Clear Sky Science · nl
Een privacybeschermend multi-gebruiker retrievalsysteem voor multimodale kunstmatige intelligentie
Waarom het privé houden van slimme zoekopdrachten ertoe doet
Veel van ons vertrouwen nu op cloudgebaseerde kunstmatige intelligentie om onze foto’s, documenten en zelfs medische scans te doorzoeken. Deze systemen zijn krachtig omdat ze zowel plaatjes als woorden kunnen begrijpen, maar ze roepen ook een lastige vraag op: hoe kunnen we van dit gemak genieten zonder de betekenis van onze meest gevoelige gegevens prijs te geven aan verre servers? Dit artikel introduceert PMIRS, een nieuw systeem dat erop gericht is veel gebruikers in staat te stellen te zoeken in gemengde beeld–en–tekstcollecties terwijl hun informatie verborgen blijft voor de cloudmachines die die zoekopdrachten uitvoeren.
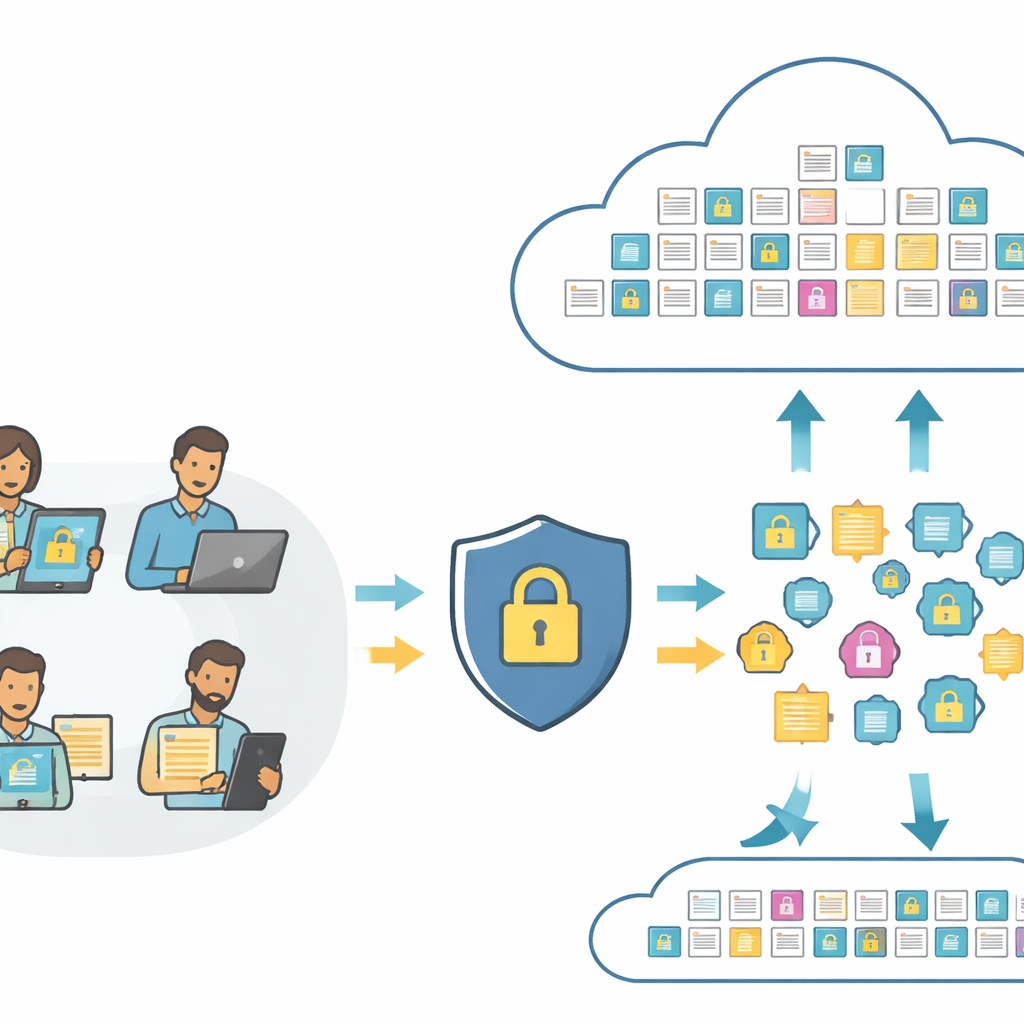
Zoeken in beelden en tekst zonder hun betekenis te tonen
In het hart van moderne zoektools staan "embeddings"—numerieke vingerafdrukken die de inhoud van een foto of een zin vastleggen zodat een computer ze kan vergelijken. Standaardsystemen sturen deze vingerafdrukken rechtstreeks naar de cloud, waar ze geanalyseerd of zelfs misbruikt kunnen worden. PMIRS herschikt deze pijplijn. Gebruikers sturen eerst hun ruwe afbeeldingen en tekst naar een lokale laag, die ze omzet in vingerafdrukken met behulp van een compact visie-en-taalmodel. Voordat er iets de kant van de gebruiker verlaat, worden de vingerafdrukken op een gecontroleerde manier vervormd en daarna versleuteld. De cloud ziet alleen deze beschermde vingerafdrukken en volledig versleutelde kopieën van de opgeslagen gegevens, en kan toch matching uitvoeren en de beste resultaten teruggeven.
Leren van veel gebruikers zonder hun data te centraliseren
Het trainen van een goed beeld–tekstmodel vereist normaal gesproken het verzamelen van enorme hoeveelheden gelabelde voorbeelden op één plek—een duidelijk privacyrisico. PMIRS gebruikt in plaats daarvan federated learning. In deze opzet wordt het onderliggende model, afgeleid van de bekende CLIP-architectuur, naar veel apparaten gestuurd. Elk apparaat traint lokaal op zijn eigen privé beeld–tekstparen en stuurt alleen bijgewerkte modelgewichten terug, die zelf ook versleuteld zijn. Een centrale server neemt deze updates gemiddeld samen om een gedeeld model te verbeteren zonder ooit de ruwe foto’s of beschrijvingen van een gebruiker te zien. De auteurs verkleinen en verfijnen het model verder via een gefaseerd "distillatie"-proces dat onnodige onderdelen snoeit terwijl de nauwkeurigheid behouden blijft, waardoor het systeem lichtgewicht genoeg wordt voor praktische inzet.
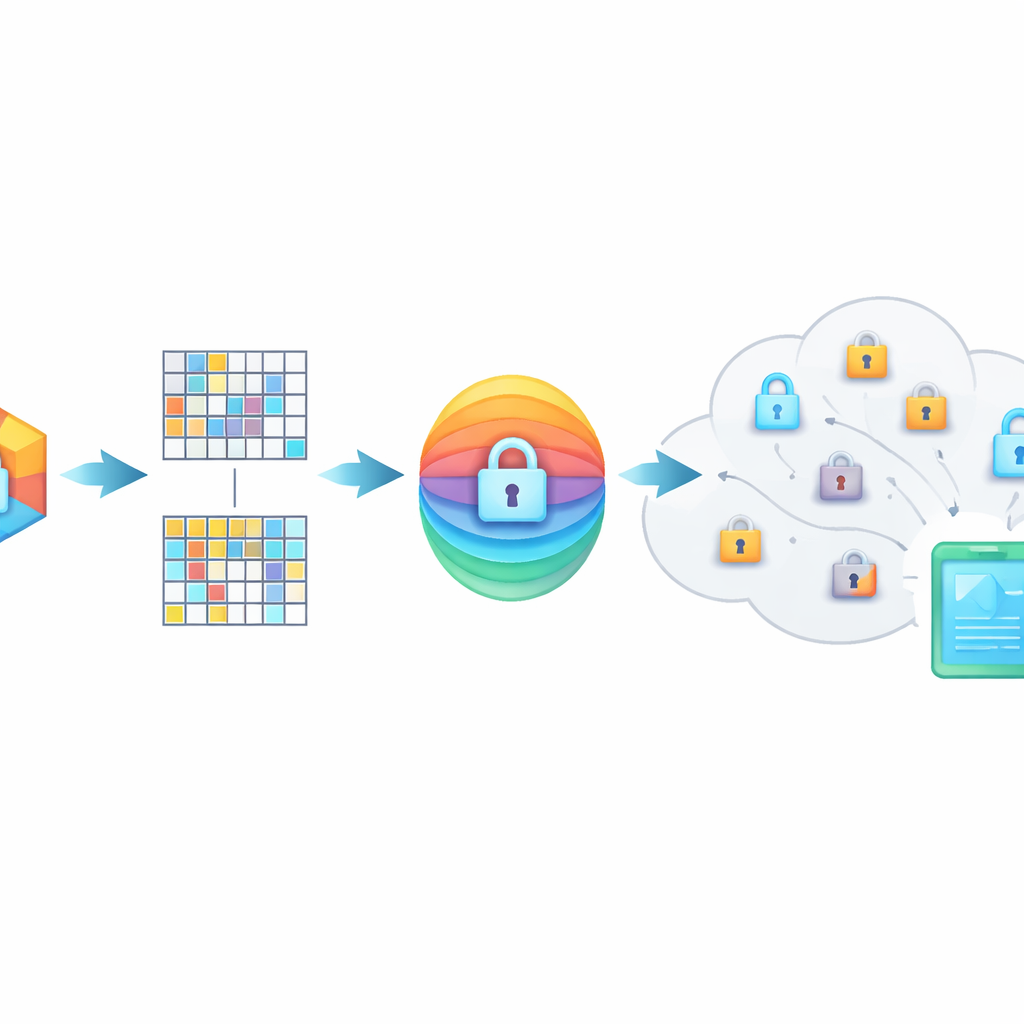
De betekenis verbergen in vervormde vingerafdrukken
PMIRS beschermt queries met een tweelaagse schild. Ten eerste wordt elke vingerafdruk in blokken verdeeld en wordt elk blok getransformeerd met een geheime matrix, plus een zorgvuldig ontworpen ruispatroon. Deze vervorming verbergt de oorspronkelijke structuur van de data, maar is zo opgezet dat wanneer twee verwante items beide getransformeerd zijn, hun gelijkenis gelijk blijft. Ten tweede wordt het resultaat versleuteld met de veelgebruikte AES-methode, met sleutels die nooit openlijk over het netwerk worden gestuurd. Voor situaties waarin de ene persoon in de data van een andere persoon moet zoeken—zoals een arts die een specialist raadpleegt—gebruikt het systeem een Diffie–Hellman sleuteluitwisselingsprotocol zodat ze gedeelde geheimen kunnen overeenkomen zonder deze bloot te stellen aan afluisteraars.
Hoe goed het systeem in de praktijk presteert
Om te testen of deze beschermingen niet te zwaar wegen op de prestaties, bouwden de onderzoekers een benchmark die alledaagse afbeeldingen koppelt aan korte natuurlijke-taalzinnen—meer in lijn met hoe mensen dingen werkelijk beschrijven dan met enkelwoordlabels. Ze vergeleken PMIRS met een standaard CLIP-gebaseerde zoekoplossing over drie thema’s: natuurlijke scènes, gefabriceerde objecten en activiteiten of landschappen. Over vele repositorygroottes vond PMIRS consequent een beter evenwicht tussen het vinden van alle juiste resultaten (recall) en het vermijden van valse treffers (precision), leidend tot een gemiddelde F1-score—een gecombineerde maat voor nauwkeurigheid—ongeveer 7,7% hoger dan de baseline. Belangrijk is dat reactietijden onder ongeveer 180 milliseconden bleven, snel genoeg voor interactieve toepassingen, en vaak iets sneller dan de onbeveiligde baseline ondanks de extra beschermingsstappen.
Wat dit betekent voor dagelijkse gebruikers
Kort gezegd laat PMIRS zien dat het mogelijk is cloud-zoektools te bouwen die beelden en tekst goed begrijpen, veel gebruikers tegelijk bedienen en toch de betekenis van ieders gegevens buiten bereik van de cloudprovider houden. Door lokaal trainen, slimme vervorming van vingerafdrukken, sterke versleuteling en veilige sleuteluitwisseling te combineren, biedt het systeem een end-to-end privacybeschermende pijplijn in plaats van slechts één fase te beveiligen. Hoewel het nog niet elke mogelijke aanval dekt en verdere verfijning en praktijktesten nodig heeft, wijst dit werk op toekomstige diensten—zoals medische beeldzoekopdrachten, klantenservice-bots of bedrijfsarchieven—waar mensen kunnen profiteren van rijke, multimodale AI-zoekfunctionaliteit met veel minder zorgen dat hun persoonlijke inhoud wordt onthuld of misbruikt.
Bronvermelding: Gao, Y., Luo, W., Wang, C. et al. A privacy-preserving multi-user retrieval system for multimodal artificial intelligence. Sci Rep 16, 10348 (2026). https://doi.org/10.1038/s41598-026-40734-w
Trefwoorden: privacybeschermende AI, multimodale retrieval, federated learning, gecodeerd zoeken, veilige cloudcomputing