Clear Sky Science · nl
KM-DBSCAN: een verbeterd kader voor grensdetectie op basis van dichtheid en centroiden voor gegevensreductie richting green AI
Waarom kleinere AI vaak groener kan zijn
Kunstmatige intelligentie heeft een verborgen kost: elektriciteit. Het trainen van moderne machine‑learningmodellen betekent vaak het verwerken van miljoenen datapunten op energieverslindende hardware, wat op zijn beurt CO2‑uitstoot veroorzaakt. Dit artikel introduceert KM‑DBSCAN, een nieuwe manier om datasets te verkleinen vóór training zonder de informatie weg te gooien die modellen daadwerkelijk nodig hebben. Door alleen de meest informatieve data te behouden, versnelt de methode het leerproces, verlaagt het energieverbruik en levert het nog steeds nauwkeurige voorspellingen voor taken variërend van handgeschreven cijferherkenning tot vroege detectie van huidkanker.
Te veel data, te veel energie
Jarenlang was de heersende opvatting in AI dat meer data bijna altijd leidt tot betere modellen. Hoewel dat de nauwkeurigheid kan verbeteren, betekent het ook langere trainingstijden, grotere computers en hogere energierekeningen. Onderzoekers onderscheiden nu vaker "Red AI", die nauwkeurigheid nastreeft tegen elke prijs, en "Green AI", die probeert prestaties te balanceren met milieueffecten. Een veelbelovende route naar groenere AI is gegevensreductie: in plaats van een model elk beschikbaar voorbeeld te geven, identificeer je een veel kleinere set gevallen die het probleem nog steeds goed definiëren, met name de lastige grensgevallen die de beslissingen van een classifier bepalen.
Twee eenvoudige ideeën gecombineerd tot één slimme filter
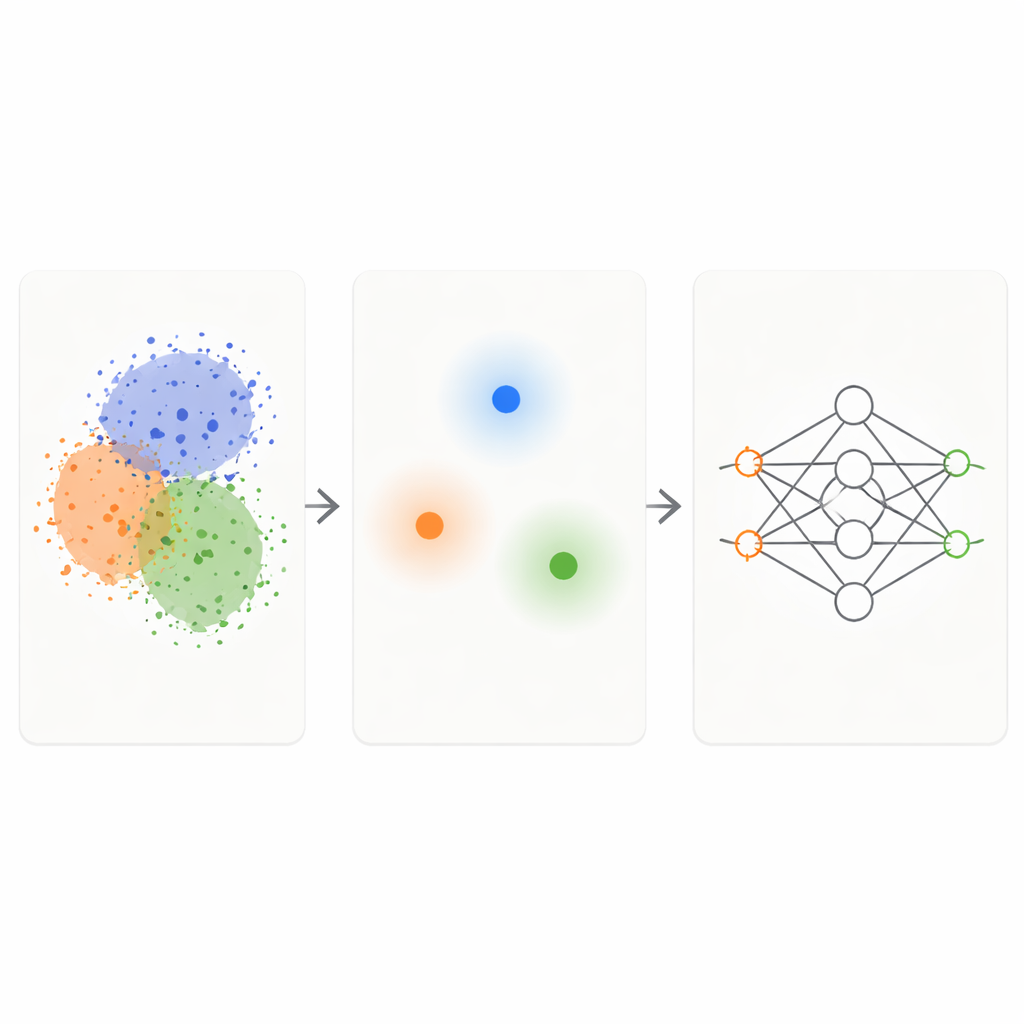
Het KM‑DBSCAN‑kader combineert twee bekende clusteringtechnieken tot een intelligent filter voor ruwe data. Eerst groepeert een snelle methode genaamd K‑Means punten in compacte clusters en vervangt elke groep door een representatief centrum, of centroid. Dit reduceert het probleem van duizenden of miljoenen punten tot enkele honderden representatieve punten. Vervolgens wordt een dichtheidsgebaseerde methode (DBSCAN) toegepast op die centroiden om te bepalen welke gebieden aan de randen tussen clusters liggen en welke dichte, homogene binnengebieden of geïsoleerde ruis zijn. Door op het niveau van centroiden te werken, wordt DBSCAN veel sneller en minder gevoelig voor lastige parameterkeuzes dan wanneer het direct op alle datapunten wordt toegepast.

Alleen de moeilijke, informatieve gevallen bewaren
Zodra KM‑DBSCAN heeft vastgesteld waar verschillende groepen elkaar raken of overlappen, behoudt het alleen de datapunten die zich dicht bij deze grenzen bevinden en verwijdert zowel dieptepunten in het binnengebied als duidelijke uitbijters. Binnenpunten zijn grotendeels redundant: ze lijken allemaal op elkaar en geven het model dezelfde informatie over hun klasse. Grenspuntengeven daarentegen precies aan waar de ene klasse eindigt en de andere begint. Op synthetische toy‑datasets reproduceert deze strategie dezelfde beslissingsgrenzen die een classifier uit de volledige data leert, zelfs wanneer de meeste punten zijn verwijderd. Op real‑world datasets zoals Banana, USPS‑cijfers, de Adult‑inkomensdataset, voertuigbotsingsgegevens, droogboonvariëteiten en melanomahuidafbeeldingen behouden de gereduceerde sets de kernstructuur van het probleem terwijl ze een orde van grootte kleiner zijn.
Snelheid, CO2‑besparing en echte toepassingen
De auteurs testten KM‑DBSCAN als front‑end voor verschillende populaire modellen, waaronder support vector machines, multilayer perceptrons en convolutionele neurale netwerken. In veel gevallen was trainen op de gereduceerde data tientallen tot duizenden keren sneller, terwijl de nauwkeurigheid vrijwel behouden bleef — en soms zelfs licht verbeterde. Zo verkleinde de methode bij handgeschreven cijferherkenning de trainingsset tot slechts 1,4% van de oorspronkelijke omvang en verbeterde de nauwkeurigheid iets, terwijl de training 284 keer sneller werd. In een inkomensvoorspellingstaak met ongelijke klassen werd een speed‑up van 6907 keer bereikt met slechts ongeveer 3% van de data en minimale nauwkeurigheidsverliezen. In een melanomadetectie-experiment bereikte een diep neuraal netwerk meer dan 90% nauwkeurigheid terwijl het trainde op minder dan een derde van de oorspronkelijke huidbeelddataset, met een CO2‑reductie van meer dan 70%.
Wat dit betekent voor alledaagse AI
Voor niet‑specialisten is de kernboodschap dat slimme selectie het vaak kan winnen van louter volume. KM‑DBSCAN laat zien dat het zorgvuldig kiezen welke voorbeelden een model ziet — met focus op de meest informatieve grensgevallen — rekentijd en energieverbruik drastisch kan verminderen terwijl voorspellingen betrouwbaar blijven. Deze benadering sluit goed aan bij de bredere beweging naar Green AI, waarin de kwaliteit van data en doordacht ontwerp van trainingspipelines even belangrijk zijn als ruwe modelgrootte. Als dit breed wordt toegepast, kunnen dergelijke data‑bewuste filters alles van medische beeldanalyse tot verkeersveiligheid duurzamer maken en krachtige AI‑tools binnen bereik brengen van organisaties zonder enorme rekenmiddelen.
Bronvermelding: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Trefwoorden: green AI, gegevensreductie, clustering, efficiëntie van machine learning, melanoomdetectie