Clear Sky Science · nl
Exacte featurebotsingen in neurale netwerken
Wanneer verschillende beelden een slimme machine misleiden
Moderne kunstmatige-intelligentiesystemen kunnen gezichten herkennen, medische scans lezen en autonome voertuigen sturen. We weten al dat ze misleid kunnen worden door kleine, zorgvuldig aangebrachte veranderingen in een afbeelding. Dit artikel toont iets nog verrassenders: dezelfde netwerken kunnen ook blind zijn voor grote, voor de hand liggende wijzigingen en zeer verschillende beelden behandelen alsof het hetzelfde is. Begrijpen hoe en waarom dit gebeurt is essentieel als we AI-systemen willen die we echt kunnen vertrouwen.
Van kleine aanpassingen naar grote blinde vlekken
Diepe neurale netwerken drijven de doorbraken in visie, taal en veel andere gebieden aan. Vroeger onderzoek naar adversariale voorbeelden toonde aan dat een nauwelijks zichtbare wijziging in een afbeelding een netwerk met hoge zekerheid fout kan laten classificeren. Recente studies onthulden het omgekeerde probleem: sommige netwerken reageren nauwelijks op grote, voor de hand liggende veranderingen en geven nog steeds bijna identieke voorspellingen. In die gevallen "botsen" de intern geëxtraheerde features van twee zeer verschillende beelden, wat betekent dat het netwerk ze vrijwel op dezelfde manier representereert. Deze studie gaat dat idee veel verder en bewijst dat gangbare netwerken niet alleen benaderende botsingen hebben, maar dat er exacte featurebotsingen kunnen optreden, waarbij twee verschillende inputs precies naar dezelfde interne signalen worden afgebeeld.
Hoe botsingen in een netwerk ontstaan
Om deze botsingen uit te leggen kijken de auteurs onder de motorkap van neurale netwerken en richten zich op hun gewichtsmatrices, de getrainde getallen die lagen met elkaar verbinden. Een featurebotsing doet zich voor wanneer twee verschillende inputs dezelfde output op een laag produceren; zodra dat gebeurt, zien alle volgende lagen hetzelfde en kunnen ze de inputs niet meer uit elkaar houden. Wiskundig gebeurt dit wanneer het verschil tussen twee inputs in de "nulruimte" van de gewichten van een laag ligt: richtingen in de inputruimte die de laag volledig negeert. De auteurs tonen aan dat telkens wanneer een gewichtsmatrix een nuleigenwaarde heeft of afbeeldt van een ruimte met hogere dimensie naar een met lagere dimensie, zulke genegeerde richtingen moeten bestaan. Omdat de meeste realistische architecturen, inclusief populaire modellen voor classificatie, segmentatie en objectdetectie, veel van dergelijke lagen gebruiken, zijn botsingen geen zeldzame randgevallen maar bijna een onvermijdelijke eigenschap van deze netwerken.
Een nieuwe manier om botsende inputs te construeren
Vervolgmakend op dit inzicht introduceert het artikel een praktisch recept genaamd de nul-ruimtezoektocht. In plaats van te vertrouwen op trial-and-error of op gradiëntgebaseerde trucjes gebruikt deze methode direct de nulruimte van de eerste gewichtsmatrix. Beginnend bij een willekeurige afbeelding berekenen de auteurs een vector die de eerste laag negeert en voegen vervolgens een geschaalde versie van deze vector aan de afbeelding toe. Omdat die richting onzichtbaar is voor de laag, blijven de interne features van het netwerk — en de uiteindelijke voorspelling — precies hetzelfde, zelfs als de afbeelding voor een menselijke waarnemer sterk gedesfigureerd aandoet. Hetzelfde idee is uit te breiden naar convolutionele lagen en in principe ook naar latere lagen. De auteurs onderzoeken veel standaardmodellen en vinden dat de meeste voldoende van zulke genegeerde richtingen hebben, wat betekent dat talloze botsende beelden op deze manier kunnen worden gegenereerd voor een breed scala aan taken.
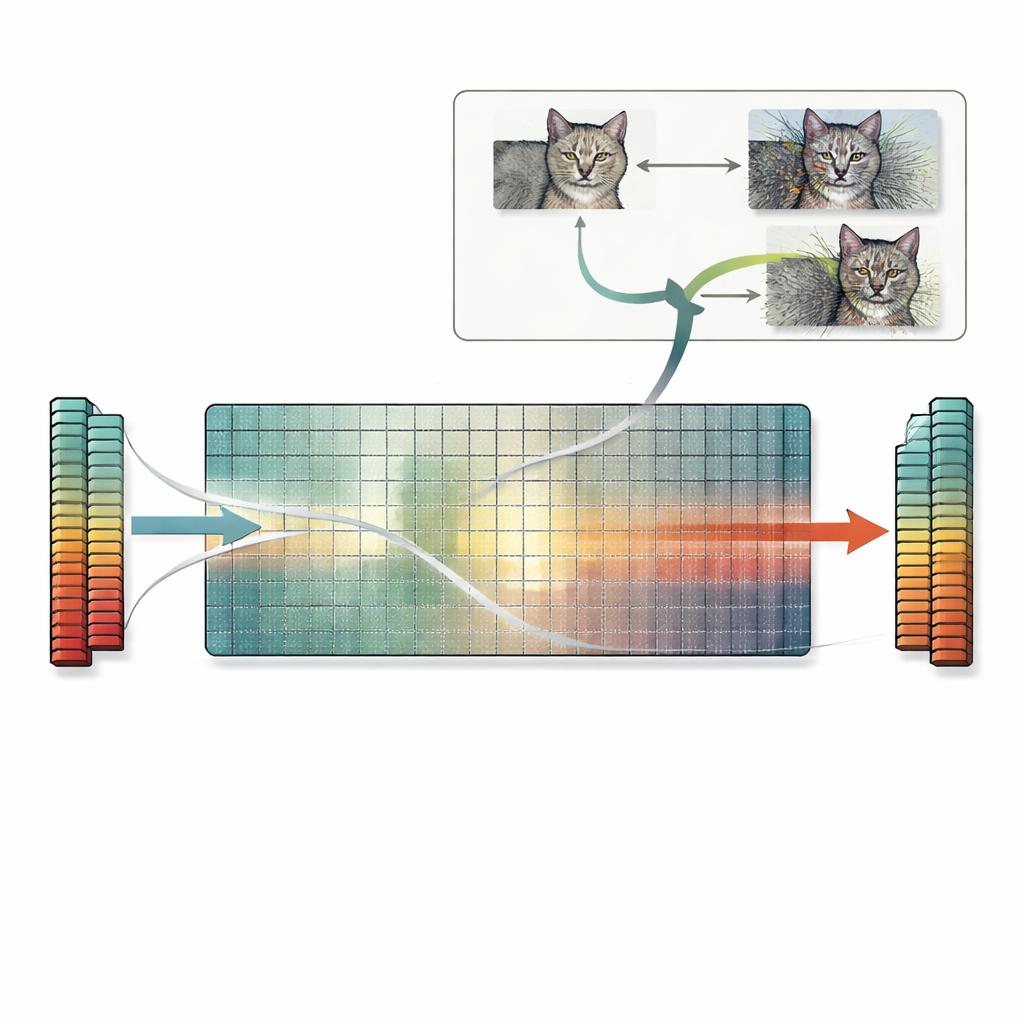
Verborgen risico's voor gelijkenis, verklaringen en beveiliging
Deze exacte featurebotsingen hebben verstrekkende gevolgen. Twee beelden met botsende features zullen niet alleen dezelfde voorspelling delen, ze zullen vaak ook dezelfde verklaringskaarten (explanation maps) tonen die populaire interpretatie-instrumenten produceren. Dat kan ertoe leiden dat een onherkenbaar, sterk verstoord beeld even goed onderbouwd lijkt als een schoon beeld, wat het vertrouwen in verklaringsmethoden ondermijnt. Het probleem treft ook op features gebaseerde gelijkenismaten die neurale netwerken gebruiken: zulke metriek kunnen een zwaar gecorrumpeerd beeld als "identiek" aan het origineel beoordelen omdat de features exact overeenkomen, ook al geven eenvoudige pixelgebaseerde scores terecht grote verschillen aan. Ten slotte kan de nul-ruimtezoektocht worden gecombineerd met standaard adversariale aanvallen, waardoor vele verschillende adversariale beelden ontstaan die allemaal dezelfde foute voorspelling opleveren en binnen gangbare verstoringsgrenzen blijven, wat de bestaande beveiligingszorgen verdiept.
Wat dit betekent voor het bouwen van veiligere AI
In eenvoudige termen toont dit werk dat hedendaagse neurale netwerken vaak informatie op voorspelbare manieren wegwerpen, waardoor hele richtingen in de inputruimte ontstaan die hun beslissingen helemaal niet beïnvloeden. Aanvallers kunnen deze blinde vlekken uitbuiten om bizar of adversarieel beeldmateriaal te creëren dat een netwerk als identiek aan normale beelden behandelt. De auteurs suggereren het tellen van deze genegeerde richtingen als een eenvoudige maat om te bepalen hoe kwetsbaar een model kan zijn, en bepleiten dat slankere, beter-gedereguleerde netwerken met kleinere nulruimtes robuuster zouden kunnen zijn. Hoewel er in de praktijk nog veel getest moet worden, is de kernboodschap duidelijk: als we betrouwbare AI willen, moeten we niet alleen letten op waar netwerken op reageren, maar ook op wat ze negeren.
Bronvermelding: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Trefwoorden: neurale netwerken, adversariale voorbeelden, featurebotsingen, modelrobuustheid, nul-ruimtes zoeken