Clear Sky Science · nl
Aanpakken van het probleem van databalans in machine-learningmodellen voor zeldzame en ontwrichtende uitvalgebeurtenissen
Waarom betere stormvoorspellingen voor u belangrijk zijn
Als een grote storm de stroom uitdoet, ervaren we dat op zeer persoonlijke manieren: geen licht, geen verwarming, bederf van voedsel en weggevallen communicatie. Nutsbedrijven proberen deze uitval van tevoren te voorspellen zodat ze reparatieteams kunnen inzetten en mensen veilig kunnen houden. Maar de ergste stormen zijn zeldzaam, wat betekent dat er verrassend weinig gegevens over hen beschikbaar zijn. Deze studie laat zien hoe een nieuw soort kunstmatige intelligentie realistische zeldzame stormen kan "verzinnen", de hiaten in onze gegevens kan opvullen en uitvalvoorspellingen nauwkeuriger kan maken wanneer het het meest belangrijk is.
De uitdaging van leren van zeldzame rampen
De meeste stroomuitval wordt veroorzaakt door het weer, vooral orkanen, nor’easters, sneeuw- en ijstormen en zware onweersbuien. Deze gebeurtenissen worden intenser naarmate het klimaat opwarmt, waardoor verouderde elektriciteitsnetten extra onder druk komen te staan. Toch zijn de meest verwoestende stormen per definitie ongebruikelijk. Traditionele statistische tools en machine-learningmodellen leren doorgaans het beste van de vele milde en matige stormen en hebben moeite met de handvol echt extreme gevallen. Deze onbalans in de gegevens leidt tot onderschattingen van schade precies op het moment dat nutsbedrijven het meest betrouwbare aanwijzingen nodig hebben.
Computeres leren nieuwe stormen maken
Om deze onbalans te overwinnen, bouwen de auteurs een systeem dat synthetische stormen genereert—dat wil zeggen: door de computer gemaakte gebeurtenissen die eruitzien en zich gedragen als echte stormen maar geen kopieën zijn van één enkele gebeurtenis uit het verleden. Ze richten zich op Connecticut en representeren elke storm als een raster van 8 bij 15 cellen met 19 informatie-typen per cel, waaronder wind, regen, druk, turbulentie, vegetatie en het patroon van hoogspanningslijnen. Eerst groeperen ze 294 historische stormen in 12 clusters op basis van hoeveel en waar "probleempunten"—schadeplaatsen die reparatieteams moeten herstellen—voorkwamen. De zeldzame, hoogimpactstormen eindigen in vier kleine clusters die versterking nodig hebben.
Hoe het nieuwe AI-model realistische extremen bouwt
De kern van het raamwerk combineert twee moderne AI-instrumenten. Een variational autoencoder comprimeert elke meerlagige stormkaart tot een laag-dimensionale "latente" representatie die nog steeds belangrijke patronen bewaart, zoals sterkere winden langs de kust. In deze gecomprimeerde ruimte leert een diffusiemodel te beginnen met willekeurige ruis en dit geleidelijk te verfijnen tot een realistische storm, voorwaardelijk op welk uitval-ernstcluster is gevraagd. Het systeem screent vervolgens de gegenereerde stormen met behulp van een set metriek die hun statistieken vergelijkt met echte gebeurtenissen—niet alleen controle van individuele kenmerken zoals windsnelheid, maar ook hoe kenmerken samen bewegen, vastgelegd in correlatiepatronen. Alleen synthetische stormen die nauw aansluiten bij het fysieke en statistische gedrag van echte stormen in een bepaald cluster worden behouden.
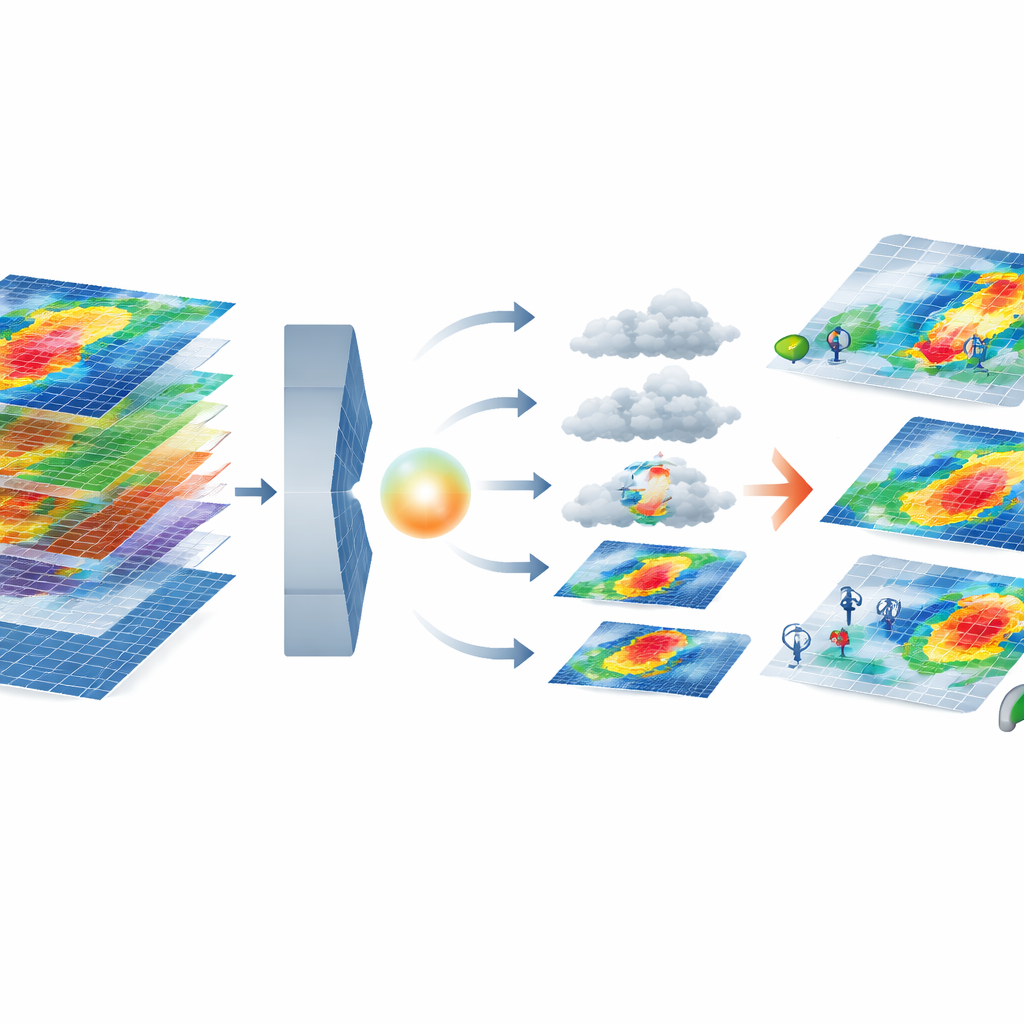
Synthetische stormen aan een test onderwerpen
De auteurs stellen dan de cruciale vraag: helpen deze synthetische stormen daadwerkelijk bij het voorspellen van uitval? Ze trainen een bestaand uitvalvoorspellingsmodel twee keer—eerst alleen op echte stormen en vervolgens op dezelfde gegevens verrijkt met zorgvuldig gescreende synthetische gebeurtenissen voor de zeldzame, hoogimpactclusters. Ze evalueren de prestaties met een strikte leave-one-storm-out test, die het voorspellen van nieuwe, ongeziene gebeurtenissen nabootst. Met synthetische verrijking daalt de structurele fout van het model scherp en verbetert de algemene fit. Voor de zeldzame, meest ontwrichtende stormen daalt de centrale root mean squared error met ongeveer 45% en stijgen samenvattende vaardigheidsmaatregelen zoals de Nash–Sutcliffe-efficiëntie van slechter-dan-baseline naar duidelijk bruikbare niveaus. Een vergelijking met een "willekeurige" augmentatie, die synthetische stormen toevoegt zonder kwaliteitscontrole, laat veel kleinere of zelfs negatieve verbeteringen zien, wat het belang van rigoureuze filtering onderstreept.
Wat dit betekent voor toekomstige stormen
In eenvoudige bewoordingen laat deze studie zien dat het toestaan dat AI fysisch consistente extreme stormen verzint—en selectief zijn over welke verzonnen stormen je vertrouwt—uitvalvoorspellingen betrouwbaarder kan maken voor juist die gebeurtenissen die de meeste schade aanrichten. Door schaarse gegevens over zeldzame maar verwoestende weersomstandigheden aan te vullen, helpt de aanpak nutsbedrijven beter inschatten hoeveel schadeplaatsen ze zullen tegenkomen en waar. Hoewel aangetoond voor één staat en één type gevaar, kan dezelfde strategie worden uitgebreid naar bosbranden, overstromingen en andere natuurlijke bedreigingen, en biedt het een nieuwe manier om infrastructurele planning te versterken in een wereld met groeiende klimaatexcessen.
Bronvermelding: Azizi, M., Zhang, X., Yasenpoor, T. et al. Addressing the data imbalance issue in machine learning modeling of rare and disruptive outage events. Sci Rep 16, 8876 (2026). https://doi.org/10.1038/s41598-026-41838-z
Trefwoorden: synthetische stormgegevens, voorspelling van stroomuitval, diffusiemodellen, extreem weer, gegevensimbalans