Clear Sky Science · nl
De novo generatie en in silico screening van kandidaat anti-diabetische peptiden via een deep learning–attention raamwerk met fusie van fysisch-chemische kenmerken
Waarom slimmer peptidedesign belangrijk is voor diabetes
Diabetes treft honderden miljoenen mensen wereldwijd en bestaande medicijnen werken niet voor iedereen even goed. Veel behandelingen verliezen na verloop van tijd effectiviteit of veroorzaken bijwerkingen. Een veelbelovende nieuwe optie is een klasse van kleine eiwitten, anti-diabetische peptiden, die de bloedsuiker met hoge precisie kunnen bijsturen. De uitdaging is dat het vinden van nieuwe peptidegeneesmiddelen in het laboratorium traag en duur is. Deze studie introduceert een computergestuurde pijplijn die grote aantallen potentiële anti-diabetische peptiden kan bedenken en doorzoeken, en onderzoekers naar de meest veelbelovende kandidaten wijst om in de praktijk te testen.
Van bekende diabetespeptiden naar schone startdata
De onderzoekers begonnen met het samenstellen van een hoogwaardige verzameling peptiden die experimenteel zijn aangetoond de bloedsuikerspiegel te beïnvloeden, meestal door invloed op hormonen zoals GLP-1 of enzymen zoals DPP-IV. Deze vormden de “positieve” voorbeelden. Vervolgens bouwden ze een bijpassende “negatieve” set peptiden zonder gerapporteerde anti-diabetische werking, zorgvuldig gekozen zodat lengte, samenstelling en basische chemie op die van de positieve voorbeelden leken. Om te voorkomen dat het model op bijna-dubbele sequenties zou worden misleid, gebruikten ze sequentie-vergelijkingstools om zeker te stellen dat nauw verwante peptiden nooit zowel in de trainings- als in de testgroepen voorkwamen. Deze homologie-bewuste scheiding zorgde ervoor dat het systeem beoordeeld werd op zijn vermogen echt nieuwe patronen te herkennen in plaats van oude te onthouden.
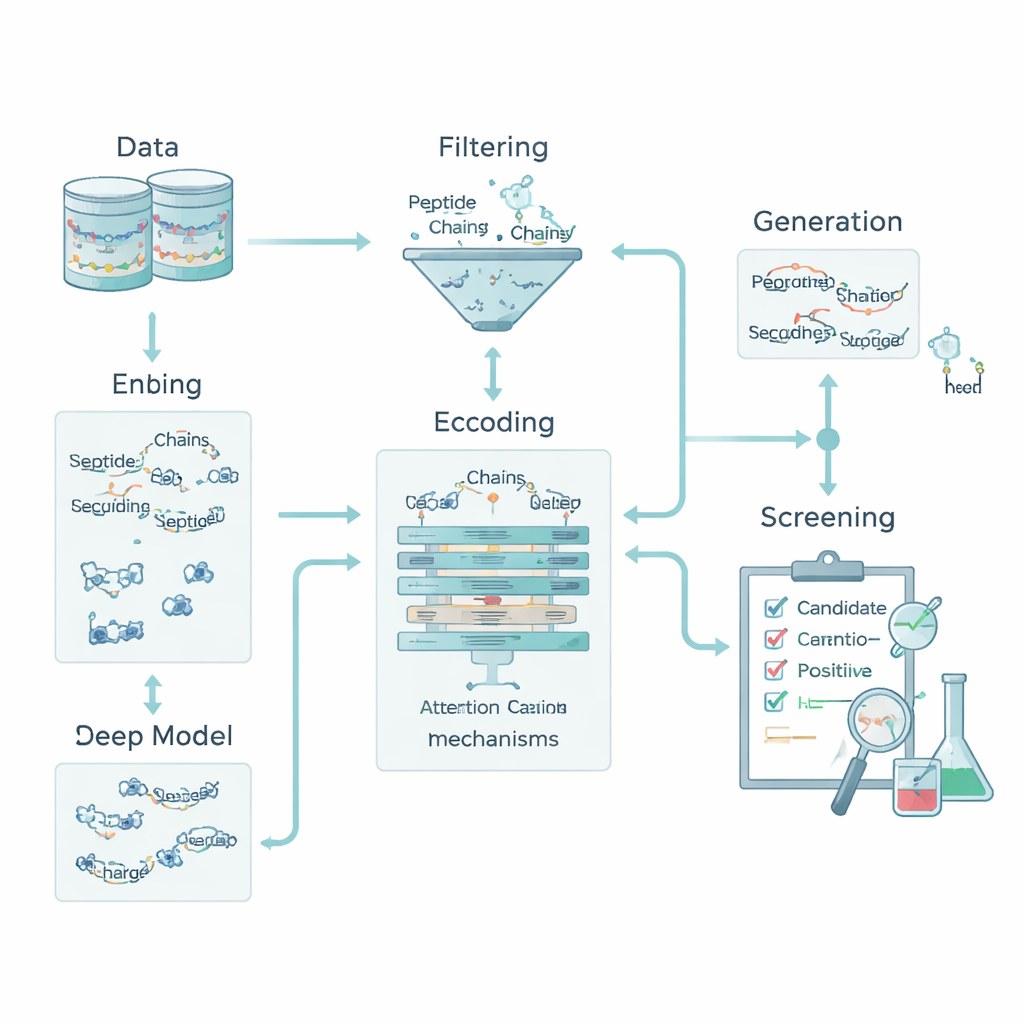
Chemie coderen zodat machines peptiden kunnen lezen
Voor een computer is een peptide slechts een reeks letters die aminozuren vertegenwoordigen. Om die letters aan biologie te koppelen, transformeerde het team elk aminozuur naar vijf basale chemische eigenschappen: hydrofoobheid (waterafstotendheid), elektrische lading, neiging tot waterstofbrugvorming, massa en of het een aromatische ring bevat. Dit veranderde elk peptide in een klein “plaatje” dat zowel volgorde als chemie vastlegt. Daarbovenop voegden ze descriptors op peptideniveau toe zoals totale lading, gemiddelde hydrofoobheid en de Boman-index, die gerelateerd is aan hoe sterk een peptide de neiging heeft aan andere eiwitten te binden. Samen stellen deze kenmerken het model in staat zowel naar lokale patronen—korte aminozuurmotieven—als naar globale eigenschappen te kijken die het gedrag van een peptide in het lichaam beïnvloeden.
Een deep learning-motor die zijn keuzes uitlegt
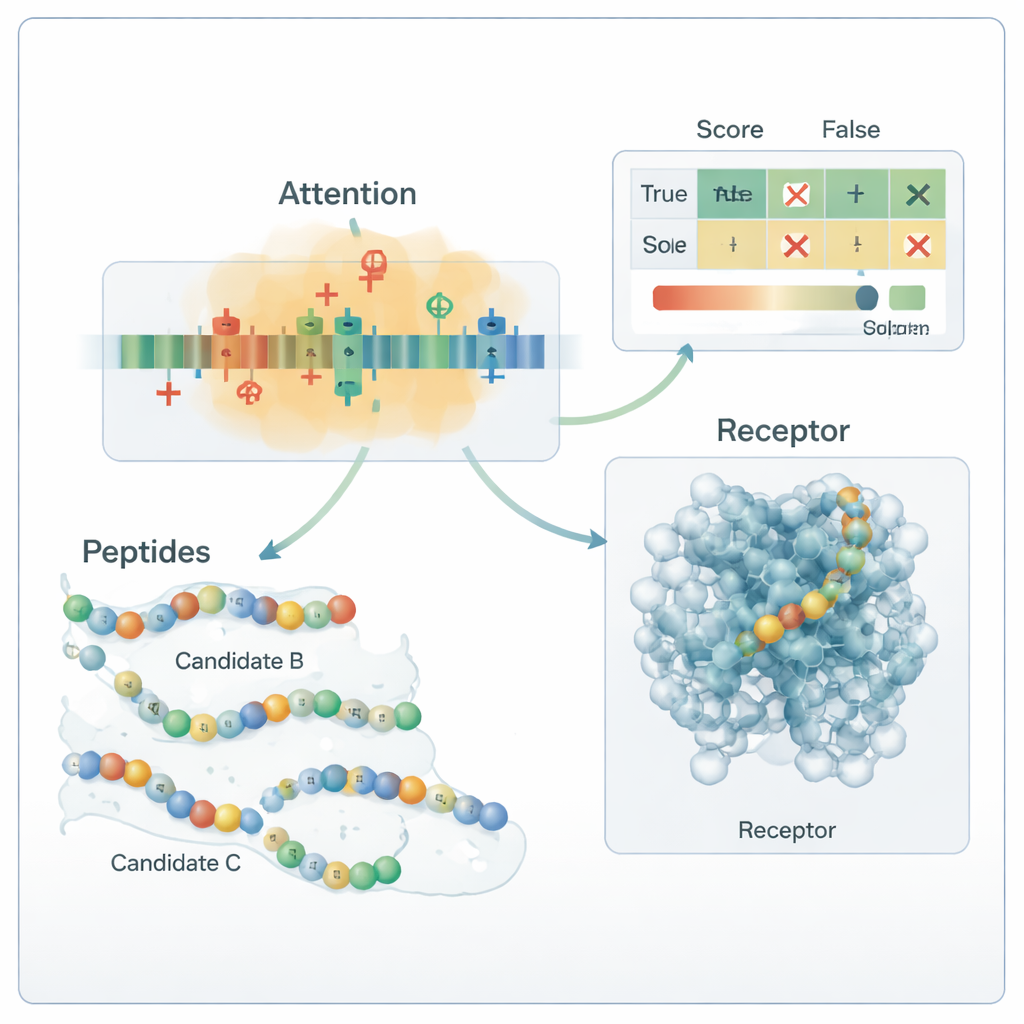
De kern van de pijplijn is een hybride deep learning-model. Een convolutioneel neuraal netwerk (CNN) scant langs het peptide en zoekt naar korte motieven die vaak in actieve peptiden voorkomen, vergelijkbaar met filters in een beeldherkenningssysteem. Daarboven leert een attention-laag welke posities in de sequentie het belangrijkst zijn, waardoor langafstandrelaties tussen ver verwijderde residuen worden vastgelegd. De output van deze sequentiemodule wordt gefuseerd met de globale chemische descriptors en doorgegeven aan meerdere standaard machine-learningclassifiers—support vector machines, decision trees, k-nearest neighbors en gradient-boosted trees. Een gespecialiseerde optimalisatiemethode, OptimizedTPE genoemd, stelt automatisch hun hyperparameters af en vindt een balans tussen nauwkeurigheid en het risico op overfitting. Het attention-mechanisme levert bovendien residu-niveau "belangrijkheidskaarten", waarmee wetenschappers kunnen zien welke delen van elk peptide de beslissingen van het model sturen.
Nieuwe kandidaten bedenken zonder dataderving
Om het geringe aantal bekende anti-diabetische peptiden te overwinnen, voegde het team een generatie-stap toe die alleen het trainingsproces voedt. Ze gebruikten een mix van strategieën—gerichte mutatie, motiefrecombinatie en een variational autoencoder—om nieuwe sequenties voor te stellen die lijken op, maar niet kopiëren van bekende actieve peptiden. Deze kandidaten werden vervolgens gescreend via strikte "descriptor-poorten" die realistische lading, grootte en bindingsgeneigdheid afdwingen, plus externe tools die de gelijkenis met bekende bioactieve peptiden scoren. Alleen sequenties die deze filters doorstaan en duidelijk onderscheiden blijven van alle testpeptiden worden behouden als zwak gelabelde positieven voor training; geen van hen wordt ooit gebruikt om het model te evalueren. Deze aanpak vergrootte de trainingsset terwijl een schone, onbevooroordeelde testset behouden bleef.
Hoe goed het systeem werkt en wat dat betekent
Getoetst aan een volledig onafhankelijke set van 180 experimenteel bestudeerde peptiden uit recente literatuur, labelde het raamwerk ongeveer 99 van de 100 sequenties correct, met zowel precisie als recall rond 0,99. In praktische termen betekent dit dat het zelden een echt anti-diabetisch peptide mist en zelden een inactief peptide als veelbelovend aanmerkt. Analyse van de attention-kaarten en mutatietests toonde aan dat het model chemisch plausibele regels heeft geleerd: het leunt sterk op positief geladen en bepaalde hydrofobe residuen die bekend zijn als belangrijk voor binding aan diabetesgerelateerde doelwitten. Moleculaire docking-simulaties suggereerden verder dat sommige van de nieuw gegenereerde peptiden plausibele contacten kunnen maken met de menselijke GLP-1 receptor. Hoewel deze voorspellingen nog laboratoriumbevestiging behoeven, toont de studie een reproduceerbare, biologisch gefundeerde manier om de enorme ruimte van mogelijke peptidegeneesmiddelen te verkennen en de weinigen te prioriteren die het meest waarschijnlijk kunnen helpen bij het beheersen van diabetes.
Bronvermelding: Asl, Z.R., Rezaee, K., Ansari, M. et al. De novo generation and in silico screening of anti-diabetic peptide candidates via a deep learning–attention framework with physicochemical feature fusion. Sci Rep 16, 6580 (2026). https://doi.org/10.1038/s41598-026-39985-4
Trefwoorden: anti-diabetische peptiden, deep learning, geneesmiddelenontwikkeling, peptidedesign, GLP-1 receptor