Clear Sky Science · nl
Ensemble machine learning-strategieën voor mineral prospectivity mapping bij schaarse gegevens
Goudaders vinden met minder aanwijzingen
De moderne samenleving is afhankelijk van metalen zoals lood en zink voor batterijen, electronica en infrastructuur, maar de gemakkelijkst toegankelijke afzettingen zijn al ontdekt. In nieuwe gebieden hebben geologen vaak slechts een handvol bevestigde vondsten, verspreide chemische monsters en onvolledige kaarten om zich op te baseren. Deze studie laat zien hoe machine learning niet moet worden ingezet om de hoogst mogelijke score op historische data na te jagen, maar om voorspellingen te leveren waarop besluitvormers daadwerkelijk kunnen vertrouwen wanneer informatie schaars is.
Waarom gegevens in de praktijk schaars zijn
Mineral prospectivity mapping heeft tot doel delen van het landschap te markeren die waarschijnlijker ertsen bevatten. Het combineert informatielagen zoals gesteentetypen, breuken, satellietbeelden en chemie van stroomsedimenten tot een waarschijnlijkheidskaart die veldwerk en boren stuurt. In vroege projectfasen zijn er echter vaak maar weinig bekende afzettingen en vele delen van de kaart zijn nooit bemonsterd. Standaard machine learning-instrumenten floreren bij grote, goed gelabelde datasets; wanneer ze slechts enkele tientallen positieve voorbeelden hebben, kunnen ze instabiel en overgeconfiant worden, waardoor ze precieus ogende cijfers afgeven die slecht met de werkelijkheid overeenkomen.
Van spaarzame aanwijzingen naar bruikbare signalen
De auteurs werkten in het Dehaq lood‑zinkdistrict in centraal Iran, een regio waar mineralisatie verbonden is met specifieke kalksteenlagen, breuken en zones van chemische alteratie. Ze bouwden digitale kaarten van gastgesteenten, breukdichtheid en alteratie op basis van geologische onderzoeken en satellietbeelden, en haalden geochemische anomalieën uit 624 sedimentmonsters. Uit dit rijke maar ongelijkmatige bewijsmateriaal distilleerden ze slechts 108 gelabelde locaties: 27 met bekende afzettingen en 81 zonder. Om te voorkomen dat de overwegende meerderheid van de negatieve gevallen de weinige ertsvoorbeelden overschaduwt, gebruikten ze een techniek die realistische synthetische depositopunten creëert door te interpoleren tussen bestaande punten, waardoor de klassen binnen alleen de trainingsdata meer in balans werden gebracht. Dit leverde een evenwichtiger set voorbeelden op, terwijl aparte validatie- en testsets behouden bleven die de zeldzaamheid in de echte wereld weerspiegelen. 
Teams van modellen bouwen in plaats van één held
In plaats van te vertrouwen op één algoritme koppelde de studie methoden met verschillende sterktes. Eén ensemble combineerde een support vector machine, die de scherpst mogelijke scheidslijn tussen klassen trekt, met een eenvoudig probabilistisch model genaamd Gaussian Naive Bayes. De andere mengde twee boomgebaseerde methoden, LightGBM en AdaBoost, die uitblinken in het vastleggen van complexe patronen over veel variabelen. In beide gevallen was de eindvoorspelling het gemiddelde van de waarschijnlijkheidsschattingen van de componentmodellen, een strategie die vaak sterke schommelingen in prestaties vermindert. Cruciaal was dat de auteurs niet alleen vergeleken hoe vaak deze modellen het bij het juiste eind hadden, maar ook hoe goed hun voorspelde waarschijnlijkheden overeenkwamen met de werkelijkheid — een eigenschap die bekendstaat als kalibratie.
Afstellen voor vertrouwen, niet alleen voor score
Het kiezen van de instellingen van een model — hoe sterk het fouten bestraft, hoeveel bomen het opbouwt, enzovoort — kan het gedrag sterk veranderen. Het team testte drie veelgebruikte afstemmingsstrategieën: Grid Search, die systematisch een vaste lijst met opties doorzoekt; Random Search, die combinaties willekeurig bemonstert; en Bayesian Optimization, die voorgaande proeven gebruikt om veelbelovende nieuwe opties te raden. Op papier leverde Bayesian Optimization de hoogste discriminatiescore (een ROC–AUC van 0,95) voor het support‑vector‑gebaseerde ensemble. Toch, wanneer de auteurs naar kalibratiecurves keken, die voorspelde waarschijnlijkheden vergelijken met werkelijke uitkomsten, leverden de Grid Search-versies van beide ensembles vloeiendere, stabielere resultaten op, vooral in het middenbereik van waarschijnlijkheden waar doorgaans drempels voor exploratie worden gelegd. 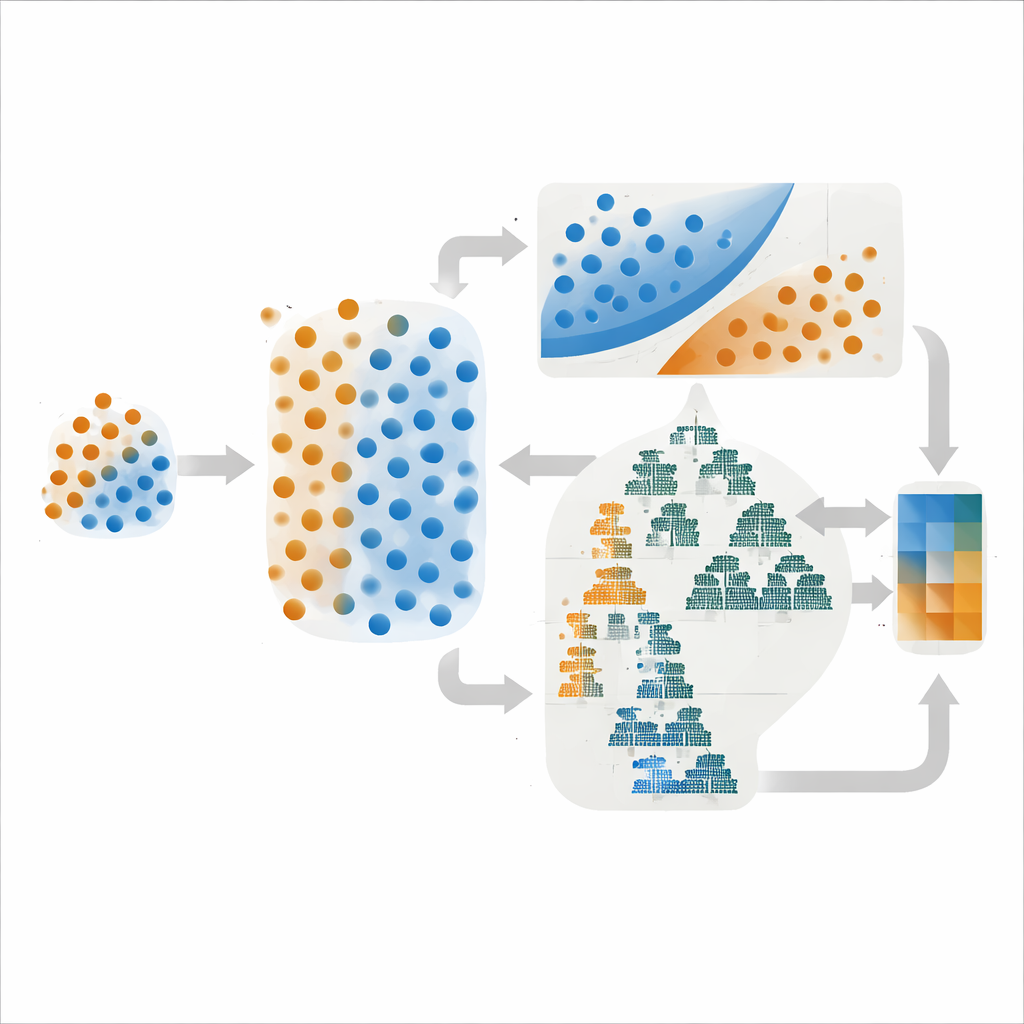
Van cijfers naar beslissingen in het veld
Voor vroege exploratie, waar elk boorgat duur is, bepleiten de auteurs dat goed-gedoseerde waarschijnlijkheden belangrijker zijn dan het winnen van een klein accuraatvoordeel. Hun meest praktische aanbeveling is het eenvoudigere support‑vector‑plus‑Bayes-ensemble, afgestemd met Grid Search. Het bereikt sterke discriminatie en biedt tegelijk de meest betrouwbare koppeling tussen waarschijnlijkheidswaarden en werkelijke ontdekkingskansen, waardoor geologen drempels kunnen instellen die bij hun risicotolerantie passen. Naarmate projecten volwassen worden en er meer data beschikbaar komen, kunnen complexere boomgebaseerde modellen zoals het LightGBM-ensemble worden geïntroduceerd om voorspellingen te verfijnen, maar altijd met oog voor kalibratie. Op deze manier wordt machine learning geen black‑box scoregenerator maar een transparante partner bij het nemen van risicobewuste beslissingen over waar naar de volgende generatie mineralen moet worden gezocht.
Bronvermelding: Amirajlo, P., Hassani, H., Pour, A.B. et al. Ensemble machine learning strategies for mineral prospectivity mapping under data scarcity. Sci Rep 16, 9171 (2026). https://doi.org/10.1038/s41598-026-40125-1
Trefwoorden: mineral prospectivity mapping, ensemble machine learning, gegevensschaarste, modelkalibratie, minerale exploratie