Clear Sky Science · nl
Het zoeken naar een balans tussen eerlijkheid en prestatie bij glioomgraadsvoorspelling met biasmitigatietechnieken
Waarom eerlijke behandeling van tumoren ertoe doet
Wanneer artsen kunstmatige intelligentie gebruiken om te helpen bij de diagnose van hersentumoren, nemen we vaak aan dat de computer neutraal is. Maar als de gegevens die voor het trainen van deze hulpmiddelen worden gebruikt bestaande gezondheidsongelijkheden weerspiegelen, kan de software sommige patiënten stilletjes minder eerlijk behandelen dan anderen. Deze studie onderzoekt hoe machine-learningsystemen die de ernst van gliomen voorspellen — een veelvoorkomend type hersentumor bij volwassenen — onbedoeld bepaalde ras- of geslachtsgroepen kunnen bevoordelen, en test praktische manieren om die voorspellingen eerlijker te maken zonder te veel nauwkeurigheid op te geven. 
Hersentumoren en computerhulp
Gliomen zijn hersentumoren die variëren van langzaam groeiende, beter behandelbare vormen tot zeer agressieve kankers met slechte overleving. Het correct gradere van deze tumoren is essentieel, omdat het de richting van chirurgie, bestraling en medicamenteuze behandeling bepaalt. De onderzoekers werkten met een openbare dataset van 839 volwassenen met ofwel laaggradige gliomen of agressieve glioblastomen. Van elke patiënt hadden ze leeftijd, geslacht, ras en 20 veelvoorkomende genetische markers in de tumor. Ze trainden drie standaard voorspellingsmodellen — logistische regressie, random forests en gradient boosting — om de twee tumorgraadn van elkaar te onderscheiden met behulp van deze kenmerken, en controleerden vervolgens zowel hoe nauwkeurig de modellen in het algemeen waren als hoe goed ze verschillende patiëntengroepen behandelden.
Op zoek naar verborgen ongelijkheid
Om eerlijkheid te onderzoeken richtte het team zich op twee “beschermde” kenmerken: ras (wit versus niet-wit) en geslacht (man versus vrouw). De dataset zelf was scheef verdeeld — meer dan 90 procent van de patiënten was wit, en er waren merkbaar meer mannen dan vrouwen. De auteurs gebruikten groepsniveau-eerlijkheidsmaten die vergelijken hoe vaak verschillende groepen een correcte “hooggradige” voorspelling ontvangen en hoe vaak het model fouten maakt voor elke groep. Alle drie de modellen waren in het algemeen behoorlijk nauwkeurig, waarbij logistische regressie het best presteerde. Maar onder dat succes onthulden de eerlijkheidscontroles dat niet-witte patiënten over het algemeen slechter presteerden dan witte patiënten, vooral bij het correct identificeren van de minder agressieve tumoren. Ter vergelijking: de prestaties voor mannen en vrouwen waren veel evenwichtiger, met slechts kleine verschillen tussen de geslachten.
Pogingen om de bias te verhelpen
De onderzoekers vroegen zich vervolgens af of ze de eerlijkheid konden verbeteren zonder de medische bruikbaarheid van het model ernstig te verzwakken. Ze kozen logistische regressie als basismodel, omdat het zowel het meest nauwkeurig als het meest eerlijk van de drie was. Ze probeerden twee veelgebruikte debiasing-strategieën. Een “pre-processing” benadering genaamd reweighting gaf ondervertegenwoordigde patiënten extra gewicht tijdens het trainen, zodat het model er meer aandacht aan zou besteden. Een “post-processing” benadering genaamd equalized odds behield het getrainde model maar paste de uitkomsten aan zodat foutpercentages meer vergelijkbaar werden tussen groepen. 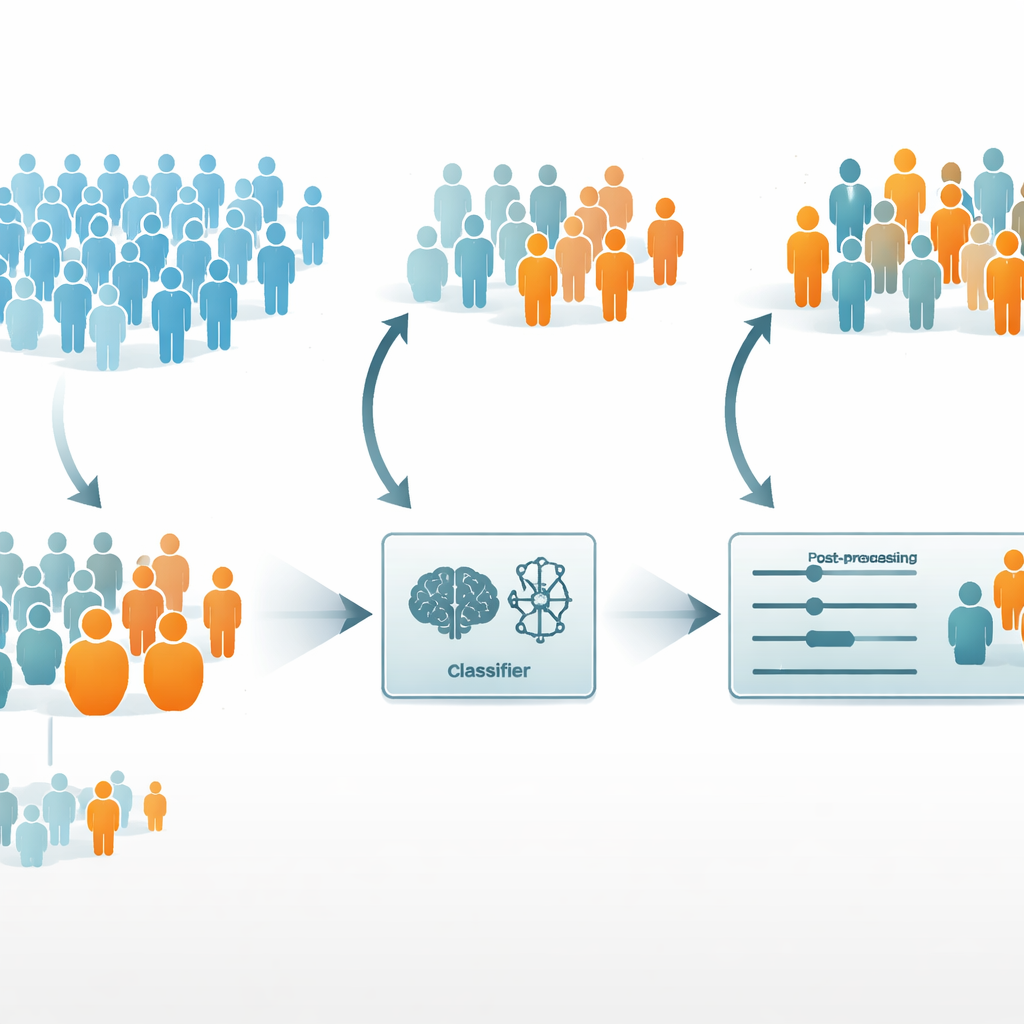
Wat veranderde toen het model werd aangepast
Voor geslacht hielpen beide strategieën over het algemeen: de voorspellingen voor vrouwen verbeterden en de verschillen tussen mannen en vrouwen krompen grotendeels in. Voor ras, waar de scheefheid in de data veel sterker was, was het beeld complexer. Reweighting had soms een averechts effect en verslechterde lichtjes de prestaties voor niet-witte patiënten en vergrootte volgens sommige maten zelfs de oneerlijkheid. Daarentegen verminderde de post-processing-methode de raciale verschillen in foutpercentages aanzienlijk terwijl de algehele nauwkeurigheid van het model hoog bleef, hoewel die methode de prestaties voor de meerderheidsgroep iets verlaagde. De auteurs toonden ook aan dat eerlijkheidsscores voor de veel kleinere groep niet-witte patiënten statistisch onstabiel zijn — het veranderen van maar één voorspelling kan de eerlijkheidsscores merkbaar verschuiven — dus die resultaten moeten voorzichtig worden geïnterpreteerd.
Wat dit betekent voor patiënten en artsen
De studie concludeert dat er geen gratis lunch bestaat: het verbeteren van eerlijkheid in medische AI gaat vaak gepaard met afwegingen in prestatie, en de beste oplossing hangt af van hoe scheef de data zijn en welk eerlijkheidsdoel wordt vooropgesteld. In dit voorbeeld van hersentumoren bleek het achteraf aanpassen van modeluitkomsten de meest praktische manier om behandelaanbevelingen eerlijker te maken over ras en geslacht, terwijl de voorspellende kracht grotendeels behouden bleef. Het werk benadrukt dat eerlijkheidstests routine moeten worden bij het inzetten van AI in de gezondheidszorg, vooral bij ernstige aandoeningen zoals glioom, en dat er methoden bestaan om deze hulpmiddelen eerlijker te maken — maar dat ze zorgvuldig gekozen en geïnterpreteerd moeten worden.
Bronvermelding: Sánchez-Marqués, R., García, V. & Sánchez, J.S. Addressing the balance between fairness and performance in glioma grade prediction using bias mitigation techniques. Sci Rep 16, 9785 (2026). https://doi.org/10.1038/s41598-026-40555-x
Trefwoorden: glioomgradatie, eerlijke medische AI, algoritmische vooringenomenheid, hersen tumoren, biasmitigatie