Clear Sky Science · nl
Een kNN-gebaseerde machine learning-aanpak voor het automatiseren van causaliteitsbeoordeling van bijwerkingen
Waarom dit belangrijk is voor mensen die medicijnen gebruiken
Wanneer een nieuw medicijn op de markt komt, begint het verhaal pas. Miljoenen mensen zullen het in de praktijk gebruiken en sommigen krijgen gezondheidsproblemen die mogelijk door het middel worden veroorzaakt — of misschien niet. Uitzoeken welke reacties daadwerkelijk aan het geneesmiddel te wijten zijn, is essentieel voor patiëntveiligheid, maar dat werk is momenteel traag, complex en grotendeels handmatig. Deze studie onderzoekt hoe een eenvoudige maar krachtige vorm van kunstmatige intelligentie experts kan helpen deze veiligheidsrapporten sneller en consistenter te beoordelen, zonder het menselijke oordeel te vervangen dat uiteindelijk patiënten beschermt.
Hoe veiligheidsverhalen data worden
Farmaceutische bedrijven en toezichthouders vertrouwen op individuele gevalssafetyrapporten, gestructureerde samenvattingen van ervaringen van echte mensen met geneesmiddelen. Elk rapport kan bevatten wat er misging (bijvoorbeeld hoofdpijn of een leverprobleem), hoe ernstig het was, welke andere middelen en aandoeningen aanwezig waren en wat de oorspronkelijke beoordelaar dacht over de koppeling met het geneesmiddel. Voor meer dan 800.000 zulke rapporten over zes toegelaten middelen hadden de medische beoordelaars van het bedrijf al vastgesteld of elk bijwerkingen gerelateerd waren aan het geneesmiddel, niet gerelateerd waren, of niet beoordeelbaar waren vanwege ontbrekende of tegenstrijdige informatie. De onderzoekers gebruikten dit rijke historische materiaal als trainingsdata voor een computermodel dat die menselijke beslissingen op nieuwe gevallen zou leren nabootsen.

Een computer leren vergelijkbare gevallen te herkennen
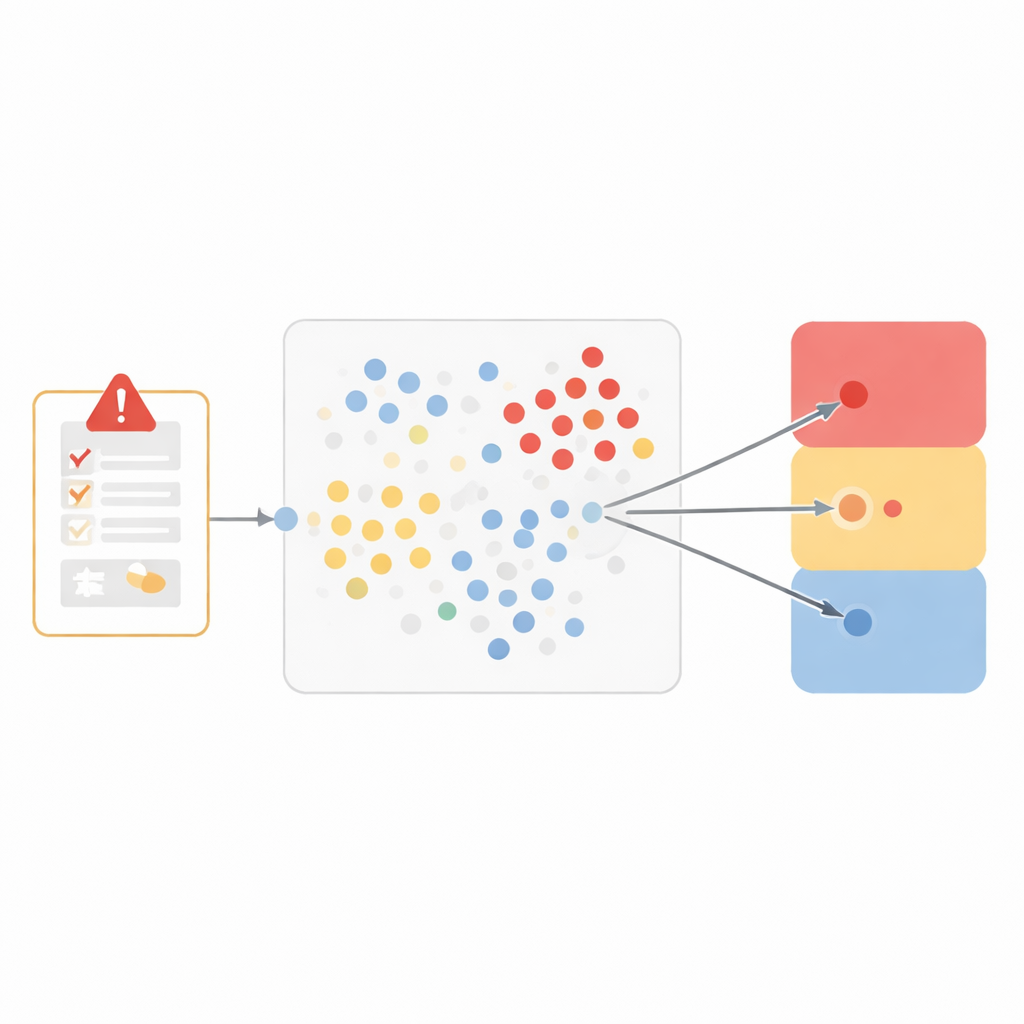
In plaats van een black-boxsysteem te bouwen, koos het team voor een bijzonder transparante methode genaamd "dichtstbijzijnde buren". Het idee is intuïtief: als twee gevallen erg op elkaar lijken, hebben ze waarschijnlijk dezelfde conclusie over de vraag of het geneesmiddel de oorzaak was. Om gelijkenis vast te leggen, representeerden de onderzoekers elke bijwerking als een profiel van zeven onderdelen, inclusief de medische term voor de gebeurtenis, wat er gebeurde toen het middel werd gestopt en opnieuw gestart, of het probleem te verwachten was voor dat middel, de mening van de melder, andere ingenomen medicijnen, medische voorgeschiedenis en hoe ernstig de gebeurtenis was. Vervolgens maten ze hoe dicht twee gevallen bij elkaar lagen in deze zeven-dimensionale ruimte, waarbij ze meer gewicht gaven aan kenmerken die het meest van belang zijn voor causaliteit, zoals de exacte gebeurtenis en wat er gebeurde bij wijziging van de behandeling.
Van nabijheid naar een driedelige beslissing
Wanneer een nieuw rapport binnenkomt, doorzoekt het model de historische data om de tien meest vergelijkbare gevallen te vinden. Het controleert vervolgens hoe die buren waren geclassificeerd en laat ze "stemmen" over drie brede uitkomsten: waarschijnlijk gerelateerd aan het geneesmiddel, niet gerelateerd of onwaarschijnlijk, en niet beoordeelbaar. Deze driedelige indeling vormt een evenwicht tussen klinische nuance en betrouwbare prestaties. Getest op meer dan 250.000 eerder niet-gebruikte gebeurtenissen, kwam het model sterk overeen met menselijke beoordelaars voor gebeurtenissen die als gerelateerd werden beschouwd en voor die als niet beoordeelbaar werden aangemerkt, met lage foutpercentages en sterke scores die nauwkeurigheid en volledigheid combineren. Het had meer moeite met de kleinere groep duidelijk niet-gerelateerde gevallen, wat de uitdaging weerspiegelt die machine-learning-systemen ondervinden wanneer een type voorbeeld relatief schaars is.
De mist van "niet te zeggen" verminderen
Een praktisch probleem in de dagelijkse veiligheidspraktijk is dat het label "niet beoordeelbaar" een vangnet kan worden wanneer informatie schaars of dubbelzinnig is, wat het moeilijker maakt echte veiligheids patronen te zien. De onderzoekers voegden een afstemmingsinstrument toe dat het model voorzichtiger maakt bij het toekennen van dit label. In plaats van "niet beoordeelbaar" te kiezen wanneer het simpelweg een meerderheid wint onder vergelijkbare gevallen, vereist het model nu een hoger percentage buren dat die keuze ondersteunt. Door deze drempel te verhogen kon het team scherp verminderen hoe vaak het model een geval als niet beoordeelbaar aanmerkte en de prestaties voor de andere twee categorieën verbeteren, ten koste van enige toegenomen onenigheid voor de moeilijkst te beoordelen gevallen. Een webgebaseerd dashboard stelt medische beoordelaars in staat deze drempel per product aan te passen, meteen te zien hoe de balans van uitkomsten verschuift en hun aandacht te richten op gevallen waar model en mens het oneens zijn.
Wat dit betekent voor toekomstige geneesmiddelveiligheid
Voor een steekproef van recente gevallen die menselijke beoordelaars als niet beoordeelbaar hadden gemarkeerd, wees het systeem honderden gevallen aan waar de conclusie verschilde. Toen senior beoordelaars deze herbeoordeelden, waren ze meer dan tweederde van de tijd het eens met het model, wat aantoont dat dergelijke hulpmiddelen over het hoofd geziene patronen kunnen signaleren en kwaliteitscontrole ondersteunen in plaats van experts te vervangen. Het werk toont aan dat een duidelijke, op gelijkenis gebaseerde aanpak kunstmatige intelligentie op een uitlegbare, afstembare en medisch verantwoorde manier in geneesmiddelveiligheid kan brengen. Naarmate meer data zich opstapelen en tekstnarratieven worden toegevoegd met moderne taaltechnologieën, zouden systemen als dit kunnen helpen opkomende risico's eerder te signaleren, terwijl clinici stevig verantwoordelijk blijven voor de eindbeslissingen.
Bronvermelding: Ren, J., Carroll, H., McCarthy, K. et al. A kNN based machine learning approach to automating causality assessment of adverse events. Sci Rep 16, 9140 (2026). https://doi.org/10.1038/s41598-026-40267-2
Trefwoorden: farmacovigilantie, ongewenste geneesmiddelgebeurtenissen, causaliteitsbeoordeling, machine learning, k dichtstbijzijnde buren