwbaar uw volgende stap kon voorspellen, zou het data vooraf kunnen laden, snelkoppelingen kunnen voorstellen en vrijwel onmiddellijk reageren. Dit artikel verkent een nieuwe manier om computers te leren deze actiesporen zo goed te begrijpen dat digitale assistenten kunnen anticiperen op wat u daarna gaat doen, wat u probeert te bereiken en wanneer u op het punt staat af te sluiten.
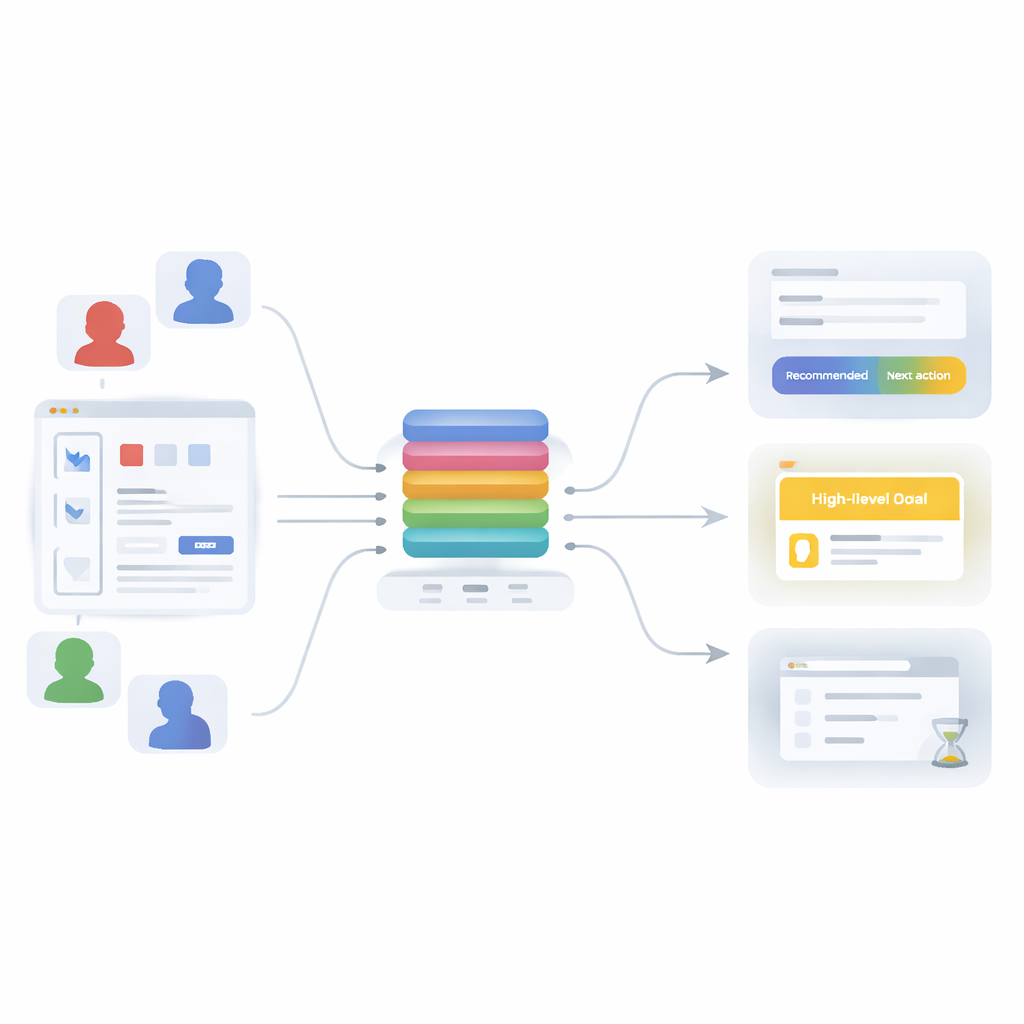
Van eenvoudige ketens naar rijke patronen
Veel bestaande systemen die de volgende stap van een gebruiker raden, vertrouwen op Markov-ketens, een klassiek wiskundig hulpmiddel dat bij de voorspelling alleen naar de meest recente actie kijkt. Hoewel snel en handig, faalt deze "één-stap-geheugen"-benadering in echte werkomgevingen, waar taken zoals het bouwen van een machine-learning-pijplijn of het voorbereiden van een dashboard zich over vele stappen uitstrekken en verschillende tools omvatten. De auteurs betogen dat zulke eenvoudige modellen lange-afstandsstructuren missen, slechts één voorspellingsdoel tegelijk aankunnen en moeilijk te vergelijken zijn tussen studies omdat ze vaak afhangen van privélogs en ondoorzichtige keuzes voor datavoorschoonmaken.
Een nieuw blauwdruk voor multi-task learning
Om deze beperkingen te overwinnen introduceert het artikel een op aandacht gebaseerde transformer—dezelfde familie technieken achter moderne taalmodellen—heruitgedacht voor gebruikersgedrag. In plaats van slechts één ding te leren, wordt het model getraind om drie gerelateerde taken tegelijk op te lossen: het voorspellen van de volgende actie (welke API een gebruiker zal aanroepen), het afleiden van het algemene doel van de sessie (zoals het uitvoeren van een machine-learning-workflow, data-analyse, gebruiksbeheer of het maken van snelle visualisaties), en het bepalen of de huidige stap waarschijnlijk de laatste in de sessie is. Alle drie taken delen een gemeenschappelijke "backbone" die een korte geschiedenis van recente acties omzet in een enkele, rijke representatie van wat er gaande is, die vervolgens wordt gevoed aan drie kleine predictiemodules.
Het opbouwen van een realistisch testgevoel in silico
Aangezien echte bedrijfsactiviteitslogs vaak gevoelig zijn en moeilijk te delen, bouwen de auteurs een verfijnde gesimuleerde omgeving die nabootst hoe data-professionals een groot intern platform gebruiken. Ze definiëren 100 verschillende API's gegroepeerd in 10 functionele gebieden, waaronder authenticatie, data-invoer, verwerking, modeltraining, visualisatie, export en administratie. Vier gebruikerspersona's—datawetenschappers, business-analisten, ontwikkelaars en power users—volgen karakteristieke maar onvolmaakte workflows, met waarschijnlijkheden die zowel routinegedrag als incidentele omwegen weerspiegelen. De resulterende dataset bevat 2.000 gebruikerssessies en 20.000 API-aanroepen, met sessiedoelen zoals "machine-learningpijplijn" en "snelle visualisatie" die herkenbare paden opleveren, zoals inloggen, data laden, verwerken, een grafiek maken en het resultaat exporteren.
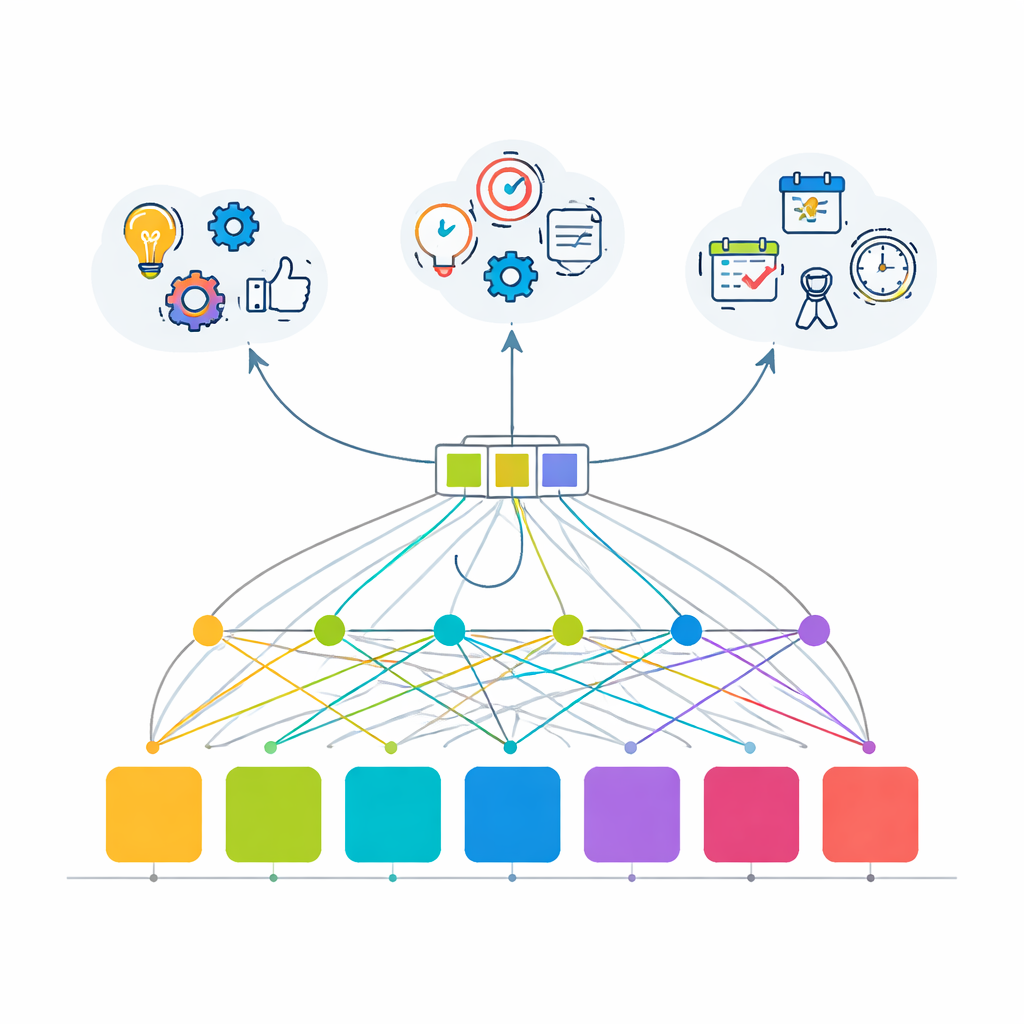
Hoe goed het model leert te anticiperen
Getraind in deze gestructureerde maar gevarieerde omgeving toont het transformer-model dat aandacht-gebaseerd leren de verborgen regelmatigheden in gebruikersgedrag veel beter kan vastleggen dan oudere methoden. Voor de hoofddoelstelling—het raden van de allereerste volgende API-aanroep uit 100 keuzes—krijgt het model bijna 80% van de keren het antwoord precies goed, en plaatst het de juiste keuze in zijn top vijf suggesties meer dan 99,9% van de tijd, een sprong van meer dan vier keer ten opzichte van een basale Markov-keten. Tegelijkertijd identificeert het model het algemene sessiedoel van de gebruiker correct in ongeveer 82% van de gevallen en detecteert het bijna perfect wanneer een sessie op het punt staat te eindigen. De auteurs benadrukken ook dat het model relatief compact en efficiënt is, waardoor gebruik in realtime haalbaar is voor live-assistenten die moeten reageren zonder merkbare vertraging.
Gereedschap voor anderen om te hergebruiken en uit te breiden
Om hun aanpak meer te maken dan een eenmalig experiment, brengen de auteurs een open-source softwarepakket uit, genaamd context-engineer, samen met de volledige gesimuleerde dataset. Met deze middelen kunnen andere onderzoekers en praktijkmensen de gerapporteerde resultaten reproduceren, alternatieve modellen op een gedeelde benchmark testen of hun eigen interne logs aansluiten door acties en sessielabels te mappen naar een eenvoudig numeriek formaat. Deze openheid pakt een belangrijke belemmering in het veld aan, waar veel eerdere systemen niet eerlijk vergeleken of hergebruikt konden worden omdat hun data en code niet beschikbaar waren.
Wat dit betekent voor dagelijkse gebruikers
Voor niet-specialisten is de belangrijkste conclusie dat het artikel een praktisch recept biedt om digitale tools gevoeliger te maken voor wat u als gebruiker nodig heeft. Door gezamenlijk te leren wat mensen proberen te doen, wat ze waarschijnlijk als volgende zullen klikken en wanneer ze afronden, zet het voorgestelde transformer-gebaseerde systeem gebruikersgeschiedenis om in een vorm van contextbewustzijn. In echte toepassingen zou dit kunnen betekenen: chatbots die het volgende rapport klaarzetten voordat u erom vraagt, analyseplatforms die zinvolle vervolgstappen voorstellen, en bedrijfsdashboards die wachtijden geruisloos verkorten. Hoewel de huidige studie is gebaseerd op gesimuleerde data en getest moet worden op echte logs, legt het een duidelijke, reproduceerbare basis voor het bouwen van slimmere, meer anticiperende softwarehulpen op allerlei digitale platforms.
Bronvermelding: Yin, Y. Rethink context engineering using an attention-based architecture. Sci Rep 16, 8851 (2026). https://doi.org/10.1038/s41598-026-43111-9
Trefwoorden: voorspelling van gebruikersgedrag, sequentiële aanbeveling, aandachtsgebaseerde transformer, proactieve digitale assistenten, context-engineering