Clear Sky Science · nl
Clustering-cum-regressiemodel en prestatieanalyse voor vroege voorspelling van hartziekten
Waarom vroeg hartproblemen opsporen ertoe doet
Hartziekten ontwikkelen zich vaak geruisloos over vele jaren, en tegen de tijd dat duidelijke symptomen verschijnen kan er al schade zijn ontstaan. Deze studie onderzoekt hoe alledaagse draagbare sensoren en slimme data-analyse samen waarschuwingssignalen eerder kunnen opsporen, zodat artsen en patiënten meer tijd krijgen om in te grijpen. Door twee verschillende manieren om naar gezondheidgegevens te kijken te combineren, willen de onderzoekers de voorspellingen nauwkeuriger maken zonder de technologie in echte klinische omgevingen moeilijker toepasbaar te maken.
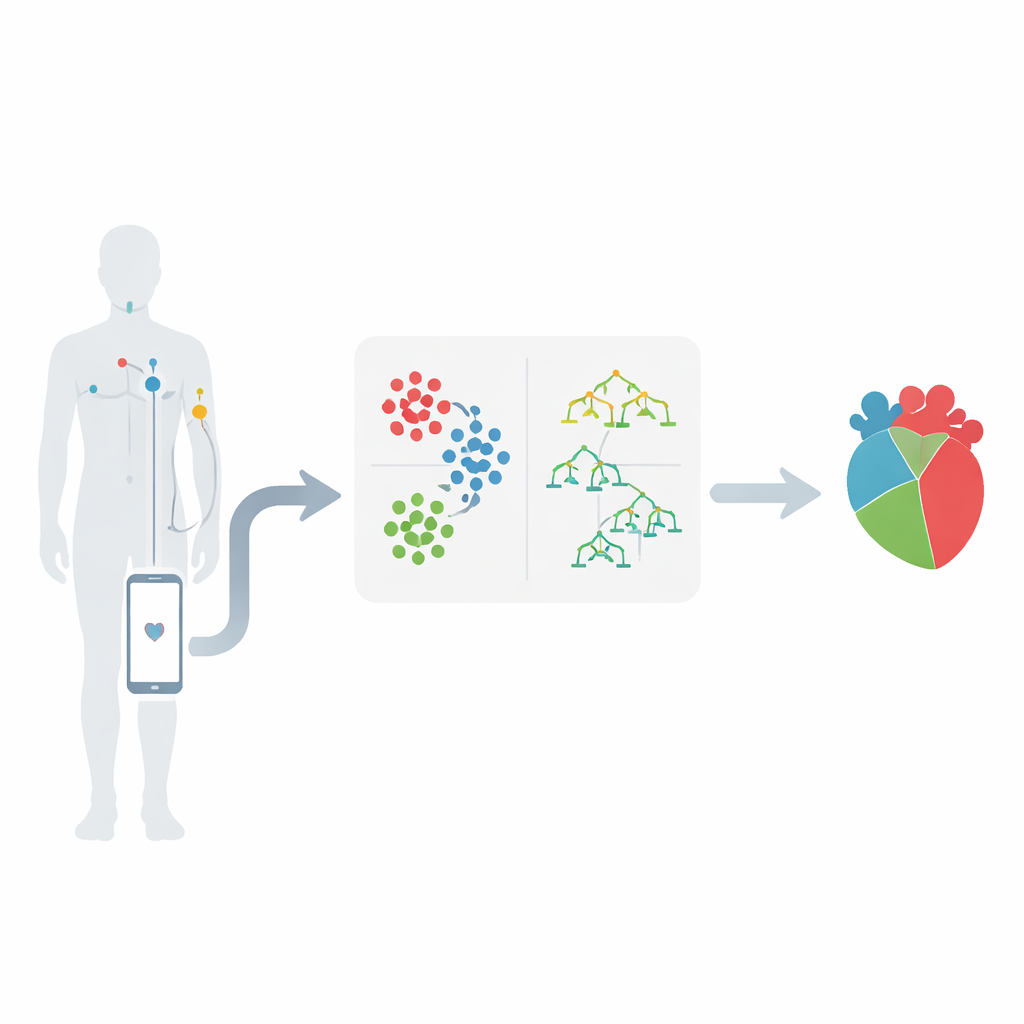
Van lichaamsensoren naar slimme waarschuwingen
Het werk speelt zich af in de wereld van draadloze body area networks, waar kleine sensoren op de huid signalen volgen zoals hartslag, bloeddruk en de elektrische activiteit van het hart. Deze sensoren sturen metingen naar een mobiel apparaat, dat ze doorstuurt naar een medisch centrum voor analyse. Het belangrijkste idee is dat deze stroom getallen patronen kan onthullen die wijzen op zich ontwikkelende hartproblemen, lang voordat een crisis optreedt. De auteurs concentreren zich op een bekend hartziektedataset en selecteren 12 belangrijke kenmerken, waaronder type pijn op de borst, bloeddruk, cholesterol, bloedsuiker, inspanningsgeïnduceerde pijn op de borst en veranderingen die op een elektrocardiogram te zien zijn.
Verborgen groepen in patiëntgegevens vinden
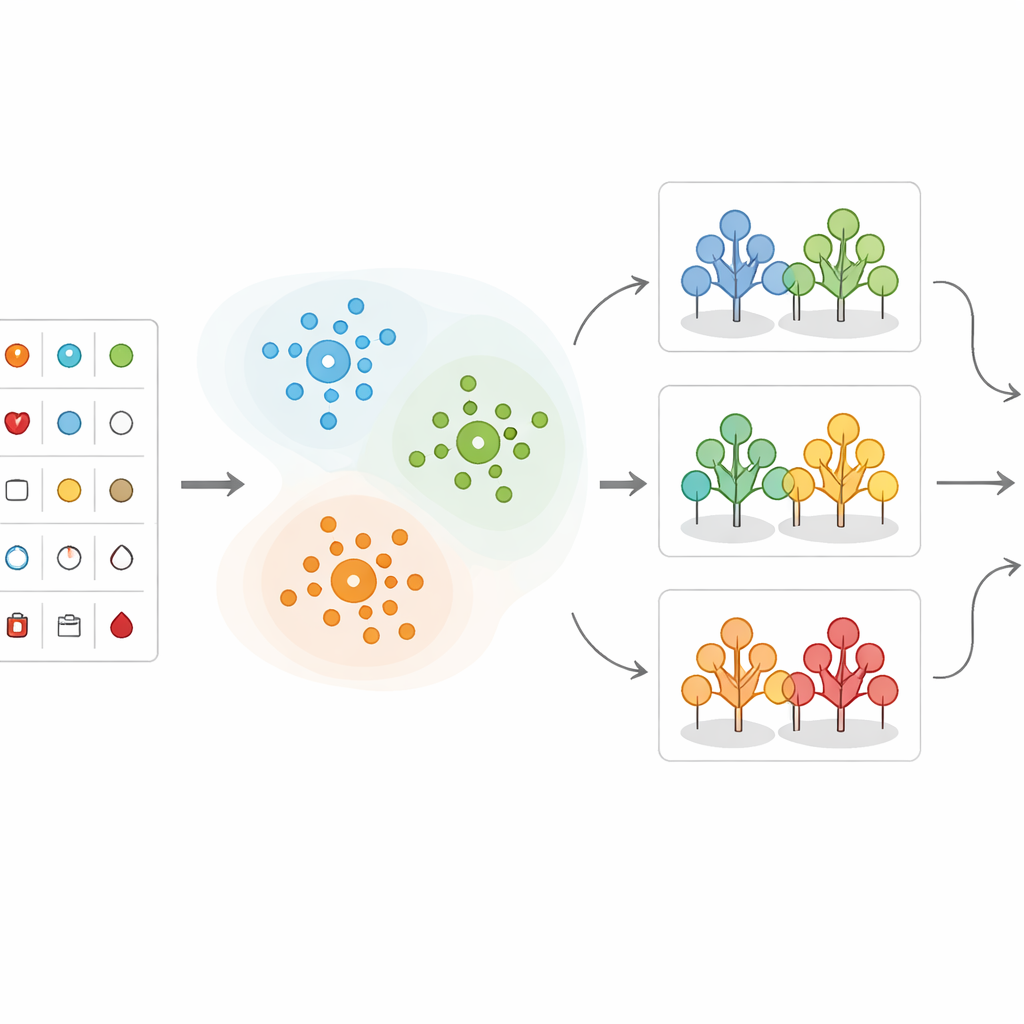
In plaats van alle patiëntgegevens direct in één voorspellingsformule te stoppen, groepeert het team eerst vergelijkbare patiënten. Ze gebruiken een methode genaamd K-means clustering, die mensen indeelt in clusters op basis van overeenkomsten in hun metingen, waarbij leeftijd een centrale rol speelt. Patiënten vallen bijvoorbeeld natuurlijk in groepen met zeer hoge bloeddruk, hoog cholesterol of specifieke patronen in harttesten. Deze groepeerstap helpt te benadrukken welke combinaties van metingen bijzonder zorgwekkend zijn. Het laat ook zien dat bepaalde bereiken — zoals een bloeddruk boven 150, cholesterol boven 300 of specifieke veranderingen in hartopnames — vaak samenhangen met veel hoger risico.
Machines trainen om risico te beoordelen
Nadat de gegevens zijn gegroepeerd, passen de onderzoekers verschillende machine-learningmethoden toe die uit eerdere gevallen leren om te voorspellen of een nieuwe patiënt waarschijnlijk aanzienlijke hartziekte heeft. Ze vergelijken verschillende benaderingen, waaronder beslisbomen, k-nearest neighbors, support vector machines, logistieke regressie, Naïve Bayes en random forests. In hun hybride ontwerp wordt elke nieuwe patiënt eerst toegewezen aan de dichtstbijzijnde cluster; daarna maakt een random forest-model dat specifiek voor dat type patiënt is getraind de definitieve risicovoorspelling. De data worden zorgvuldig opgeschoond, geschaald en verdeeld in trainings- en testsets, en klasse-ongelijkheid (meer gezonde dan zieke patiënten) wordt aangepakt zodat de modellen niet bevooroordeeld raken richting de meerderheidsgroep.
Hoe goed het hybride model presteert
Om het succes te beoordelen kijkt de studie niet alleen naar de algehele nauwkeurigheid, maar ook naar hoe vaak het model zieke patiënten correct signaleert (recall), gezonde patiënten correct geruststelt (specificiteit) en beide doelen in balans houdt (F1-score en ROC–AUC). Eerdere studies met vergelijkbare gegevens bereikten vaak rond de 85 procent nauwkeurigheid en hadden moeite om deze fijnere maten te verbeteren. Hier bereikt de gecombineerde clustering-plus-random-forest aanpak ongeveer 91 procent nauwkeurigheid, met sterke recall en zeer hoge specificiteit. De betrouwbaarheidsintervallen voor dit model overlappen niet met die van de eenvoudigere methoden, wat suggereert dat de verbetering waarschijnlijk niet door toeval komt. Tegelijk blijft de rekentijd in een praktisch bereik — van milliseconden tot seconden — geschikt voor realtime of bijna-realtime monitoringsystemen.
Wat dit betekent voor patiënten en artsen
Simpel gezegd toont de studie aan dat computers eerst patiënten in betekenisvolle groepen laten indelen en vervolgens op maat gemaakte voorspellingsregels toepassen, vroegtijdige detectie van hartziekten kan aanscherpen. De methode is bijzonder veelbelovend voor continue monitoringopstellingen, waarbij draagbare sensoren op de achtergrond stil gegevens verzamelen. Hoewel de resultaten afkomstig zijn van een bescheiden, gestructureerde dataset in plaats van volledige klinische dossiers, en de auteurs waarschuwen voor mogelijke vertekeningen, is de boodschap duidelijk: slimmer gebruik van bestaande metingen kan artsen een betrouwbaarder vroegwaarschuwingssysteem bieden. Met verder onderzoek en grotere, rijkere datasets kan dit soort hybride analyse helpen ruwe sensorwaarden om te zetten in tijdige, gepersonaliseerde waarschuwingen die hartaanvallen en andere ernstige gebeurtenissen voorkomen voordat ze optreden.
Bronvermelding: Tolani, M., AlZahrani, Y., Suman, G. et al. Clustering-cum-regression based model and performance analysis for early prediction of heart disease. Sci Rep 16, 9494 (2026). https://doi.org/10.1038/s41598-026-40626-z
Trefwoorden: voorspelling van hartziekte, draagbare gezondheidssensoren, machine learning, clustering van medische gegevens, random forest-model