Clear Sky Science · nl
Dynamische machine learning-benadering voor werklastvoorspelling in cloudomgevingen
Waarom slimme verkeersvoorspelling ertoe doet
Elke keer dat u een video streamt, een groot sportevenement online volgt of winkelt tijdens een flash sale, kunnen duizenden anderen op hetzelfde moment klikken. Achter de schermen proberen cloud-datacenters websites snel te houden zonder geld te verspillen aan ongebruikte machines. Dit artikel behandelt een eenvoudige vraag met grote praktische gevolgen: hoe kunnen cloudsystemen plotselinge golven van webverkeer vroeg genoeg voorspellen om servers precies op tijd aan of uit te zetten, in plaats van te gissen en te veel te betalen?
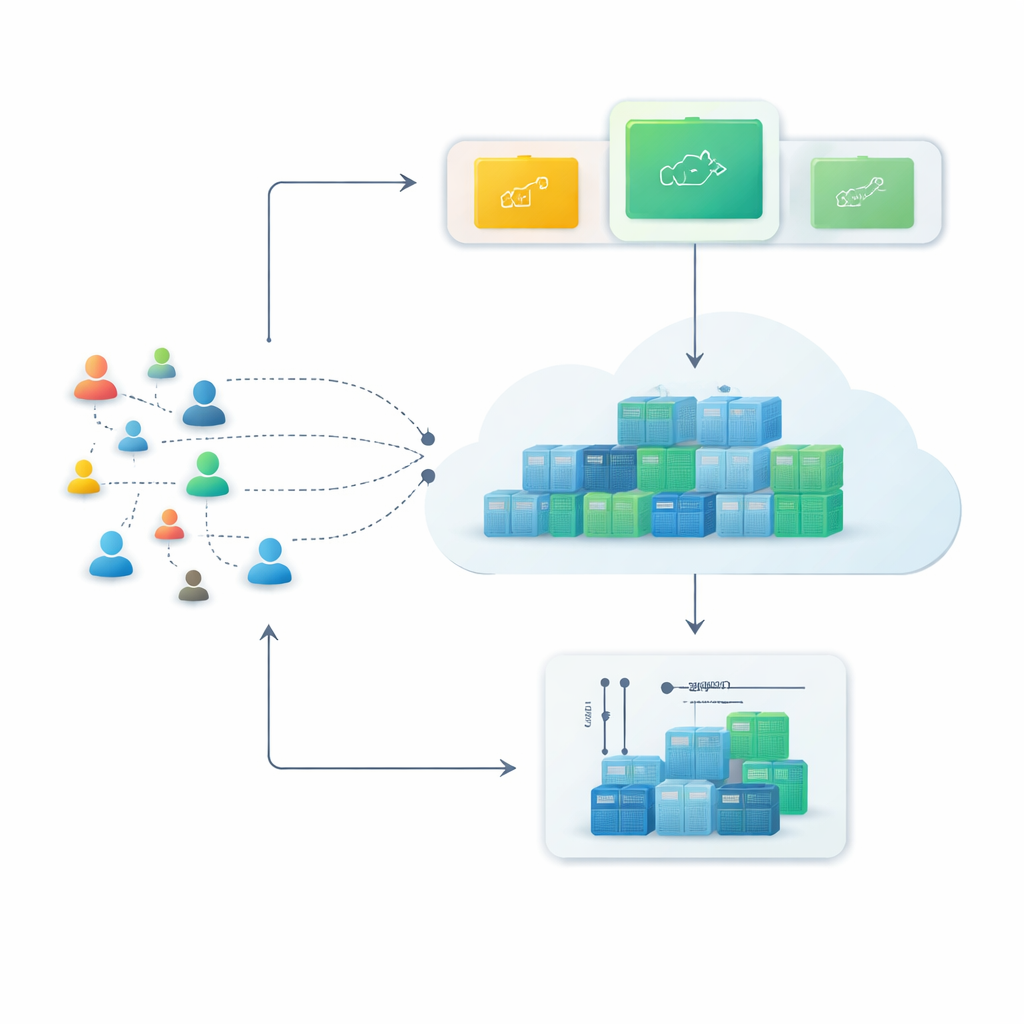
Van stijve servers naar flexibele containers
Moderne cloudplatforms vertrouwen steeds vaker op containers, kleine softwarepakketten die binnen seconden gestart of gestopt kunnen worden. In vergelijking met traditionele virtuele machines zijn containers lichter en kunnen ze dichter op elkaar worden geplaatst, wat ze ideaal maakt voor diensten die tijdens drukke uren snel moeten groeien en daarna weer krimpen. Deze flexibiliteit betaalt zich echter alleen uit als het systeem problemen van tevoren kan zien—als het kan voorspellen hoeveel webverzoeken de komende minuten zullen binnenkomen en het juiste aantal containers tijdig klaar kan zetten.
Waarom one-size-fits-all-voorspelling faalt
Vervolgonderzoek heeft veel verschillende manieren geprobeerd om webverkeer te voorspellen, van klassieke statistiek tot diepe neurale netwerken. Sommige methoden werken goed wanneer de vraag gedurende de dag geleidelijk verandert; andere zijn beter wanneer het verkeer onvoorspelbaar springt, zoals tijdens een wedstrijd in het Wereldkampioenschap. Het probleem is dat geen enkele methode altijd de beste is. Als beheerders één favoriet model kiezen en daaraan vasthouden, kan de nauwkeurigheid sterk dalen telkens wanneer het gebruikersgedrag verandert, wat leidt tot trage sites of tot rijen onderbenutte machines die ongemerkt geld en energie verbruiken.
Een leerlus die zich blijft aanpassen
Om dit te overwinnen stellen de auteurs een gesloten-lusframework voor dat zij Monitor–Train–Test–Deploy noemen. Het idee is om voorspelling zelf te behandelen als een levend proces. Eerst legt het systeem continu binnenkomende webverzoeken vast in een tijdgestempelde geschiedenis. Vervolgens traint het meerdere verschillende voorspellingsmethoden parallel, die elk proberen patronen in die recente geschiedenis te leren. Daarna test het deze kandidaatmodellen op de meest recente data en scoort ze op basis van hoe ver hun schattingen van de werkelijkheid afwijken. Alleen het best presterende model krijgt de taak om live voorspellingen te doen, die bepalen hoeveel containers er moeten draaien. Zodra nieuw verkeer binnenkomt, herhaalt de lus zich: als de voorspellingsfouten twee keer achter elkaar boven een toelaatbaar niveau uitkomen, traint het systeem automatisch opnieuw en kan het de controle overdragen aan een ander model.
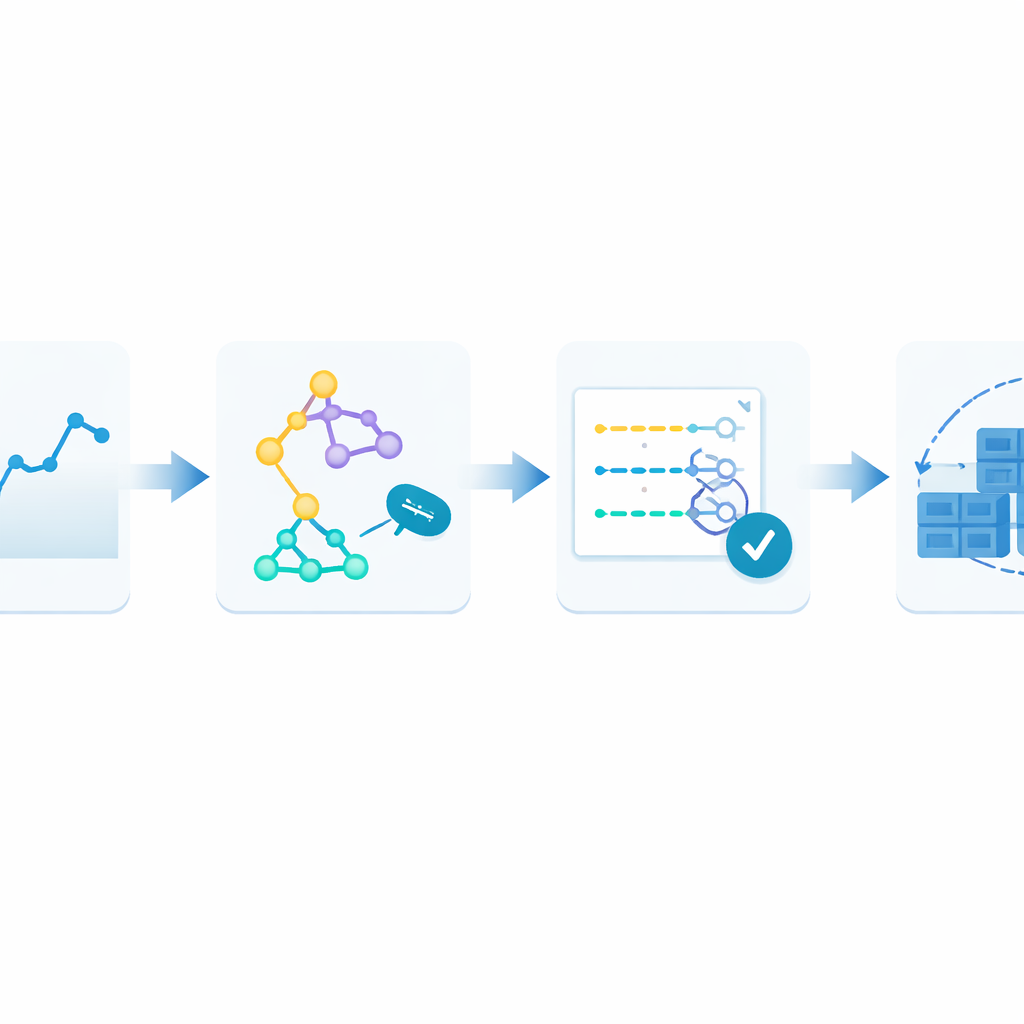
Het framework op de proef gesteld
De onderzoekers evalueerden deze aanpak met zowel synthetische als echte tracés van webactiviteit. Ze genereerden meerdere geïdealiseerde patronen—gladde belvormige curves, geleidelijk stijgende belastingen met verschillende snelheden en zeer grillig verkeer—en gebruikten ook gegevens van de officiële Wereldbekerwebsites uit 1998 en 2018, waar de interesse plotseling piekte. Voor elk geval vergeleken ze drie of vier bekende voorspellingsinstrumenten, waaronder een statistiekgebaseerde methode, een support-vector-model, een ensemble van beslissingsbomen en, in latere experimenten, een populair type recurrent neuraal netwerk. De kernbevinding was dat de “winnaar” met de situatie mee veranderde: eenvoudige statistische modellen blonken uit wanneer de vraag stabiel was, terwijl op leren gebaseerde methoden duidelijk superieur waren wanneer het verkeer wild en bursty werd.
Winst in nauwkeurigheid en efficiëntie
Door continu over te schakelen naar het model dat op dat moment het beste bij het waargenomen gedrag paste, verminderde het framework de voorspellingsfouten met maximaal ongeveer 15 procent vergeleken met vasthouden aan een vast model. Net zo belangrijk deed het dat zonder alle modellen continu te laten draaien. Tijdens live-operatie is slechts één voorspeller actief; de anderen worden periodiek opnieuw getraind en gecontroleerd, waardoor de rekenlast beperkt blijft. De auteurs introduceren ook een geleidelijk verscherpend drempelcriterium voor wanneer opnieuw getraind moet worden, zodat het systeem minder tolerant wordt voor herhaalde fouten en het risico op lange periodes van slechte voorspelling afneemt.
Wat dit betekent voor alledaagse cloudgebruikers
In praktische termen toont de studie aan dat cloudplatforms intelligenter kunnen worden beheerd door voorspellingsmodellen het tegen elkaar te laten opnemen en hun keuze in de loop van de tijd aan te passen. Voor gebruikers kan dat zich vertalen in soepelere online-ervaringen tijdens grote evenementen en minder vertragingen wanneer onverwacht veel mensen tegelijk komen. Voor providers belooft het een zuiniger gebruik van computerbronnen, lagere bedrijfskosten en minder verspilde energie. In plaats van te wedden op één slim algoritme pleit dit werk voor een flexibel regelmechanisme dat blijft leren, testen en herzien hoe het de vraag in een steeds onvoorspelbaardere digitale wereld anticipeert.
Bronvermelding: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Trefwoorden: cloud werklastvoorspelling, autoscaling, containers, machine learning, tijdrije