Clear Sky Science · nl
Machine learning voor het voorspellen van CKD-fasen bij patiënten met autosomaal dominant polycysteuze nierziekte: een landelijke cohortstudie in Japan
Waarom dit belangrijk is voor alledaagse gezondheid
Nierziekte sluipt vaak geruisloos op en tegen de tijd dat symptomen zich openbaren, is schade soms moeilijk om te keren. Voor mensen die geboren zijn met autosomaal dominante polycysteuze nierziekte (ADPKD) — een aandoening waarbij vloeistofgevulde zakjes langzaam gezond nierweefsel verdringen — kan de kennis over hoe snel hun nieren kunnen falen doorslaggevend zijn voor belangrijke levenskeuzes. Deze studie onderzoekt of moderne computertechnieken, bekend als machine learning, routinematige medische controlegegevens kunnen gebruiken om te voorspellen hoe iemands nierfunctie zich de komende drie jaar zal ontwikkelen, zonder te steunen op dure genetische tests of geavanceerde scans.
Een veelvoorkomende ziekte met onzekere vooruitzichten
ADPKD is een van de meest voorkomende erfelijke nierziekten en een belangrijke oorzaak van chronische nierziekte (CKD). Veel getroffenen hebben uiteindelijk dialyse of een transplantatie nodig, maar het tempo van achteruitgang verschilt sterk. Sommigen gaan langzaam achteruit en behouden redelijke nierfunctie tot op hoge leeftijd; anderen bereiken nierfalen in hun veertig- of vijftiger jaren. Artsen willen patiënten vroeg in risicogroepen indelen, zodat behandeling en monitoring kunnen worden afgestemd. Bestaande voorspellingsinstrumenten zijn vaak afhankelijk van uitgebreide genetische tests of volledige MRI-scans van de nieren, die in veel zorgsystemen — waaronder het Japanse nationale verzekeringssysteem — niet routinematig beschikbaar zijn. Die leemte motiveerde de auteurs om te zoeken naar een eenvoudiger, breed toepasbare manier om een toekomstige CKD-fase in te schatten.
Een nationaal register omvormen tot een voorspellend instrument
De onderzoekers maakten gebruik van een landelijk Japans register dat informatie vastlegt van mensen met moeilijk te behandelen aandoeningen die overheidssteun ontvangen. Zij concentreerden zich op 2.737 volwassenen met ADPKD die zich tussen 2015 en 2021 voor het eerst registreerden. Voor elke persoon verzamelde het team gegevens uit de initiële aanvraag — waaronder bloedwaarden, urineonderzoek, basis lichaamsmetingen, bloeddruk en door arts genoteerde niergrootte — en keken vervolgens naar de CKD-fase van die persoon drie jaar later. De CKD-fase, die voornamelijk is gebaseerd op hoe goed de nieren het bloed filteren, dient zowel als maat voor ziektezwaarte als een belangrijk criterium voor financiële hulp in Japan.
Hoe de computers leerden van patiëntgegevens
Om hun voorspellingssysteem te bouwen, testten de wetenschappers drie gangbare machine learning-methoden: random forest, support vector machine en naïeve Bayes. Alle drie leren van voorbeelden in plaats van van vaste formules. De dataset werd gesplitst in een trainingsgedeelte, gebruikt om elk model te verfijnen, en een testgedeelte om te beoordelen hoe goed de uiteindelijke modellen presteerden op onbekende gevallen. De computers probeerden te voorspellen welke van meerdere CKD-fasen elke patiënt na drie jaar zou bereiken. De random forest-methode, die veel eenvoudige beslis"bomen" combineert tot een stemmende commissie, liet de beste prestaties zien en voorspelde de fase correct bij ongeveer 73% van de testpatiënten. De support vector machine, die voornamelijk rechte-lijnrelaties tussen factoren en uitkomst veronderstelt, presteerde minder goed, terwijl het eenvoudige naïeve Bayes-model daartussenin viel.
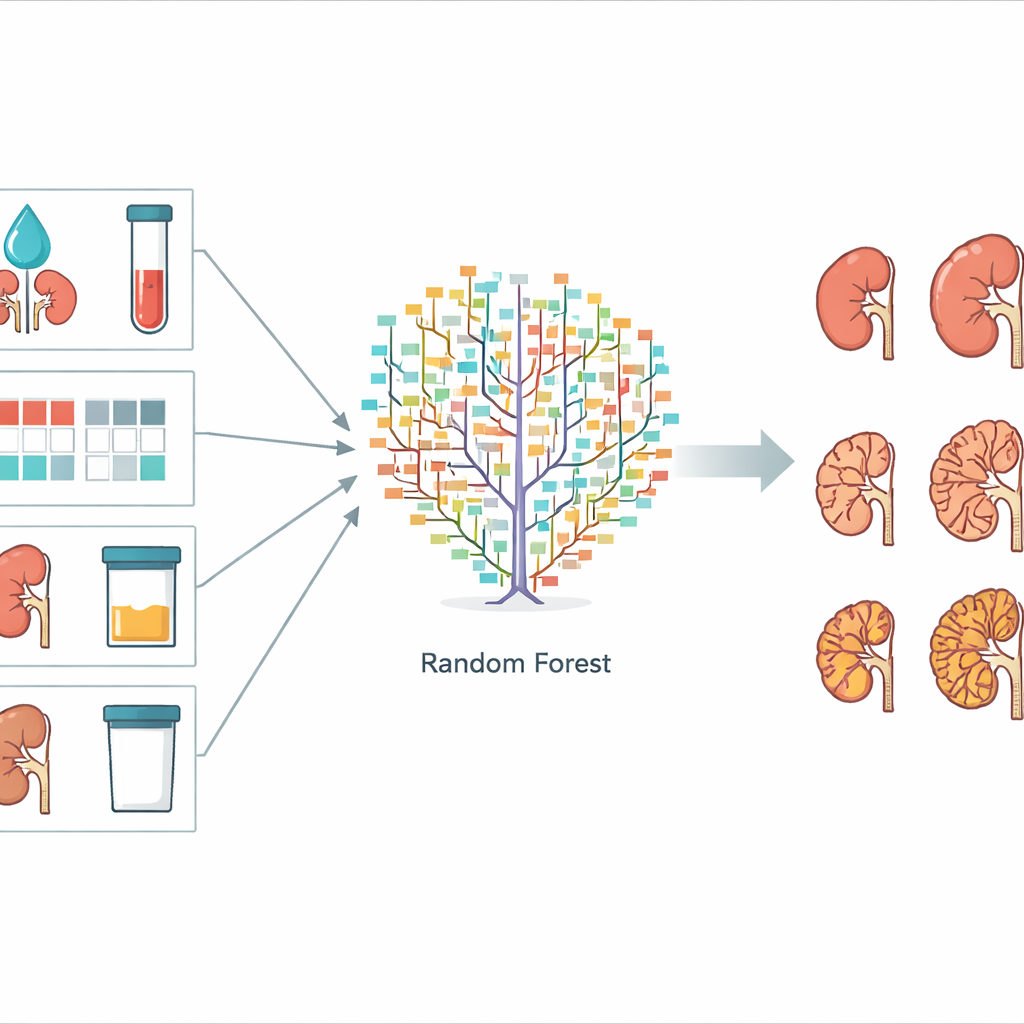
Wat het meest telde voor de voorspelling
Het team onderzocht ook welke informatie het meest nuttig was voor het random forest-model. Ze maten dit door één factor per keer te schudden en te zien hoeveel de voorspellingen verslechterden. Vijf kenmerken staken er duidelijk uit als bijzonder belangrijk: de geschatte filtratiesnelheid van de nieren (eGFR), het creatininegehalte in het bloed (een andere maat voor nierfunctie), een kleurgecodeerde CKD "heatmap" die filtratie en urine-eiwit combineert, de hoeveelheid eiwit in de urine en het totale volume van beide nieren. Dit zijn allemaal metingen die tijdens gewone polikliniekbezoeken kunnen worden verzameld, zonder gespecialiseerde beeldbestanden of genoomsequencing. Andere items, zoals het exacte aantal cysten op scans, droegen weinig bij, wat suggereert dat ze niet essentieel zijn voor een praktisch voorspellingsinstrument.
Wat dit betekent voor patiënten en artsen
Voor mensen met ADPKD suggereert de studie dat een zorgvuldig getraind computermodel dat gevoed wordt met standaard laboratoriumtests en basisimaging-samenvattingen een redelijk accurate voorspelling kan geven van de niergezondheid drie jaar vooruit. Omdat het best presterende model complexe, niet-lineaire relaties tussen factoren kan vastleggen, is het mogelijk beter geschikt dan traditionele risicokaarten voor deze levenslange, variabele ziekte. Hoewel het werk beperkt is tot Japanse patiënten en geen oorzaak-en-gevolg kan bewijzen, wijst het in de richting van kliniekvriendelijke hulpmiddelen die helpen te identificeren wie waarschijnlijk snel verslechtert en wie een langzamer beloop heeft. Simpel gezegd concludeert het artikel dat machine learning — met name de random forest-benadering — alledaagse medische gegevens kan omzetten in geïndividualiseerde vooruitzichten voor de nieren, wat gepersonaliseerde zorg en betere planning voor patiënten met ADPKD ondersteunt.
Bronvermelding: Shimada, Y., Kataoka, H., Nishio, S. et al. Machine learning for predicting CKD stages in patients with autosomal dominant polycystic kidney disease: a nationwide cohort study in Japan. Sci Rep 16, 8771 (2026). https://doi.org/10.1038/s41598-026-39885-7
Trefwoorden: polycysteuze nierziekte, chronische nierziekte, machine learning, risicovoorspelling, gepersonaliseerde geneeskunde