Clear Sky Science · nl
Verbetering van bronsignaal-sparsity op basis van lokaal-maximaal synchro-extractie-transformatie-algoritme voor gemengde matrixschatting in UBSS
Verborgen signalen ontwarren
Veel technologieën waarop we vertrouwen — draadloze netwerken, radar, medische scanners en zelfs slimme microfoons — moeten zwakke signalen onderscheiden die hopeloos door elkaar zitten. Stel je voor dat je in een druk café meerdere gesprekken tegelijk probeert te volgen met slechts twee oren. Dit artikel presenteert een nieuwe manier om zulke overlappende signalen te "ontwarren" wanneer er minder sensoren dan bronnen zijn, een berucht lastige situatie. Door scherper te kijken naar signalen in tijd en frequentie, en door te verbeteren hoe computers gerelateerde gegevens groeperen, tonen de auteurs aan dat ze mengsels nauwkeuriger en betrouwbaarder kunnen scheiden, zelfs onder rumoerige, realistische omstandigheden. 
Waarom gemengde signalen zo moeilijk te scheiden zijn
In veel systemen lopen meerdere onafhankelijke signalen door hetzelfde kanaal en worden ze opgevangen door een klein aantal ontvangers. Deze situatie, onderbepaalde blind source separation genoemd, betekent dat er meer onbekende signalen zijn dan metingen. Klassieke methoden voor signaalscheiding veronderstellen doorgaans het omgekeerde, en falen daarom hier. Een belangrijk modern trucje is het benutten van sparsity: in een geschikte representatie is elke bron slechts op enkele momenten of frequenties actief. Als op de meeste tijdstippen slechts één bron domineert, vormt de wolk van waargenomen data vanzelf clusters waarvan de richtingen coderen hoe elke bron zich mengde in de ontvangers. Het nauwkeurig vinden van deze clusters hangt echter af van het hebben van een representatie waarin de energie van elke bron scherp geconcentreerd is in plaats van uitgesmeerd.
Het beeld van een signaal verscherpen
Om sparsity te onthullen zetten ingenieurs signalen vaak om in een tijd–frequentieplaatje dat toont welke tonen op welke momenten aanwezig zijn. De eenvoudige korttijd-Fouriertransformatie doet dit door een venster langs de tijd te schuiven en vele kleine spectra te nemen, maar hij vervaagt energie en kan niet tegelijkertijd scherpe timing en precieze toonhoogte geven. Geavanceerdere varianten zoals synchrosqueezing en synchroextracting proberen verspreide energie naar de richel te trekken die de instantane frequentie van een signaal volgt. Deze methoden verbeteren de focus, maar blijven kwetsbaar voor ruis: wanneer toevallige stoorsignalen langs dezelfde richels worden samengeperst als het signaal, kan het resultaat een felle maar vage band zijn die fijne structuren verbergt.
Lokale pieken vinden om sparsity te versterken
Voortbouwend op deze ideeën introduceren de auteurs de Local Maximum Synchroextracting Transform, of LMSET. In plaats van alle nabijgelegen energie naar een frequentierichel te duwen, scant LMSET het tijd–frequentievlak en grijpt het op elk tijdstip lokale pieken langs de frequentieas. Alleen coëfficiënten rond deze lokale maxima worden behouden en herverdeeld, terwijl de rest wordt onderdrukt. Deze eenvoudige wijziging levert een representatie op waarin de energie van elk component-signaal geconcentreerd is in dunne, schone krommen met veel minder verspreide punten. Door simulaties met samengestelde testsignalen laat LMSET de laagste Rényi-entropie zien, een gangbare maat voor concentratie, en overtreft het de conventionele en state-of-the-art methoden over een breed scala aan ruisniveaus. Simpel gezegd produceert LMSET een helderder beeld van waar elk signaal in tijd en frequentie leeft.
Slimmer groeperen om de verborgen menging te leren
Een scherper beeld is slechts de helft van de strijd; de volgende stap is het clusteren van de resulterende punten om de onbekende mengmatrix te schatten die beschrijft hoe elke bron bijdraagt aan elke ontvanger. Veel benaderingen vertrouwen op fuzzy C-means, een populair clusteringalgoritme dat vaak vastloopt in slechte oplossingen omdat het zeer gevoelig is voor de initiële schatting en voor uitbijters. Om deze zwaktes te overwinnen koppelen de auteurs LMSET aan een nieuw, robuuster clusterschéma. Ze gebruiken eerst een PID-gebaseerd zoekalgoritme, geïnspireerd door de regeltechniek, om de volledige ruimte van mogelijke clustercentra te verkennen en slechte beginposities te vermijden. Vervolgens introduceren ze een Booleans gewichtsmechanisme om uitbijters te verzwakken en passen ze een informatie-entropie strategie toe die de gevoeligheid voor initiële condities vermindert. Samen stellen deze stappen de clustering in staat om consistenter de ware richtingen van de verborgen bronnen te vinden.
Wat de tests aantonen
De auteurs testen hun volledige pijplijn — LMSET plus de verbeterde clustering — op mengsels van digitaal gemoduleerde communicatiesignalen, waaronder QAM, QPSK en FSK, in zowel stille als rumoerige omgevingen. Ze vergelijken de geschatte mengmatrices met de werkelijke aan de hand van hoekfout en genormaliseerde gemiddelde kwadratische fout. Over de hele linie vermindert het gebruik van LMSET in plaats van een traditionele transformatie fouten, omdat de datapunten strakkere, meer onderscheidende clusters vormen. Onder de clusteringmethoden behaalt de voorgestelde PID-geoptimaliseerde robuuste fuzzy C-means de kleinste gemiddelde hoekafwijkingen en de beste fouten-scores. In het algemeen verbetert de gecombineerde methode de nauwkeurigheid van de schatting van de mengmatrix met bijna 20 procent ten opzichte van conventionele benaderingen, terwijl de sterke prestaties behouden blijven zelfs bij hoge ruisniveaus. 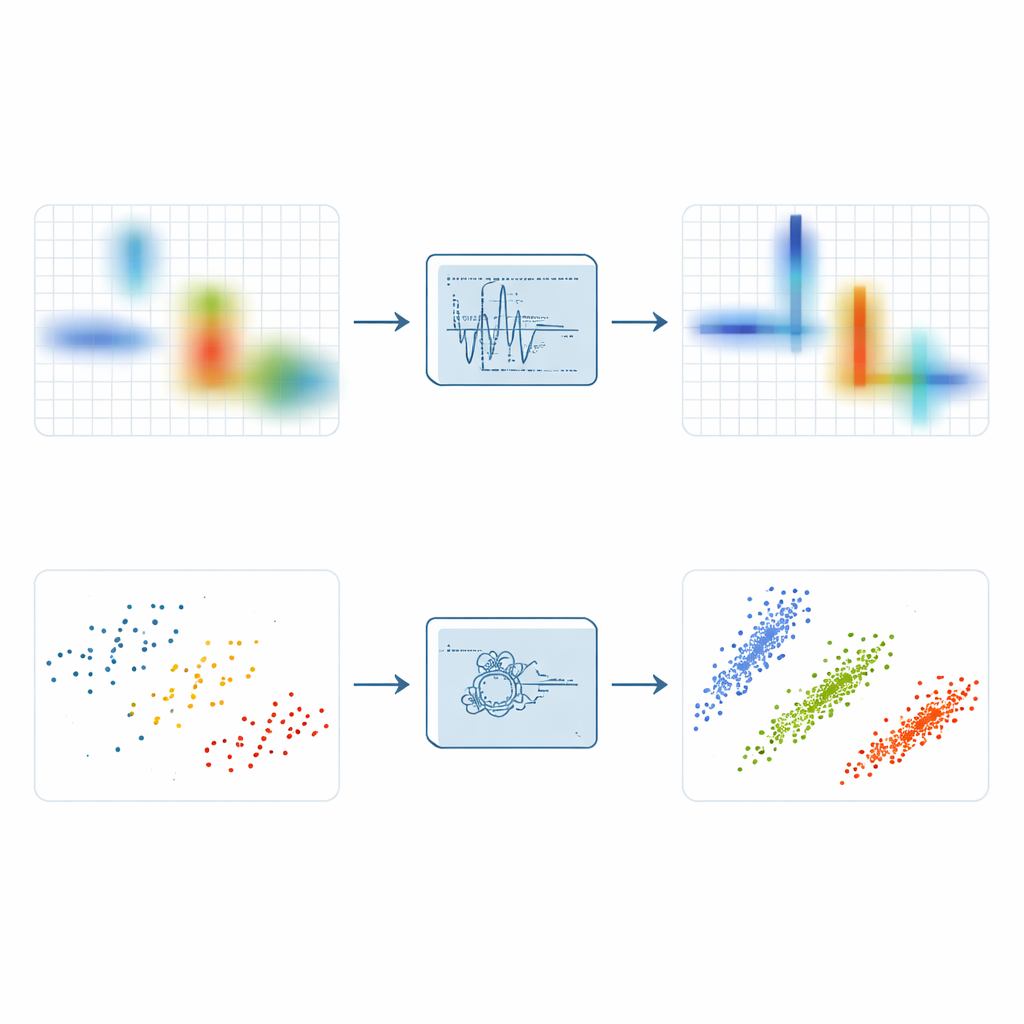
Waarom dit verder gaat dan theorie
Voor niet-specialisten is de belangrijkste conclusie dat de auteurs een betere manier hebben gevonden om verwarde signalen te bekijken en te groeperen, zodat elke originele stroom schoner kan worden teruggewonnen. Door zich te richten op lokale pieken in het tijd–frequentielandschap en deze kijk te combineren met een zorgvuldiger clusteringstrategie, maakt hun methode het onmogelijke caféprobleem — veel stemmen, te weinig oren — iets beter oplosbaar. Deze vooruitgang kan toepassingen ten goede komen variërend van satellietverbindingen die overlappende transmissies moeten scheiden tot medische systemen die zwakke biologische signalen in ruis moeten isoleren, en biedt helderdere informatie uit dezelfde beperkte metingen.
Bronvermelding: Li, X., Li, Z., Yao, R. et al. Source signal sparsity enhancement based on local maximum synchronous extraction transform algorithm for mixed matrix estimation in UBSS. Sci Rep 16, 9378 (2026). https://doi.org/10.1038/s41598-026-40055-y
Trefwoorden: blind source separation, signal sparsity, time–frequency analysis, clustering algorithms, wireless communications