Clear Sky Science · nl
CMT-Unet: gebruikmaken van een stapsgewijze hybride raamwerk voor verbeterde nauwkeurigheid en efficiëntie bij medische beeldsegmentatie
Scherpere blik in het lichaam
Moderne geneeskunde is sterk afhankelijk van scans zoals CT en MRI om in het lichaam te kijken, maar het omzetten van deze vage grijstinten naar heldere contouren van organen en weefsels blijft een uitdaging. Artsen hebben precieze grenzen nodig om operaties te plannen, hartfunctie te volgen of te meten hoe een tumor op behandeling reageert. Dit artikel introduceert een nieuwe computervisie-aanpak, CMT-Unet genoemd, ontworpen om die grenzen nauwkeuriger en efficiënter te tekenen en zo geautomatiseerde beeldanalyse een stap dichter bij dagelijks klinisch gebruik te brengen.
Waarom beeldcontouren ertoe doen
Voor een operatie of een complexe behandeling hebben clinici vaak een pixel-nauwkeurige kaart van organen of structuren in een scan nodig — een proces dat segmentatie wordt genoemd. Traditioneel tekenden experts deze regio’s met de hand af, een tijdrovende en vermoeiende taak die gevoelig is voor variatie tussen waarnemers. In het afgelopen decennium hebben deep learning-methoden veel van dit werk overgenomen, vooral modellen gebaseerd op convolutionele neurale netwerken en Transformer-achtige aandachtmechanismen. Convolutionele modellen blinken uit in het oppikken van fijne lokale details zoals randen, terwijl Transformers bijzonder goed zijn in het vastleggen van bredere context over het hele beeld. Elk heeft echter zijn nadelen: convoluties kunnen langafstandsrelaties missen, terwijl Transformers vaak veel rekenkracht en geheugen vereisen.
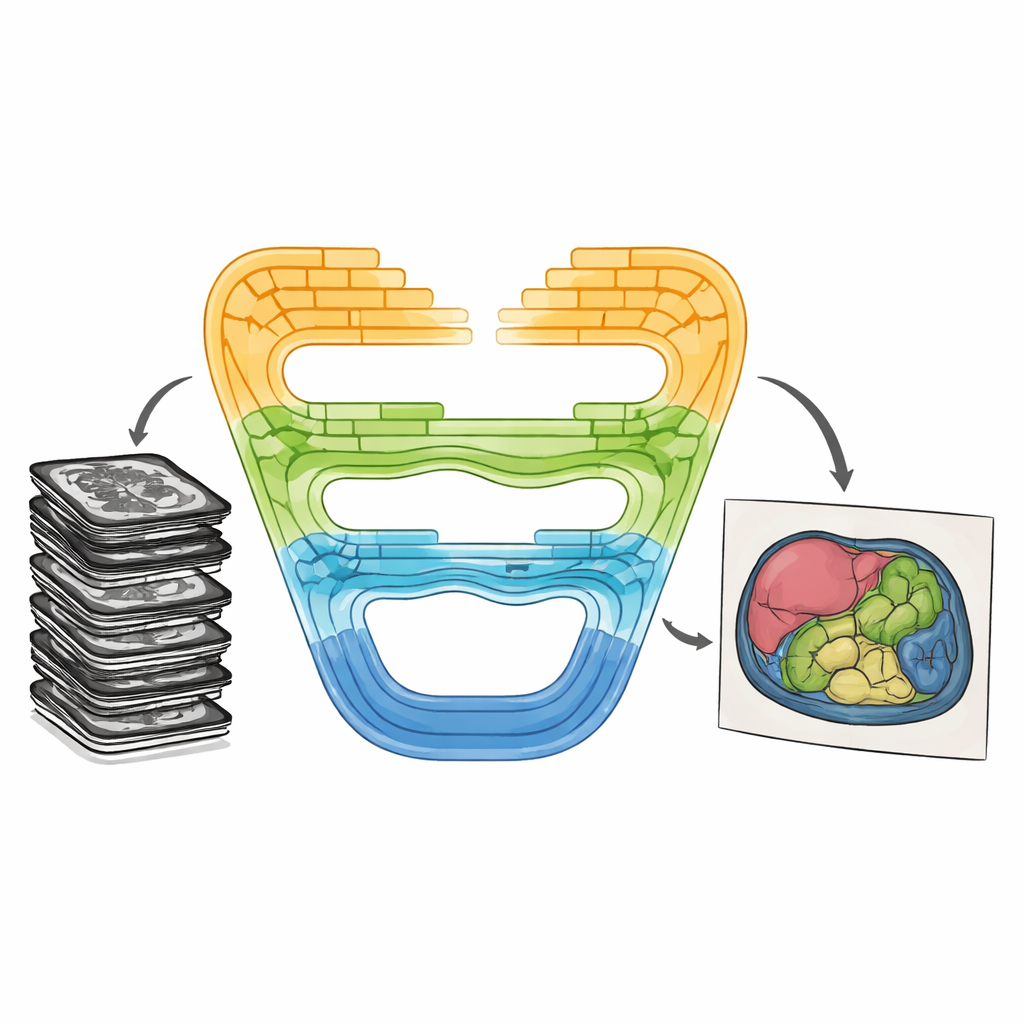
Samenbrengen van sterke kanten op een nieuwe manier
CMT-Unet pakt deze afwegingen aan door drie soorten bouwstenen stapsgewijs met elkaar te verweven, in plaats van op één type te vertrouwen door het hele netwerk. Aan de voorkant leert een inverted residual convolutionele eenheid snel lokale patronen — scherpe randen en texturen die helpen aangrenzende weefsels te onderscheiden. In de middenlagen draagt een module gebaseerd op zogenaamde state space-modellen, aangepast van een recente architectuur genaamd Mamba, informatie voort langs reeksen afbeeldingskenmerken op een manier die zowel contextbewust als computationeel zuinig is. Dieper in het netwerk nemen Transformer-blokken, verrijkt met HiLo-aandacht, de informatie in hoge- en lagefrequentiecomponenten op, waardoor het model zowel fijne details als brede orgaanvormen kan vastleggen voordat het ze weer samenvoegt. Dit gelaagde ontwerp weerspiegelt de natuurlijke voortgang van ruwe pixels naar abstracte betekenis tijdens beeldverwerking.
Hoe het nieuwe model onder de motorkap werkt
In de praktijk volgt CMT-Unet de bekende U-vormige opzet die populair is in medische beeldvorming: een encoder die informatie comprimeert naar rijkere kenmerken, een decoder die een voorspelling op volledige grootte herbouwt, en skip-connections die ruimtelijke details doorgeven. Het belangrijkste verschil zit in welke modules op elke diepte worden gebruikt. De vroege convolutionele eenheid behandelt de fijnkorrelige structuur die de Mamba- en Transformer-componenten anders zouden vervagen. Het aangepaste MambaVision-blok verbetert vervolgens de middellange-context door ruimtelijke informatie te mengen met speciaal ontworpen tweedimensionale operaties, waarmee de zware kosten van volledige aandacht worden vermeden terwijl toch verder dan lokale patches wordt gekeken. HiLo-aandacht in de Transformer-fase scheidt expliciet scherpe randen van vloeiende achtergrondpatronen en combineert ze op een manier die grenzen behoudt. Ten slotte helpt een dubbel upsampling-module in de decoder bij het reconstrueren van schone, continue contouren en vermindert het veelvoorkomende artefacten zoals ruitpatronen.
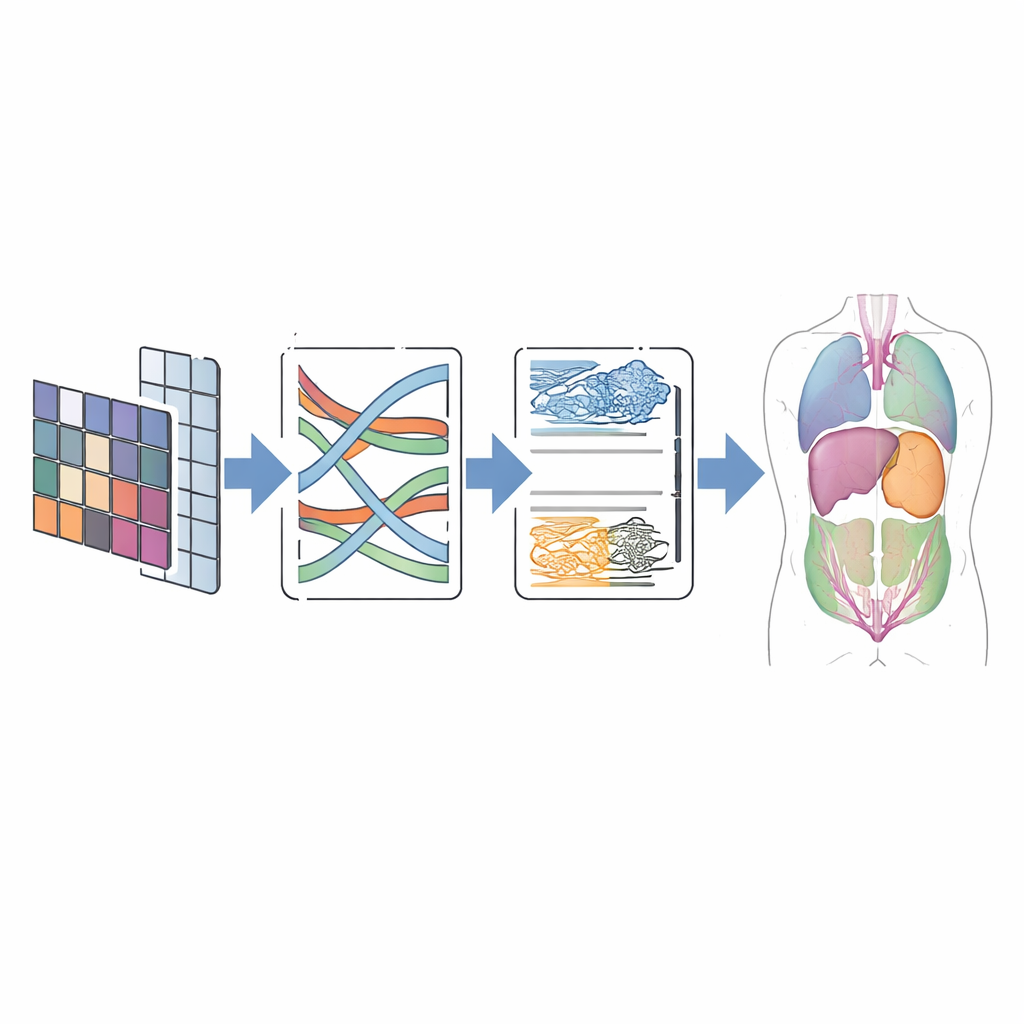
Testen op scangegevens uit de praktijk
Om te beoordelen of dit ontwerp resultaat oplevert, testten de auteurs CMT-Unet op twee veelgebruikte openbare datasets. De eerste, Synapse genoemd, bevat abdominale CT-scans met acht gelabelde organen, waaronder de lever, nieren en maag. De tweede, ACDC, bevat cardiale MRI-beelden met labels voor de hartkamers en de hartspierwand. Over deze benchmarks behaalde CMT-Unet segmentatiescores die gelijk waren aan of beter dan toonaangevende convolutionele, Transformer- en hybride modellen, terwijl het een matig aantal parameters en een beheersbare hoeveelheid rekenwerk gebruikte. Visuele vergelijkingen toonden gladdere en anatomisch consistentere grenzen, vooral rond uitdagende gebieden zoals de hartkamers, cruciaal voor het meten van functie en het plannen van ingrepen.
Wat dit betekent voor patiënten en klinieken
Voor niet-specialisten is de belangrijkste conclusie dat CMT-Unet een slimmere manier biedt om structuren in medische beelden te traceren door zorgvuldig het juiste gereedschap aan het juiste verwerkingsstadium toe te wijzen. Door lokaal detail en globale context in balans te brengen, kan het model nauwkeurige, nette orgaancontouren produceren zonder supercomputer-niveaus van rekenkracht te vereisen. Hoewel het huidige werk zich richt op tweedimensionale scans en een beperkte set openbare datasets, is de aanpak veelbelovend voor toekomstige uitbreidingen naar driedimensionale beeldvorming en bredere klinische toepassingen. Indien verder gevalideerd, zou dit soort lichtgewicht maar precieze segmentatie snellere diagnoses, betrouwbaardere behandelplanning en real-time begeleiding in drukke ziekenhuisomgevingen kunnen ondersteunen.
Bronvermelding: Wang, R., Liu, H. & Wang, G. CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation. Sci Rep 16, 10079 (2026). https://doi.org/10.1038/s41598-026-40572-w
Trefwoorden: medische beeldsegmentatie, deep learning, hybride neurale netwerken, state space-modellen, medische beeldvorming