Clear Sky Science · nl
Vroege opsporing van chronische nierziekte op basis van een SURD-verrijkt machine learning-model
Waarom het vroeg ontdekken van nierproblemen ertoe doet
Chronische nierziekte sluipt vaak geruisloos binnen en geeft weinig waarschuwingssignalen totdat de nieren al ernstig zijn aangetast. Simpele bloed- en urinetests kunnen echter jaren eerder problemen blootleggen, wanneer behandeling de achteruitgang kan vertragen of zelfs voorkomen. Deze studie onderzoekt een nieuwe manier om die routinematige testresultaten te doorzoeken met geavanceerde, maar interpreteerbare computermodellen, zodat mensen met hoog risico eerder kunnen worden gesignaleerd en artsen kunnen begrijpen waarom.
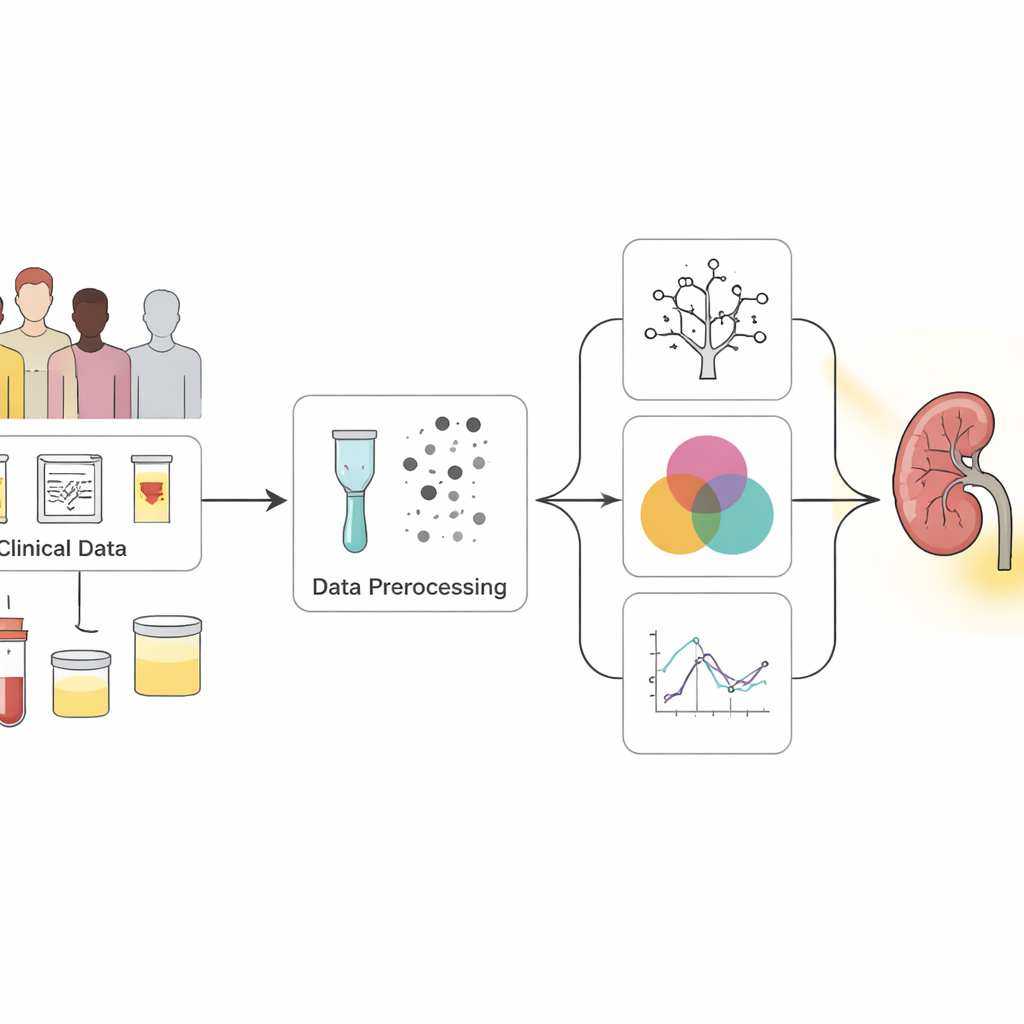
Van rommelige controlegegevens naar heldere signalen
De onderzoekers begonnen met een veelgebruikt openbaar dataset van 400 personen, van wie de meeste al waren gediagnosticeerd met chronische nierziekte. Elke persoon had 25 metingen, variërend van bloeddruk en bloedwaarden tot urineresultaten en medische voorgeschiedenis zoals diabetes en hoge bloeddruk. Veel gegevens waren incompleet, dus het team gebruikte zorgvuldige statistische technieken om ontbrekende waarden in te vullen in plaats van patiënten simpelweg te verwijderen. Ze brachten de data ook in balans zodat gezonde en zieke gevallen gelijkmatiger werden vertegenwoordigd, wat de computermodellen hielp beide groepen eerlijk te leren herkennen.
Voorbij eenvoudige correlaties kijken
De meeste medische voorspellingsinstrumenten behandelen elk testresultaat afzonderlijk: ze kijken hoe sterk één meting, zoals bloedsuiker, gekoppeld is aan ziekte. In het lichaam werken risicofactoren echter zelden alleen. Sommige tests geven bijna dezelfde informatie, terwijl andere pas informatief worden in combinatie. Om dit vast te leggen gebruikten de auteurs een kader genaamd SURD dat de bijdrage van elk kenmerk in drie delen opsplitst: informatie die gedeeld wordt met andere tests, unieke informatie, en informatie die alleen verschijnt wanneer kenmerken samenwerken. Dit stelde hen in staat laboratoriumwaarden en klinische bevindingen te groeperen in “uniek”, “redundant” en “synergistisch” voordat ze aan de voorspellingsmodellen werden gevoerd.
Veel modellen trainen en de meest betrouwbare kiezen
Met deze SURD-gebaseerde featuregroepen trainde het team tien verschillende machine learning-modellen, van eenvoudige beslisbomen tot complexere benaderingen zoals random forests en neurale netwerken. Ze vergeleken de prestaties wanneer modellen alle beschikbare kenmerken gebruikten versus alleen een gecombineerde set van unieke en synergistische kenmerken. Bij bijna alle modeltypen presteerde deze ingekorte, door SURD geleide featureset even goed of beter dan de volledige verzameling van 25 variabelen, en verbeterde vaak het evenwicht tussen het correct identificeren van zieke patiënten en het vermijden van valse alarmen. In het bijzonder behaalden boomgebaseerde modellen zoals random forests en boosted trees bijna perfecte scores op de oorspronkelijke dataset.
De methode testen in realistische ziekenhuisgegevens
Uitstekende prestaties op een klein benchmark-dataset kunnen misleidend zijn als een model faalt wanneer het aan meer gevarieerde patiënten wordt blootgesteld. Om dit te voorkomen valideerden de auteurs hun aanpak met een veel grotere ziekenhuisdatabase van meer dan 27.000 intensivecarepatiënten. Hier onderscheidde het random forest-model, gebouwd op de SURD-geselecteerde kenmerken, nog steeds patiënten met en zonder nierziekte met extreem hoge nauwkeurigheid. De prestaties overtroffen duidelijk die van een eenvoudigere beslisboom, wat aangeeft dat de methode kan generaliseren buiten een zorgvuldig samengestelde onderzoeksdataset naar rommeliger real-world gegevens.
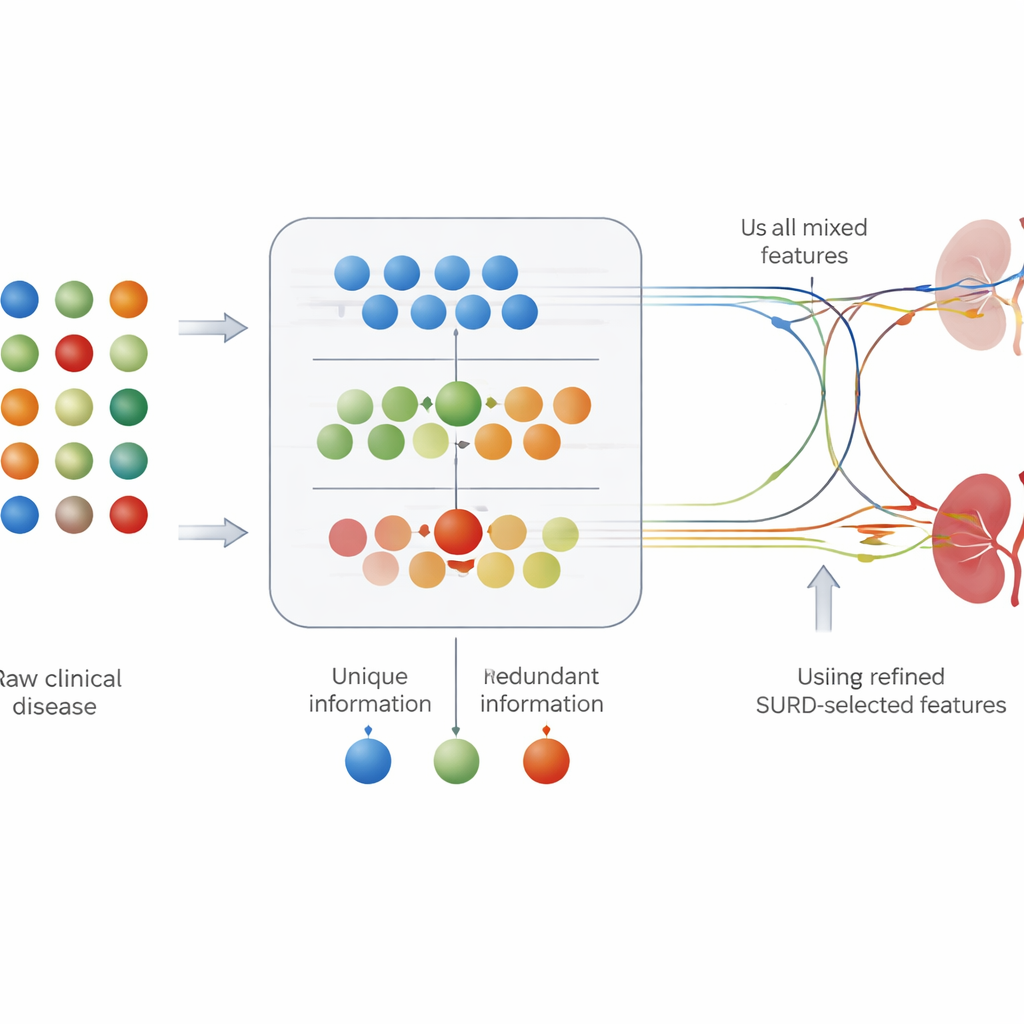
Zien welke tests belangrijk zijn en hoe
Nauwkeurigheid alleen is niet genoeg voor klinisch gebruik; artsen moeten ook weten welke testresultaten een voorspelling aandrijven. De studie combineerde SURD met moderne uitlegmethoden die elke feature een bijdrage toekennen aan de beslissing van het model voor een specifieke patiënt. Deze analyse benadrukte bekende risicomarkers, zoals serumcreatinine (een directe indicator van nierfunctie), hemoglobinewaarden, urineconcentratie en het voorkomen van diabetes of hoge bloeddruk. Interessant genoeg liet SURD zien dat sommige van deze factoren vooral in samenhang met anderen werken, terwijl creatinine eruit springt als een op zichzelf sterk informatief signaal. Samen bieden deze technieken zowel een globaal beeld van op welke tests het model steunt als patiëntniveau-verklaringen waarom een bepaalde persoon als hoog risico wordt voorspeld.
Wat dit betekent voor de dagelijkse zorg
Kort gezegd laat de studie zien dat het mogelijk is een risicocalculator voor nierziekte te bouwen die zowel zeer nauwkeurig als redelijk transparant is. Door overlappende informatie te scheiden van echt unieke informatie in routinematige laboratorium- en voorgeschiedenisgegevens, maken de door SURD geleide modellen scherpere voorspellingen zonder een mysterieus black box-systeem te worden. Hoewel verder werk nodig is bij bredere en diversere patiëntengroepen, zou deze aanpak uiteindelijk clinici kunnen helpen nierproblemen eerder te signaleren, de aandacht te richten op de meest informatieve tests en patiënten op eenvoudige wijze uit te leggen welke aspecten van hun gezondheid hun nieren in gevaar brengen.
Bronvermelding: Xue, N., Bai, T., Jia, X. et al. Early detection of chronic kidney disease based on a SURD-enhanced machine learning model. Sci Rep 16, 10444 (2026). https://doi.org/10.1038/s41598-026-41050-z
Trefwoorden: chronische nierziekte, nier-risicovoorspelling, medische machine learning, uitlegbare AI, elektronische medische dossiers