Clear Sky Science · nl
Kalibratie van diepe classificatie‑modellen met dynamische betrouwbaarheidspropagatie en adaptieve normalisatie
Waarom vertrouwen op AI‑betrouwbaarheid ertoe doet
Moderne kunstmatige intelligentiesystemen geven niet alleen aan wat ze denken dat op een foto of sensorlezing staat — ze rapporteren ook hoe zeker ze daarover zijn. Die zelfgerapporteerde zekerheid is cruciaal in veiligheid‑kritieke omgevingen zoals medische beeldvorming, autonoom rijden of industriële monitoring, waar een verkeerde inschatting van vertrouwen gevaarlijk kan zijn. Toch staan hedendaagse diepe neurale netwerken erom bekend dat ze te zeker zijn over hun fouten, en bestaande oplossingen falen vaak wanneer de data onevenwichtig zijn of uit veranderende omgevingen komen. Dit artikel introduceert een nieuwe methode, Dynamic Confidence Propagation with Alternating Normalization (DCP‑AN), ontworpen om de betrouwbaarheidscores van AI‑systemen eerlijker, stabieler en efficiënter te maken onder realistische, veranderende omstandigheden.
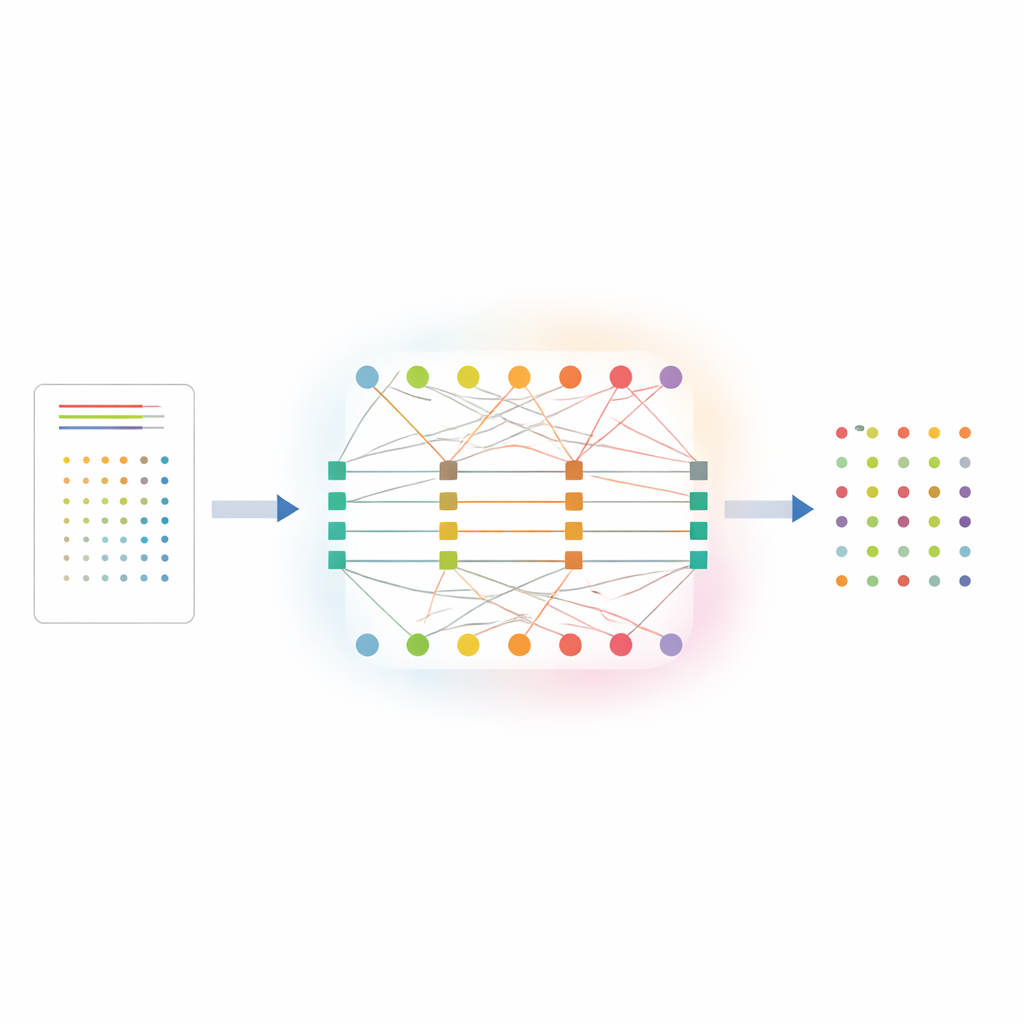
Wanneer slimme machines té zeker van zichzelf zijn
De meest gebruikte deep‑learningmodellen worden getraind om het juiste label te voorspellen, niet om te beoordelen hoe betrouwbaar elke voorspelling is. Hierdoor kan een netwerk 99% “zeker” zijn dat een afbeelding een kat toont terwijl het in werkelijkheid een hond is. Standaard kalibratietechnieken, zoals temperature scaling of het indelen van voorspellingen in betrouwbaarheidsbakken, proberen dit na de training te corrigeren door globale aanpassingen toe te passen. Deze methoden behandelen echter alle categorieën en voorbeelden op dezelfde manier. In de echte wereld zijn data zelden gebalanceerd: een paar veelvoorkomende ‘head’ klassen hebben veel voorbeelden, terwijl zeldzame ‘tail’ klassen maar een handvol keren voorkomen. Netwerken hebben de neiging overgeconfi dent te zijn voor veelvoorkomende klassen en ondergeconfi dent voor zeldzame, een kloof die statische, one‑size‑fits‑all correcties niet kunnen dichten — vooral wanneer de data‑distributie verschuift tussen domeinen, bijvoorbeeld van artistieke schetsen naar foto’s uit de echte wereld.
Een nieuwe manier om informatie tussen data en labels te delen
DCP‑AN pakt dit probleem aan door expliciet te modelleren hoe vertrouwen zou moeten stromen tussen individuele voorbeelden en de klassen waartoe ze behoren. De methode representeert de relatie tussen voorbeelden en klassen als een tweelaags netwerk: één laag knopen voor voorbeelden, een andere voor klassen, verbonden door gewogen koppelingen die de initiële predictiekracht coderen. Vervolgens wordt vertrouwen verfijnd via een tweestapsinteractie. In de eerste stap stroomt informatie van voorbeelden naar klassen, waarbij wordt aangepast hoe scherp de voorspellingen van elke klasse verdeeld zijn, gestuurd door hoe onzeker die klasse op dat moment lijkt. In de tweede stap stroomt informatie terug van klassen naar voorbeelden, waardoor het betrouwbaarheidprofiel van elk voorbeeld wordt bijgestuurd op basis van hoe consistent het is met eerdere schattingen. Door dit heen‑en‑weer proces een beperkt aantal keren te herhalen, bevordert het systeem betere ‘samenwerking’ tussen voorbeelden en labels, zodat zeldzame klassen duidelijkere signalen krijgen in plaats van overstemd te worden door veelvoorkomende klassen.
De temperatuur opvoeren waar dat nodig is
Een belangrijke innovatie in DCP‑AN is een adaptief “temperatuurveld” dat verandert hoe sterk de methode de betrouwbaarheden bijstelt, afhankelijk van hoe onzeker het lokaal en globaal lijkt. In plaats van één enkele temperatuurwaarde voor alle voorspellingen te gebruiken, berekent de methode aparte aanpassingssterktes voor klassen en voor voorbeelden, gebaseerd op maten van onzekerheid en mismatch in de tijd. Voor head‑klassen die het netwerk al met vertrouwen behandelt, koelt de effectieve temperatuur zachtjes af, waardoor over‑smoothing wordt voorkomen en scherpe onderscheidingen behouden blijven. Voor tail‑klassen en ambigüe voorbeelden stijgt de temperatuur, waardoor sterkere correcties mogelijk zijn die hun vertrouwen verhogen wanneer gerechtvaardigd en valse pieken dempen. Dit dynamische gedrag vloeit voort uit een principiële update‑regel en blijkt snel te reageren wanneer onzekerheid toeneemt, terwijl het stabiel blijft wanneer het model al goed uitgelijnd is.
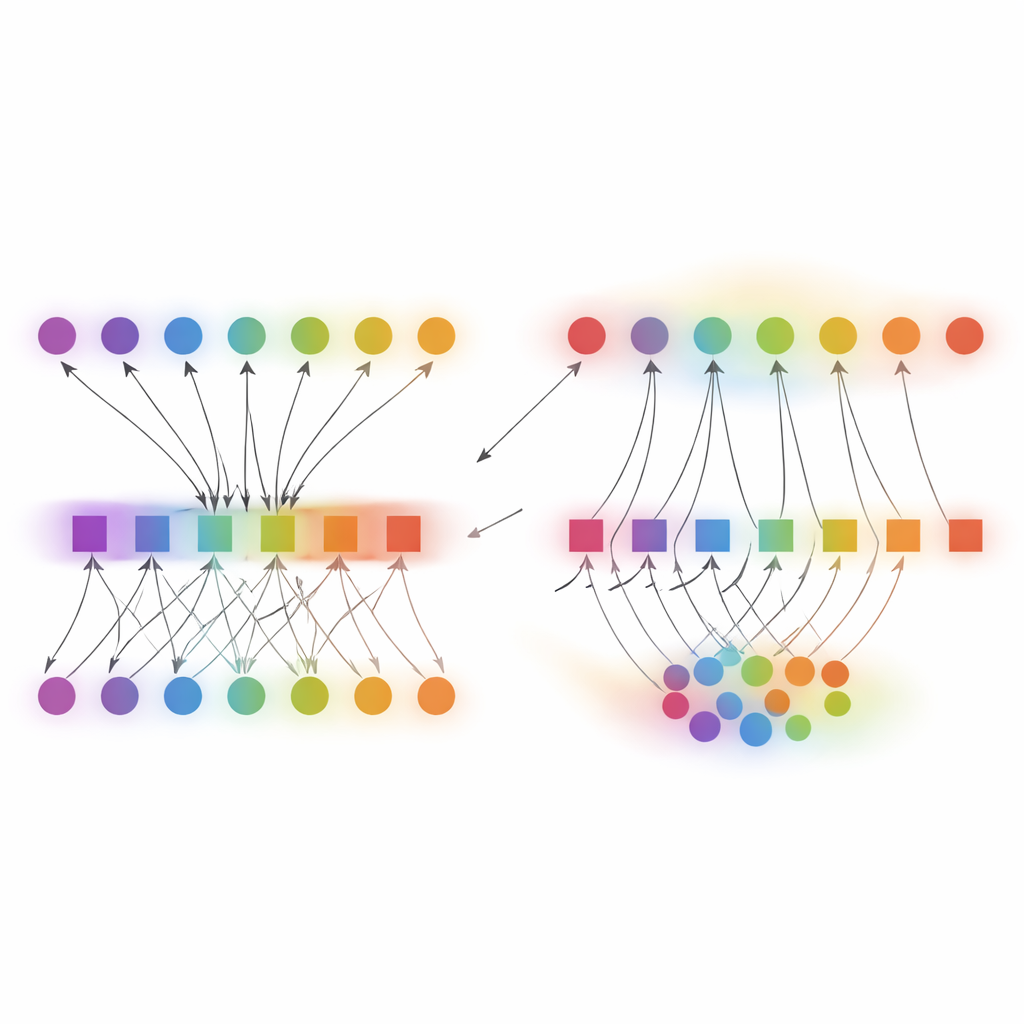
Betrouwbare verbetering over taken en hardware
De auteurs evalueren DCP‑AN zorgvuldig op meerdere veelgebruikte beelddatasets. Op een long‑tailed versie van ImageNet, waar sommige categorieën honderden malen meer beelden hebben dan andere, verhoogt de methode de nauwkeurigheid op zeldzame tail‑klassen met ongeveer 10 procentpunten absoluut en halveert het een standaard maat voor kalibratiefout vergeleken met een niet‑gecorrigeerde basislijn. In een cross‑domein test die een model van kunstwerken naar foto’s uit de echte wereld transferreert, verhoogt DCP‑AN zowel de nauwkeurigheid in het nieuwe domein als vermindert het een statistische maat voor de kloof tussen bron‑ en doeldata. Belangrijk is dat deze winst niet ten koste gaat van zware rekenbelasting: op een moderne grafische kaart voegt de methode iets meer dan één milliseconde vertraging en minder dan een halve megabyte extra geheugen toe, waardoor hij praktisch blijft voor real‑time toepassingen en edge‑apparaten.
Wat dit betekent voor alledaagse AI
Simpel gezegd laat dit werk zien dat we AI‑systemen niet alleen slimmer kunnen maken, maar ook zelfbewuster over wanneer ze het mis kunnen hebben. Door betrouwbaarheidsinformatie heen en weer te laten stromen tussen voorbeelden en categorieën, en door aan te passen hoe agressief het zichzelf corrigeert op basis van veranderende onzekerheid, levert DCP‑AN kansschattingen die beter overeenkomen met de realiteit — zelfs voor zeldzame gebeurtenissen en bij verschuivende omgevingen. Omdat het een wiskundige garantie biedt dat zijn iteratieve updates snel convergeren, en omdat het met minimale overhead draait, kan dit raamwerk in bestaande neurale netwerken worden geïntegreerd in domeinen zoals gezondheidszorg, robotica en beveiligingsmonitoring. Het resultaat is AI die nog steeds fouten maakt, maar veel eerlijker is over hoe zeker het is — een cruciale stap naar systemen waarop mensen veilig kunnen vertrouwen.
Bronvermelding: He, P., Fu, W., Wang, L. et al. Calibrating deep classifiers with dynamic confidence propagation and adaptive normalization. Sci Rep 16, 10959 (2026). https://doi.org/10.1038/s41598-026-39842-4
Trefwoorden: betrouwbaarheidskalibratie, diepe neurale netwerken, long‑tailed herkenning, onzekerheidsinschatting, domeinaanpassing