Clear Sky Science · nl
Een data-efficiënt 3D-medisch visie‑taalmodel met alleen een 2D-encoder
Slimmere ondersteuning door 3D-scans
Wanneer artsen CT- of MRI-scans beoordelen, kijken ze niet alleen naar losse beelden — ze zetten mentaal honderden plakjes aan elkaar om een probleem driedimensionaal te begrijpen. Computers hetzelfde leren doen kan zorgen voor snellere, consistentere diagnoses en duidelijkere rapporten voor patiënten. Huidige kunstmatige-intelligentiesystemen die 3D-scans verwerken, zijn echter uitermate "datahongerig"; ze vragen enorme, zorgvuldig gelabelde datasets die veel ziekenhuizen simpelweg niet hebben. Dit artikel introduceert een manier om 3D-niveau begrip te verkrijgen met bestaande 2D-beeldtechnologie, wat veelbelovende hulpmiddelen oplevert die eenvoudiger en goedkoper te bouwen en in te zetten zijn.
Waarom 3D-scans moeilijk zijn voor AI
Moderne visie‑taalsystemen kunnen al naar een 2D medisch beeld kijken en vragen beantwoorden of een rapport in gewone taal opstellen. Dat vermogen uitbreiden naar 3D-volumes zou AI in staat stellen om na te denken over hele organen en subtiele laesies die pas duidelijk worden wanneer veel plakjes samen worden bekeken. Het probleem is dat de meeste huidige 3D-systemen vertrouwen op speciale 3D-beeldencoders die vanaf nul getraind zijn op enorme verzamelingen gelabelde scans. Dergelijke datasets zijn zeldzaam, duur om te annoteren en vaak gebonden aan goed gefinancierde centra, wat beperkt wie er profijt van heeft. Tegelijkertijd betekent elke plak als afzonderlijk 2D‑beeld behandelen dat de natuurlijke continuïteit tussen plakjes verloren gaat en het model wordt overspoeld met herhalende informatie.
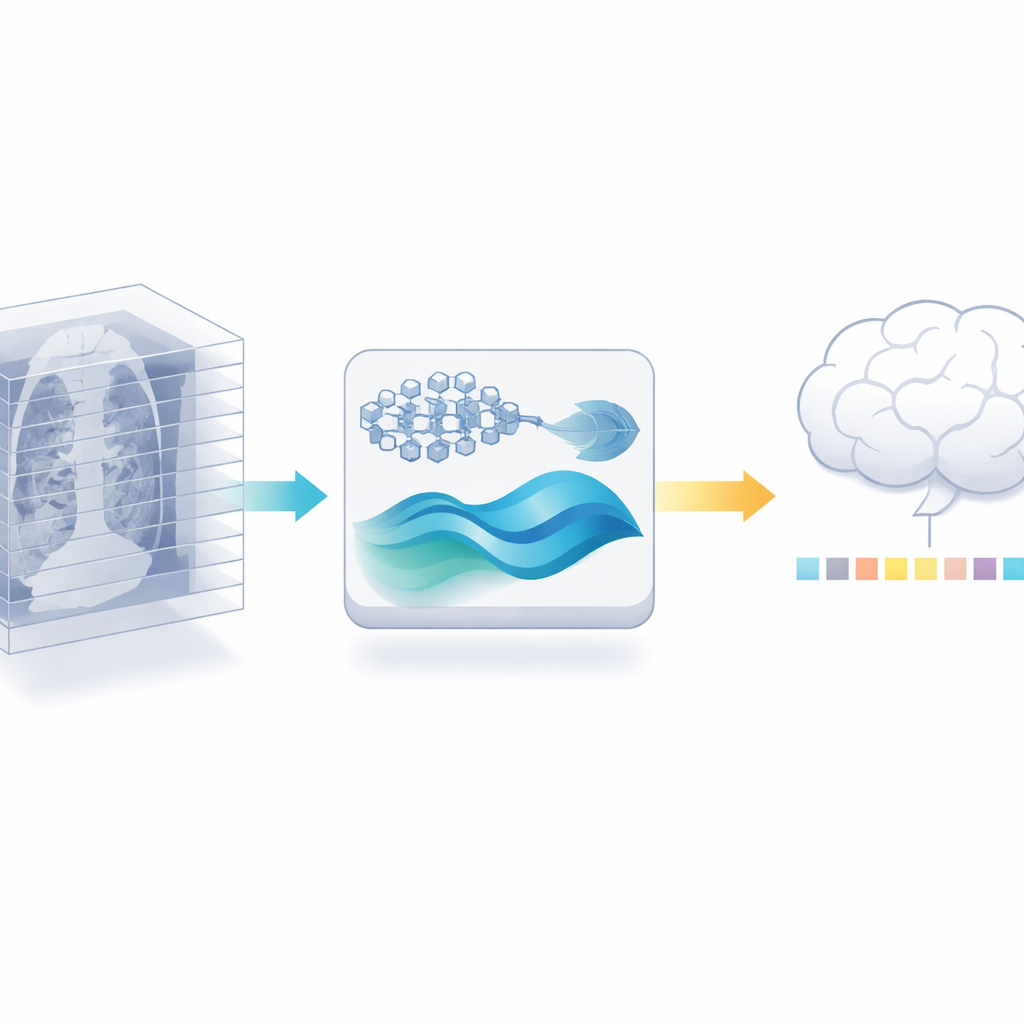
Een 2D-expert hergebruiken voor 3D‑werk
De auteurs stellen een ander pad voor: in plaats van een nieuwe 3D-encoder te trainen, hergebruiken ze een krachtig 2D-medisch beeldmodel dat al op miljoenen gelabelde beelden uit de medische literatuur is getraind. Ze snijden elke 3D-scan eerst in individuele plakjes en laten dit 2D-model gedetailleerde kenmerken uit elk plakje extraheren. Vervolgens knippen ze overtolligheid zorgvuldig weg: omdat aangrenzende plakjes in een scan vaak bijna hetzelfde lijken, kan een gelijkeniscontrole veel bijna-duplicaten wegfilteren en toch de meest informatieve beelden behouden. Alleen deze stap vermindert al de hoeveelheid data die de latere stadia moeten verwerken, zonder meer gelabelde scans te vragen.
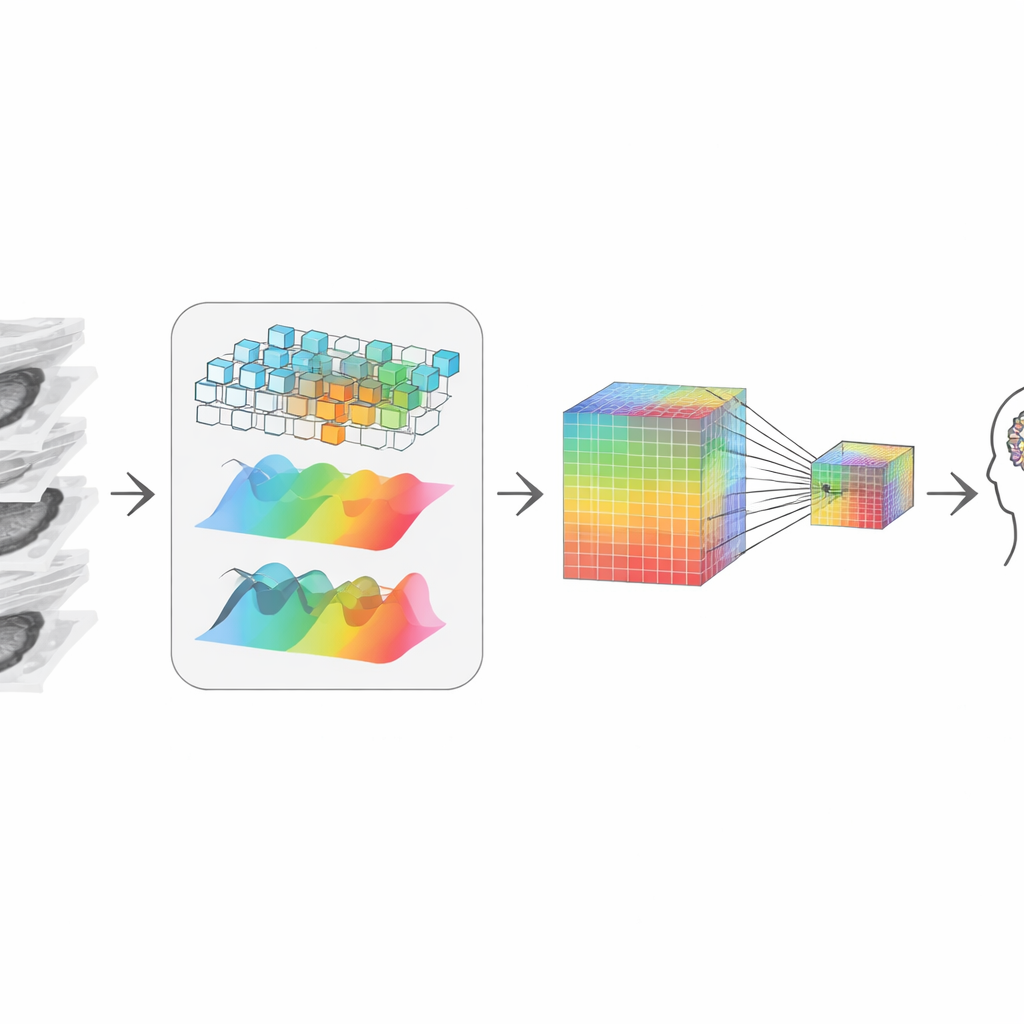
Het 3D-verhaal uit stukjes herbouwen
Na het trimmen moet het systeem de overgebleven plakjes weer tot een samenhangend 3D‑beeld "hersteken". De auteurs doen dit door twee complementaire gezichtspunten van de data te combineren. Het ene pad kijkt naar lokale vormen en randen, als een vergrootglas dat door het volume beweegt, gevoelig voor scherpe grenzen en texturen. Het andere pad transformeert de data naar een frequentieweergave, die beter is in het vastleggen van brede patronen en lang‑afstandstructuur door plakjes heen — hoe een tumor zich uitstrekt of hoe een orgaan in zijn geheel is gevormd. Een adaptieve fusiestap leert hoeveel vertrouwen aan elk gezichtspunt op elk punt moet worden gegeven, wat resulteert in een representatie die zowel fijne details als globale context respecteert, ook al begon het met 2D‑plakjes.
Kleine aanwijzingen bewaren tijdens compressie
Om te communiceren met een groot taalmodel — het deel dat vragen beantwoordt en rapporten schrijft — moet de visuele informatie worden gecomprimeerd tot een bescheiden aantal tokens, of "visuele woorden." Simpele verkleining zou kleine maar kritische signalen vervagen, zoals kleine calcificaties of subtiele textuurveranderingen die bij de diagnose van belang zijn. Om dit te vermijden creëren de auteurs een tweesporige representatie: de ene houdt een hoge-resolutieversie rijk aan detail, de andere is een kleinere, goedkopere versie. Een attentiemechanisme laat elk punt in de kleinere versie selectief "terugkijken" naar de grotere versie en de scherpste beschikbare details binnenhalen. Het resultaat is een compacte visuele samenvatting die toch de aanwijzingen draagt die een radioloog belangrijk zou vinden, en die vervolgens aan het taalmodel voor redenering wordt gegeven.
Bewijs op echte medische taken
Om hun ontwerp te testen, evalueerden de onderzoekers het op openbare 3D-benchmarks die twee hoofdvragen stellen: kan het systeem nauwkeurige radiologieachtige beschrijvingen van 3D-scans schrijven, en kan het vragen beantwoorden over wat zichtbaar is? Hun aanpak, ondanks het ontbreken van training van een 3D‑specifieke encoder, presteerde beter dan verschillende sterke 3D-gebaseerde modellen op beide taken. Het produceerde meer precieze, klinisch rijke rapporten en beantwoordde vragen accurater, ook moeilijke vragen over het exacte orgaan, de afwijking of de betrokken locatie. Het liep ook sneller, vereiste veel minder 3D-trainingsdata en generaliseerde goed naar verschillende scantypes zoals MRI en PET.
Wat dit betekent voor toekomstige zorg
In eenvoudige bewoordingen laat dit werk zien dat we niet vanaf nul hoeven te beginnen met datahongerige 3D-modellen om hoogwaardige AI‑ondersteuning bij volumetrische scans te krijgen. Door slim een sterke 2D‑expert te hergebruiken, informatieve plakjes zorgvuldig te selecteren en het 3D‑beeld te herbouwen terwijl kleine details behouden blijven, bereiken de auteurs state‑of‑the‑art prestaties met veel minder data en rekenkracht. Als dit breed wordt toegepast, kan dit soort aanpak geavanceerde AI‑ondersteuning — zoals betere rapporten, helderdere uitleg en betrouwbaardere triage — binnen bereik brengen van ziekenhuizen en klinieken die niet over enorme datareserves beschikken, en zo geavanceerde beeldanalyse dichter bij de routinematige klinische praktijk brengen.
Bronvermelding: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
Trefwoorden: 3D medische beeldvorming, visie‑taalmodellen, radiologie AI, data-efficiënt leren, CT- en MRI-analyse