Clear Sky Science · nl
Cross‑validatie de echte wereld inbrengen om de overdraagbaarheid van satellietgebaseerde vegetatiemodellen te evalueren
Waarom gras vanuit de ruimte volgen ertoe doet
Graslanden voeden vee, ondersteunen wilde dieren en slaan koolstof op, en veel veehouders en natuurbeschermers vertrouwen tegenwoordig op satellieten om in de gaten te houden hoeveel plantaardig materiaal er op de grond staat. Nieuwe kaarten beloven bijna‑realtime beelden van de toestand van weiden, maar hun nauwkeurigheid in uitzonderlijke jaren—zoals bij hevige droogte of juist zeer natte seizoenen—wordt vaak als vanzelfsprekend aangenomen. Deze studie stelt een eenvoudige maar cruciale vraag: hoe goed houden de computermodellen achter deze satellietkaarten het vol wanneer de echte wereld weigert te lijken op de data waarvoor ze zijn getraind?
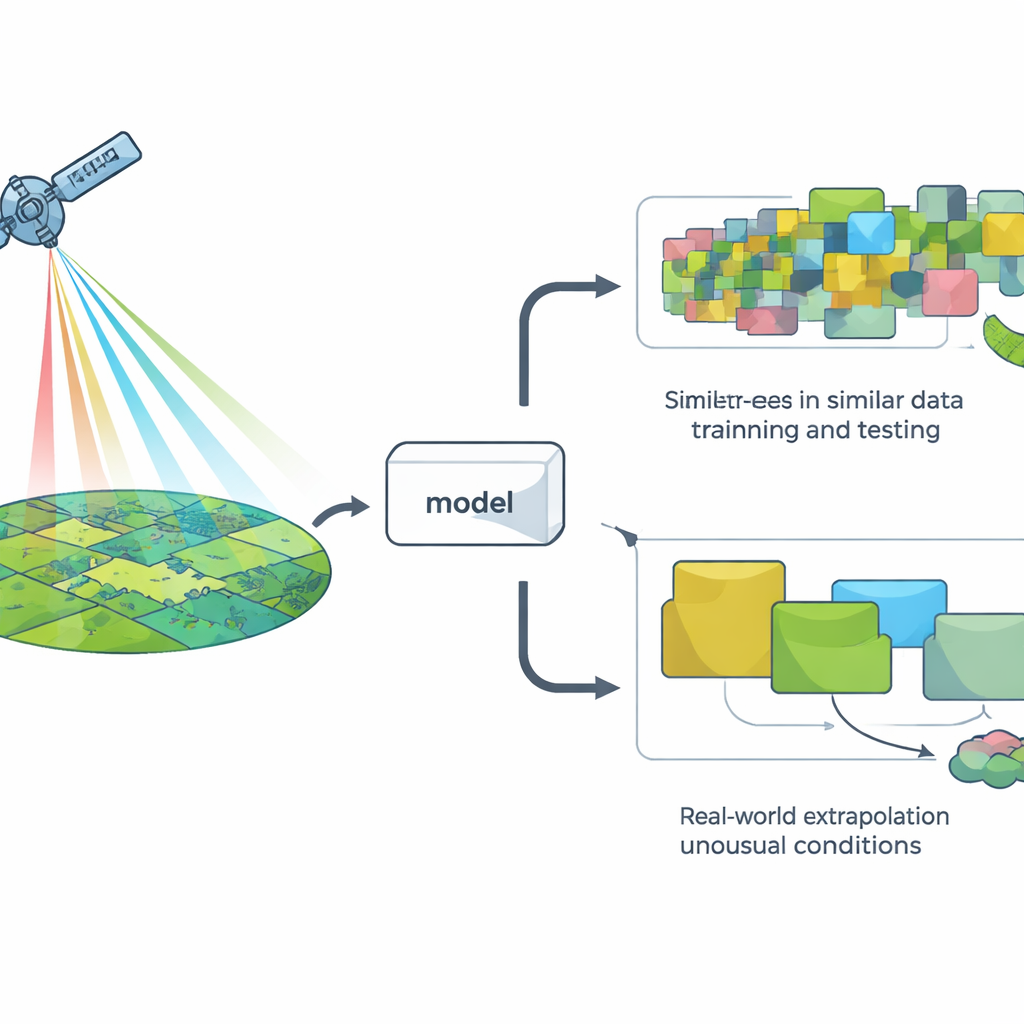
Modellen beoordelen op de makkelijke manier versus de moeilijke manier
Om een model te beoordelen gebruiken onderzoekers meestal een methode die cross‑validatie heet: ze verbergen een deel van de data, trainen het model op de rest en kijken hoe goed het de verborgen punten voorspelt. De meest gangbare versie splitst de data willekeurig, wat voor veel problemen prima werkt maar stilzwijgend aanneemt dat alle waarnemingen onafhankelijk zijn. Op landschapsniveau valt die veronderstelling vaak uiteen: nabijgelegen locaties en aangrenzende jaren lijken van uit de ruimte vaak op elkaar. Daardoor kan willekeurige splitsing de indruk wekken dat een model met “nieuwe” situaties te maken heeft, terwijl het in werkelijkheid vooral meer van hetzelfde ziet.
Satellietmodellen aan echte wereldtesten onderwerpen
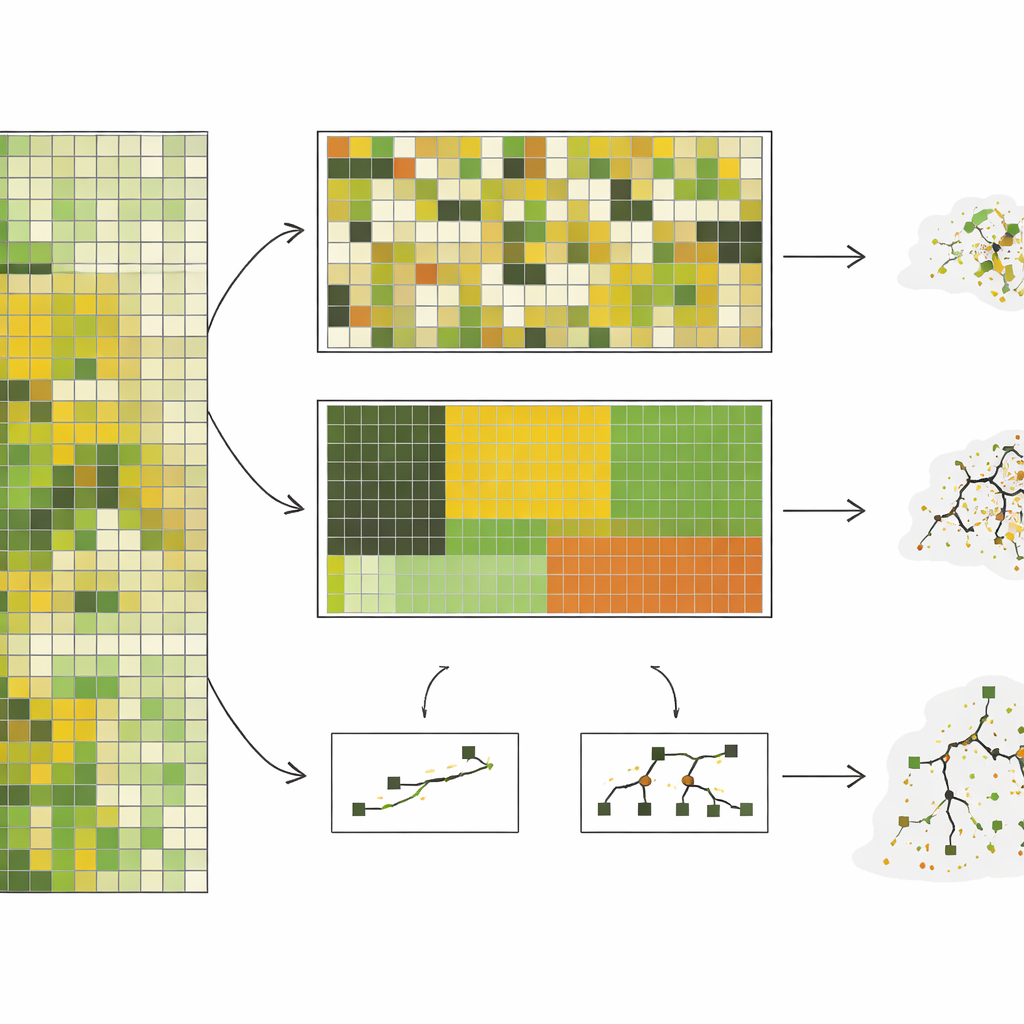
De auteurs verzamelden bijna 10.000 veldmetingen van staande kruidachtige biomassa—kortom hoeveel begraasbaar plantmateriaal aanwezig is—uit een shortgrass‑steppe in Colorado, verzameld over 10 jaar. Ze koppelden deze met gedetailleerde satellietbeelden en trainden vervolgens zeven verschillende typen computermodellen, variërend van eenvoudige lineaire benaderingen tot complexe beslisboomsystemen. In plaats van alleen willekeurige splitsingen te gebruiken, testten ze vijf manieren om data achter te houden: per willekeurig gekozen perceel, per weilandblok, per ecologische locatiecategorie, per jaar en per clusters van pixels die spectraal van elkaar verschilden. Deze laatste twee benaderingen, vooral groeperen per jaar en per spectrale clusters, dwongen de modellen te voorspellen voor omstandigheden die echt verschilden van wat ze eerder hadden gezien.
Als de toekomst anders oogt dan het verleden
Gemiddeld daalde de modelprestatie sterk naarmate de testen zwaarder werden. Bij willekeurige splitsing zagen complexe modellen zoals random forests er indrukwekkend uit en verklaarden ze ongeveer driekwart van de variatie in biomassa. Maar wanneer ze moesten voorspellen voor een volledig onzichtbaar jaar—een realistische taak voor bijna‑realtime monitoring—viel hun nauwkeurigheid terug, en deden relatief simpele modellen die een handvol gecombineerde satellietvariabelen gebruikten het even goed of beter. In de meest extreme test, waarin data zo verschillend mogelijk van elkaar werden gegroepeerd, stortte de nauwkeurigheid van de complexe modellen in, terwijl de betere eenvoudige modellen een matige, beter voorspelbare prestatie behielden. De studie toonde ook dat complexe modellen zeer gevoelig waren voor de representatie van zeldzame omstandigheden, zoals ernstige droogtes, in de trainingsgegevens, en soms zeer slecht presteerden in die risicovolle scenario’s.
Robuuste werkpaarden verslaan opvallende sprinters
Naast ruwe nauwkeurigheid onderzocht het team hoe consistent elk model was wanneer het opnieuw werd getraind met licht verschillende subsets van jaren. Eenvoudigere methoden, met name partial least squares‑regressie, blijken keer op keer dezelfde belangrijke satellietsignalen te selecteren, vergen slechts een paar afstemmingskeuzes en leveren stabielere resultaten over jaren heen. Complexere benaderingen veranderden vaak welke inputs ze gebruikten, hadden veel verschillende tuninginstellingen nodig en vertoonden grote schommelingen in prestatie van de ene trainingsrun naar de andere. Voor terreinbeheerders die kaarten elk jaar moeten bijwerken naarmate nieuwe data binnenkomen, kan dit soort stabiliteit net zo belangrijk zijn als pieknauwkeurigheid in een gunstig jaar.
Wat dit betekent voor het gebruik van satellietkaarten op het terrein
Voor mensen die afhankelijk zijn van satellietgebaseerde vegetatiekaarten om te beslissen wanneer en waar vee te laten grazen, te reageren op droogte of de gezondheid van ecosystemen te volgen, draagt deze studie een heldere boodschap. Gangbare testgewoonten die data willekeurig door elkaar husselen kunnen een te rooskleurig beeld schetsen van hoe goed een model zal presteren wanneer het weer omslaat naar extreme omstandigheden of wanneer het in nieuwe gebieden wordt toegepast. Wanneer modellen worden geëvalueerd op manieren die hun gebruik in de echte wereld nabootsen—voorspellen voor nieuwe jaren, nieuwe ecologische omgevingen of zelden geziene omstandigheden—kunnen eenvoudigere, goed‑gedraagde methoden complexere overtreffen en betrouwbaardere richtlijnen geven. In de praktijk betekent dit dat ontwikkelaars moeten rapporteren hoe hun modellen presteren onder verschillende zwaardere, realistischere tests, en dat gebruikers moeten zoeken naar producten waarvan de prestaties zijn gecontroleerd in de soorten uitdagende situaties waarmee zij het meest te maken zullen krijgen.
Bronvermelding: Kearney, S.P., Augustine, D.J., Porensky, L.M. et al. Bringing cross-validation into the real world to evaluate transferability of satellite-based vegetation models. Sci Rep 16, 9383 (2026). https://doi.org/10.1038/s41598-026-39866-w
Trefwoorden: satellietvegetatiekaarten, cross‑validatie, graslandbiomassa, machinelearningmodellen, droogtemonitoring