Clear Sky Science · nl
Gemodificeerde ShuffleNet getraind op gradiëntpatroon- en vormgebaseerde kenmerken voor longkankerclassificatie met verbeterde M-SegNet-segmentatie
Waarom vroege longcontroles belangrijk zijn
Longkanker behoort tot de dodelijkste vormen van kanker wereldwijd, grotendeels omdat het vaak te laat wordt ontdekt. Artsen gebruiken al CT-scans om verdachte plekjes in de longen op te sporen, maar het zorgvuldig bekijken van honderden beelden per patiënt is langzaam en vermoeiend werk. Dit artikel beschrijft een computersysteem dat leert deze scans automatisch te lezen, met als doel artsen te helpen kanker eerder, consistenter en in ziekenhuizen zonder grote teams van specialisten te detecteren.
Een slimme hulp bij het lezen van longscans
De auteurs bouwen een geautomatiseerde pijplijn die rauwe CT‑beelden van de borstkas ingaat en deze stapsgewijs verfijnt tot een eenvoudige uitkomst: waarschijnlijk kanker of niet. Eerst verbetert het systeem het contrast van elk beeld zodat details in het longweefsel beter zichtbaar worden. Vervolgens scheidt het nauwkeurig de longen van de rest van de borstkas, waardoor de analyse zich richt op de gebieden waar tumoren daadwerkelijk groeien. Uit deze opgeschoonde longbeelden worden kenmerkende patronen in textuur en vorm geëxtraheerd, en tenslotte wordt deze informatie gevoed aan een compact deep‑learningmodel dat de uiteindelijke beslissing neemt. Het algemene doel is niet om artsen te vervangen, maar hen een snelle en betrouwbare second opinion te bieden.
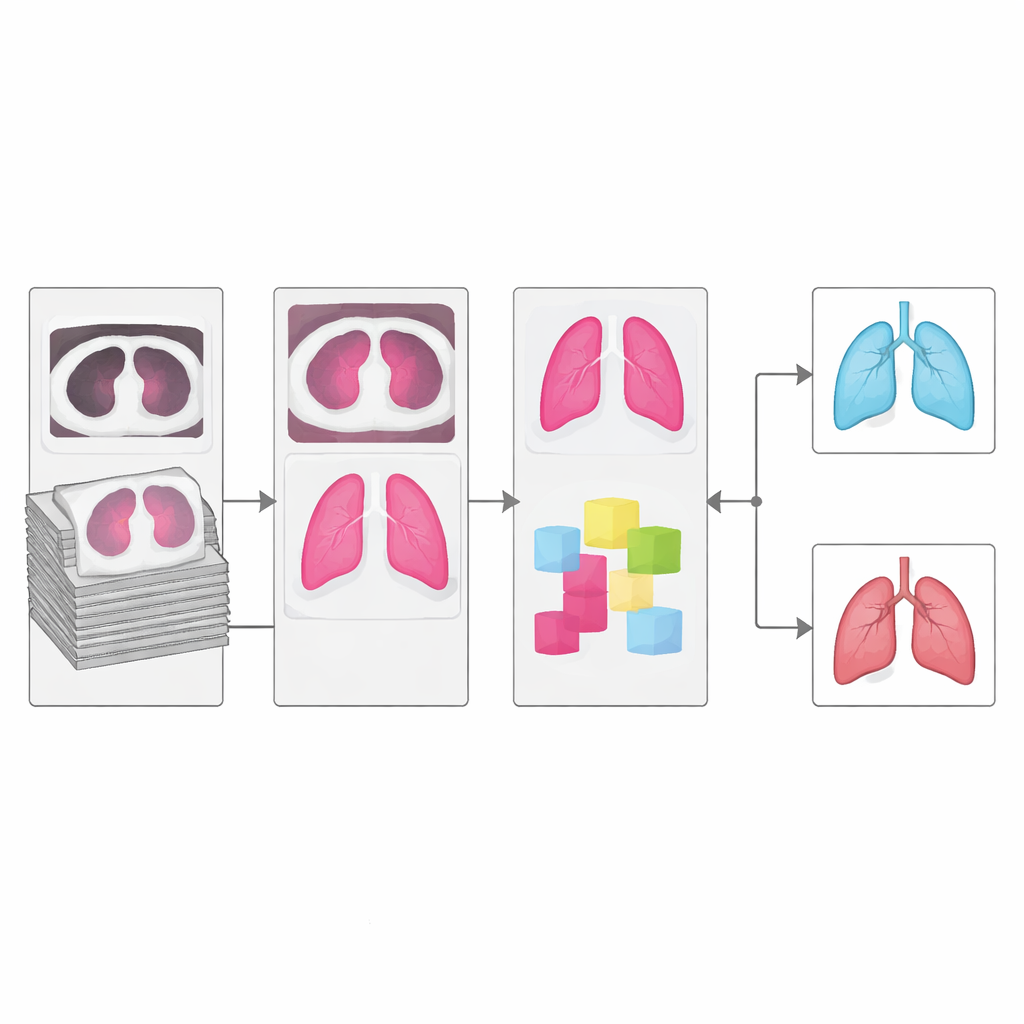
Het systeem leren de longstructuur te zien
Een van de grootste hindernissen bij computeraanalyse van CT‑scans is segmentatie: het afbakenen van de werkelijke longgebieden, en vooral de grenzen van de lobben waar kleine knobbeltjes zich kunnen verbergen. De auteurs introduceren een verbeterd segmentatienetwerk genaamd mRRB‑SegNet, dat ideeën uit moderne beeldherkenning combineert, waaronder shortcut‑verbindingen en recurrente lussen die het model in staat stellen zowel naar lokale details als naar bredere context te kijken. In tests tegenover gangbare alternatieven produceerde deze segmenter omtrekken die veel dichter aansloten bij door experts gedefinieerde longgebieden, wat cruciaal is omdat elke fout in dit stadium door kan werken naar alle volgende stappen.
Subtiele textuur- en vormsignalementen lezen
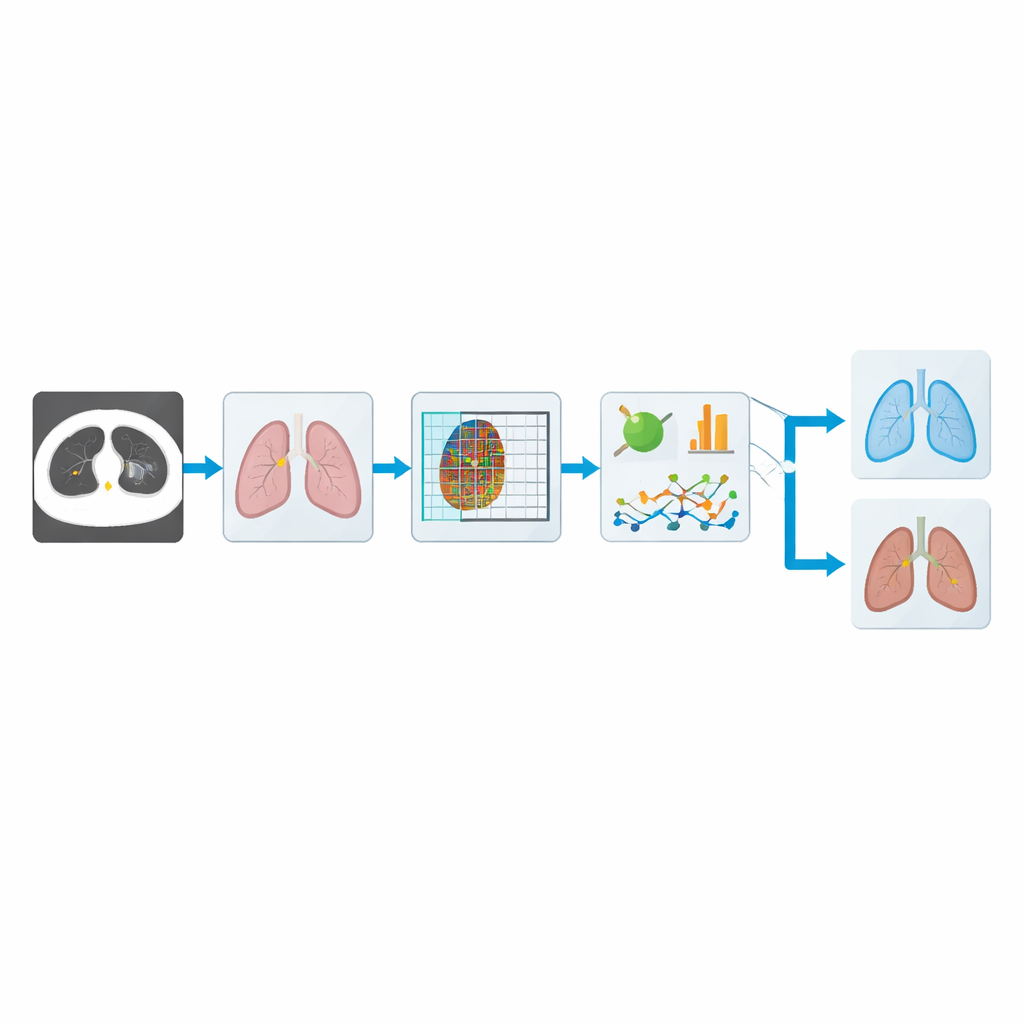
Zodra de longen geïsoleerd zijn, richt het systeem zich op het herkennen van een kwaadaardig knobbeltje. In plaats van alleen op ruwe pixels te vertrouwen, berekent het meerdere groepen kenmerken. Een verfijnde “lokale gradiënt”-maat richt zich op kleine helderheidsveranderingen tussen aangrenzende pixels, die overeenkomen met fijne texturen in het weefsel. Aanvullende vormmaten vangen hoe groot, compact of onregelmatig een knobbeltje is, en statistische samenvattingen beschrijven hoe intensiteiten binnen elk gebied verdeeld zijn. Samen helpen deze aanwijzingen om onschuldige ronde plekjes te onderscheiden van meer getande, verdachte gezwellen die typisch zijn voor kwaadaardige tumoren.
Een lichtgewicht brein voor snelle beslissingen
Om deze kenmerken om te zetten in beslissingen passen de auteurs een deep‑learningarchitectuur aan genaamd ShuffleNet, oorspronkelijk ontworpen om snel op mobiele apparaten te draaien. Ze voegen een aangepaste normalisatiestap toe die de training op rumoerige medische data stabiliseert, en een attentiemodule die leert harder te "kijken" naar de belangrijkste kanalen en locaties in het beeld. Deze verbeterde CMN‑ShuffleNet houdt het netwerk klein en efficiënt, maar leert toch te focussen op de longpatronen die het meest relevant zijn voor kanker. Omdat het relatief bescheiden rekenkracht gebruikt, is het systeem beter geschikt voor de praktijk in klinieken, ook voor instellingen met beperkte hardwarebronnen.
Hoe goed werkt het in de praktijk?
Het team testte hun aanpak op twee veelgebruikte openbare datasets van long‑CT‑scans. Op de hoofdset (LUNA16) onderscheidde hun model kanker van niet‑kankergevallen correct in ongeveer 96% van de gevallen, met bijzonder sterke scores voor sensitiviteit—het vermogen echte kankergevallen te vangen—en voor een gebalanceerde metriek die alle fouttypes weegt. Het presteerde ook duidelijk beter dan een reeks gevestigde deep‑learningmodellen, waaronder versies van VGG, DenseNet en andere recurrente en convolutionele netwerken, ondanks dat het minder rekentijd gebruikte dan veel van die modellen. Een aparte cross‑validatietest op een onafhankelijke dataset toonde vergelijkbaar hoge prestaties, wat suggereert dat de methode niet alleen een enkele verzameling scans uit het hoofd leert.
Wat dit betekent voor patiënten en klinieken
Voor een niet‑specialistische lezer is de kernboodschap dat de auteurs een snel, compact kunstmatig‑intelligentiesysteem hebben ontwikkeld dat subtiele tekenen van longkanker op CT‑scans kan oppikken met een nauwkeurigheid vergelijkbaar met, en in sommige gevallen beter dan, grotere en tragere systemen. Door zorgvuldige beeldopschoning, precieze longafbakening en gerichte analyse van textuur en vorm te combineren, vermindert de methode gemiste kankergevallen terwijl valse alarmen relatief laag blijven. Hoewel het nog steeds afhankelijk is van scans van goede kwaliteit en verstoord kan raken als de eerdere segmentatiestap faalt, brengt dit werk geautomatiseerde longkankerscreening dichter bij routinematig klinisch gebruik, waar het artsen kan helpen ziekte eerder te detecteren en de uitkomsten voor veel patiënten te verbeteren.
Bronvermelding: R, N., C M, V. Modified ShuffleNet trained on gradient pattern and shape-based features for lung cancer classification with improved M-SegNet segmentation. Sci Rep 16, 11185 (2026). https://doi.org/10.1038/s41598-026-39492-6
Trefwoorden: longkanker, CT‑beeldvorming, deep learning, medische AI, computerondersteunde diagnose