Clear Sky Science · nl
R-GAT: classificatie van kankerdocumenten met een grafgebaseerd residueel netwerk voor scenario’s met beperkte data
Waarom het ordenen van kankerpapers ertoe doet
Elke dag publiceren wetenschappers honderden nieuwe studies over kanker, van vroege detectie tot veelbelovende geneesmiddelen. Het merendeel van dit werk verschijnt eerst als korte samenvattingen, abstracts genoemd. Artsen, onderzoekers en beleidsmakers kunnen onmogelijk alles lezen, terwijl het missen van een belangrijk artikel de vooruitgang kan vertragen. Deze studie pakt een eenvoudige maar krachtige vraag aan: kunnen we een snel, lichtgewicht computersysteem bouwen dat automatisch abstracts over kanker sorteert op type kanker, zelfs wanneer slechts een bescheiden hoeveelheid gelabelde data en rekenkracht beschikbaar is?
Een slimmer manier om kankeronderzoek te lezen
De auteurs richten zich op vier soorten abstracts uit de PubMed-database: die over schildklierkanker, darmkanker, longkanker en meer algemene biomedische onderwerpen. Ze maakten een zorgvuldig gecontroleerde verzameling van 1.875 recente abstracts, ongeveer gelijk verdeeld over deze vier groepen. Die balans helpt vooringenomenheid naar één kankertype te vermijden. Voor de modellering werden de teksten schoongemaakt: woorden werden opgesplitst in tokens, spelling gecontroleerd, verwante woordvormen samengevoegd en niet-informatieve termen verwijderd. De schoongemaakte abstracts werden daarna met meerdere standaardmethoden naar numerieke vorm omgezet zodat verschillende modeltypen eerlijk vergeleken konden worden.
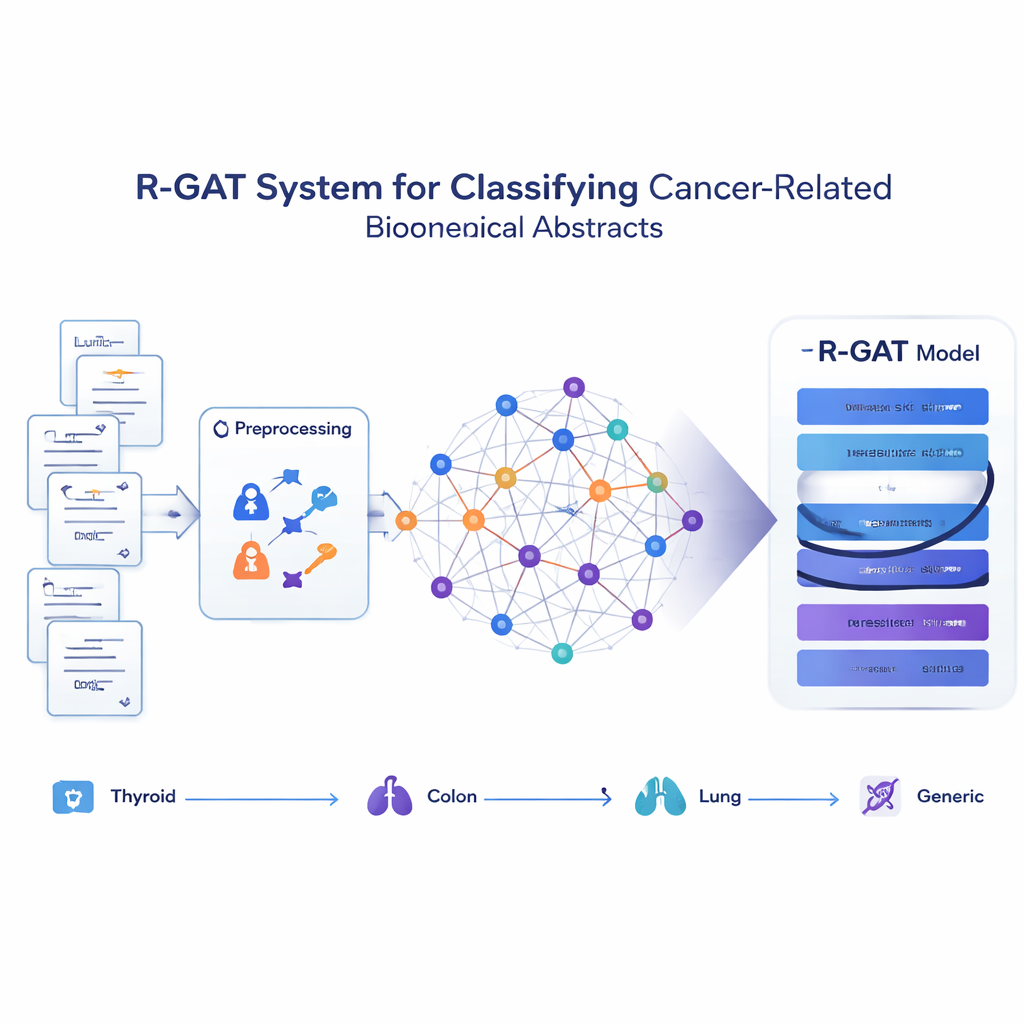
Papers omzetten in een netwerk van ideeën
In plaats van elk abstract te behandelen als een geïsoleerde reeks woorden, ziet de voorgestelde methode, R-GAT (Residual Graph Attention Network), de hele verzameling als een netwerk. In dit netwerk is elk abstract een knooppunt en geven verbindingen aan hoe vergelijkbaar twee abstracts inhoudelijk zijn. Als twee artikelen nauw verwante onderwerpen behandelen, is de verbinding tussen hen sterk; zo niet, dan is deze zwak of afwezig. Dit stelt het model in staat een abstract te bekijken in de context van zijn buren, wat nabootst hoe een menselijke lezer een studie beter kan begrijpen door te weten wat gerelateerd werk zegt.
Hoe het nieuwe model leert van buren
R-GAT bouwt voort op twee kernideeën uit moderne kunstmatige intelligentie: attention en residual connections. Attention laat het model meer focussen op de meest relevante naburige abstracts in het netwerk, in plaats van alle buren gelijk te behandelen. Meerdere attention-“heads” zoeken tegelijkertijd naar verschillende soorten patronen. Residual connections fungeren als snelkoppelingen die informatie door de diepere lagen van het netwerk doorgeven, waardoor het model voorkomt dat belangrijke signalen verloren gaan tijdens het leren. Na verwerking van de grafiek via meerdere attention-lagen en deze snelkoppelingen condenseert het systeem informatie uit het gehele netwerk tot een compacte samenvatting die wordt gevoed aan een eindklassificator die voorspelt bij welke van de vier categorieën ieder abstract hoort.
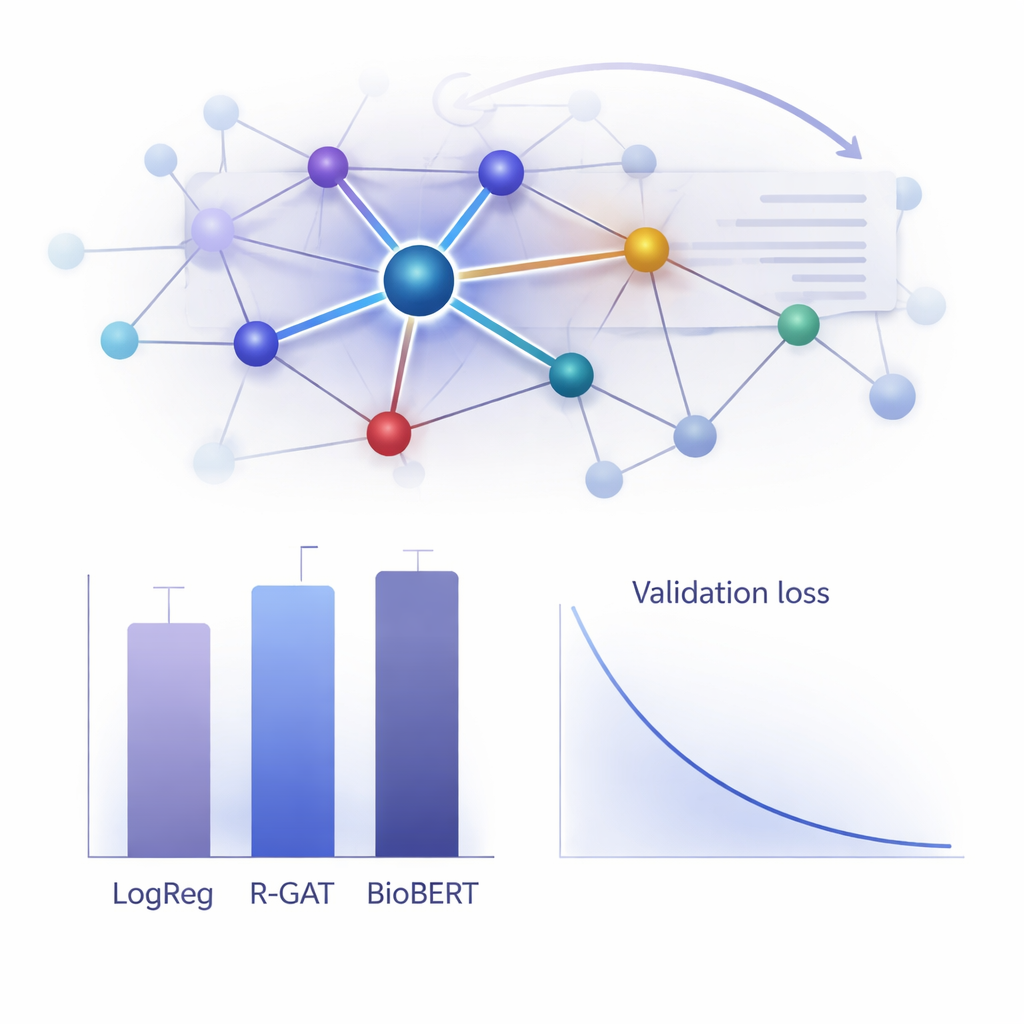
Hoe goed werkt het in de praktijk?
Om de waarde van R-GAT te beoordelen, vergeleken de auteurs het met een breed scala aan alternatieven, van klassieke lineaire modellen tot state-of-the-art transformermodellen zoals BioBERT, die populair maar rekenintensief zijn. Verrassend genoeg behaalde een eenvoudige logistieke regressie met woordtelfeatures de hoogste ruwe score op deze dataset, en BioBERT presteerde ook uitstekend — maar beide hadden nadelen, waaronder afhankelijkheid van specifieke featurekeuzes of de behoefte aan substantiële rekenmiddelen. R-GAT behaalde een macro F1-score van ongeveer 0,96, dicht bij de beste modellen, terwijl het zeer stabiele resultaten liet zien over verschillende train–test-splits. Zorgvuldige tests waarbij attention of residual connections werden verwijderd, toonden duidelijke prestatieverliezen, wat bevestigt dat beide componenten cruciaal zijn voor de robuustheid van het model wanneer data beperkt zijn.
Wat dit betekent voor toekomstig kankeronderzoek
Voor een leek is de conclusie eenvoudig: R-GAT is een praktisch instrument dat helpt kankerpapers op type kanker te sorteren met hoge en consistente nauwkeurigheid, zonder grote datasets of dure hardware te vereisen. Het vervangt niet de krachtigste taalmodellen op de markt, maar biedt een betrouwbaar middenweg — vooral nuttig voor ziekenhuizen, onderzoeksgroepen of volksgezondheidsteams die betrouwbare, reproduceerbare resultaten nodig hebben onder strakke data- en budgetbeperkingen. Door zowel hun model als hun zorgvuldig samengestelde dataset openlijk vrij te geven, bieden de auteurs ook een gedeelde benchmark die anderen kunnen gebruiken om verbeterde systemen te bouwen en te testen. Op de lange termijn kunnen zulke hulpmiddelen het voor experts veel eenvoudiger maken om het kankeronderzoek bij te houden en nieuwe bevindingen om te zetten in betere zorg.
Bronvermelding: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
Trefwoorden: kankerinformatica, biomedische tekstmining, documentclassificatie, graph neural networks, leren met beperkte data