Clear Sky Science · nl
EchoNet++: Een meertalig audiocommentaardataset voor voetbalwedstrijden
Waarom het geluid van voetbal ertoe doet
Wie een grote wedstrijd heeft gezien, weet dat het gebrul van het publiek en het op- en neergaan van de stem van de commentator net zozeer deel uitmaken van het drama als de doelpunten zelf. Toch richt bijna alle moderne sporttechnologie zich nog steeds op wat camera’s zien, niet op wat microfoons horen. Dit artikel introduceert EchoNet en EchoNet++, een gecombineerd systeem en dataset die het chaotische geluid van professionele voetbaluitzendingen uit veel landen omzetten in schone, doorzoekbare tekst die computers kunnen analyseren. Daardoor wordt het mogelijk om tactiek, emotie en verhalen te bestuderen over competities en talen heen, op een schaal die geen enkel menselijk vertaalteam kan evenaren.
Van lawaaiig stadion naar schoon signaal
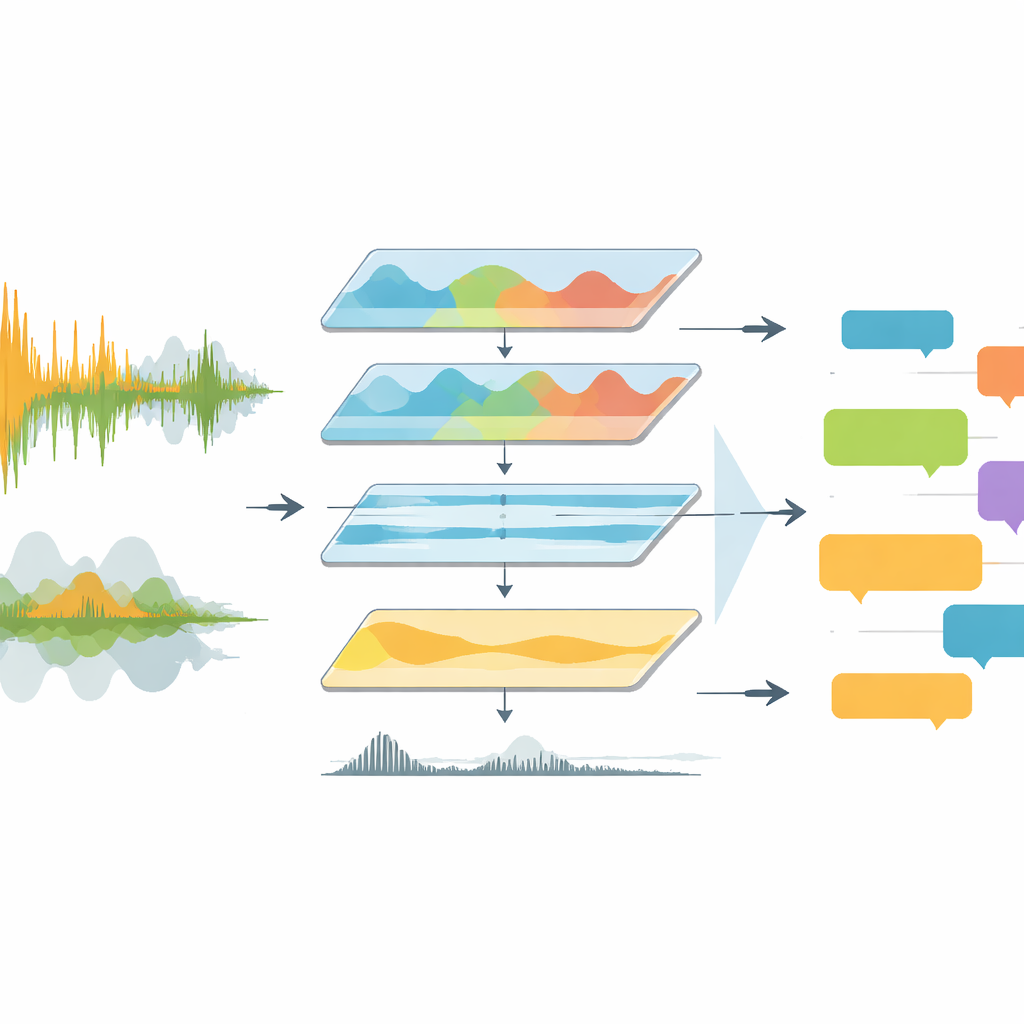
Geregisseerde wedstrijden zijn akoestisch rommelig. Commentatoren spreken over scanderende fans, stadionmuziek en plotselinge uitbarstingen van gejuich heen. Vorige hulpmiddelen voerden dit ruwe lawaai meestal rechtstreeks in spraakherkenningssoftware, die worstelde met overlappende stemmen, wisselende talen en slechte geluidskwaliteit. EchoNet pakt het probleem aan als een technische pijplijn in plaats van als één slim model. Het begint met het extraheren van de audiotrack uit volledige wedstrijdvideo’s en het omzetten naar een standaard, hoogwaardige vorm. Het systeem gaat daarna naar het frequentiedomein, waarbij het zich richt op het bereik waarin menselijke spraak zich bevindt en ronkende bastonen en schelle artefacten onderdrukt. Een deep-learningtool genaamd Demucs scheidt vervolgens spraakachtige geluiden van de rest, waardoor een veel duidelijkere track overblijft voor latere verwerkingsstappen.

Machines leren stemmen van lawaai te onderscheiden
Zodra het geluid is opgeschoond, moet EchoNet beslissen wanneer iemand daadwerkelijk spreekt en of die stem bij een commentator of het publiek hoort. Hiervoor gebruiken de auteurs een neuraal netwerk voor spraakactiviteitsdetectie dat de audio in korte vensters scant en elk moment labelt als spraak of geen spraak. Gedetecteerde spraakfragmenten worden daarna nauwkeuriger bekeken. Segmenten die het regelmatige ritme en de structuur van gesproken taal tonen, worden als commentaar gemarkeerd, terwijl diegene die lijken op uitbarstingen van chaotische energie als toeschouwers worden aangemerkt. Deze scheiding is belangrijk: zinnen van commentatoren bevatten tactische en verhalende informatie, terwijl publieksreacties vooral emotionele pieken signaleren, zoals doelpunten of net gemiste kansen. Door deze bronnen te splitsen, kan het systeem ze later in de analyse verschillend behandelen.
Verschillende talen tot één verhaal smeden
EchoNet voert elk commentaarsegment in meerdere varianten van het Whisper automatische spraakherkenningsmodel, inclusief standaard- en snelheidsgeoptimaliseerde varianten. Deze modellen zijn getraind op honderden duizenden uren meertalige audio, waardoor ze goed geschikt zijn voor Europa’s belangrijkste competities, waar omroepen schakelen tussen Engels, Duits, Spaans, Italiaans, Frans en andere talen. Het systeem legt van elk segment de timing, taal en transcript vast in gestructureerde JSON-bestanden die gekoppeld zijn aan de wedstrijddelen. Voor niet-Engelse clips transcribeert EchoNet eerst in de oorspronkelijke taal en stuurt de tekst vervolgens naar een vertaalengine om Engelse versies te verkrijgen. Dit twee-stappenontwerp houdt transcriptie- en vertaalfouten gescheiden, wat onderzoekers helpt bij het debuggen van fouten en het vergelijken van taalspecifiek gedrag.
Meten hoe goed het werkt
Aangezien een pijplijn slechts zo sterk is als zijn zwakste schakel, evalueren de auteurs EchoNet vanuit meerdere invalshoeken. Zij introduceren een nieuwe "Report Accuracy"-score die traditionele woordfoutpercentages omzet in een meer intuïtief percentage praktisch correcte inhoud. Over drie datasets—waaronder hun nieuw vrijgegeven EchoNet++-collectie van 20 volledige wedstrijden—verlaagt preprocessing met EchoNet consequent transcriptiefouten en verhoogt de Report Accuracy met enkele punten voor elk getest Whisper-model. Maten voor signaalkwaliteit, die schatten hoe begrijpelijk de spraak voor een menselijke luisteraar zou zijn, verbeteren ook duidelijk na filtering, ruisonderdrukking en normalisatie. Ablatie-studies, waarin individuele componenten zoals het banddoorlaatfilter of de spraakdetector worden verwijderd, laten zien dat elke stap wezenlijk bijdraagt aan zowel helderheid als correctheid.
Wat dit betekent voor fans en analisten
Concreet bieden EchoNet en EchoNet++ een betrouwbare manier om urenlange, lawaaierige, meertalige wedstrijdcommentaren om te zetten in schone, tijdgealigneerde tekst en publieksindicatoren. Met deze basis kunnen ontwikkelaars automatisch sleutelgebeurtenissen detecteren aan de hand van de toon en woorden van de commentator, die momenten koppelen aan pieken in publieksreactie en gedetailleerde samenvattingen of compilaties bouwen zonder handmatige registratie. Cruciaal is dat de dataset en code worden vrijgegeven voor onderzoeksgebruik, waardoor de gemeenschap een gedeeld, reproduceerbaar platform krijgt om voetbal via geluid te bestuderen. Voor zowel fans als analisten duwt dit werk de sportverslaggeving richting een toekomst waarin de soundtrack van de wedstrijd even doorzoekbaar en analyseerbaar wordt als de video zelf.
Bronvermelding: Majeed, F., Nazir, M., Agus, M. et al. EchoNet++: A multilingual soccer match audio commentary dataset. Sci Rep 16, 8884 (2026). https://doi.org/10.1038/s41598-026-39884-8
Trefwoorden: voetbalanalyse, sportaudio, spraakherkenning, meertalige commentaar, uitzendinganalyse