Clear Sky Science · nl
Biometrische differentiatie van eeneiige tweelingen op basis van gelaatsmerken met dynamische functieverbetering
Waarom kleine huiddetails ertoe doen
De meesten van ons gaan ervan uit dat eeneiige tweelingen, wel, identiek zijn—zo gelijk dat zelfs geavanceerde camera’s en DNA-tests moeite hebben om ze uit elkaar te houden. Die gelijkenis veroorzaakt serieuze problemen in de praktijk, van het oplossen van misdrijven tot grensbeveiliging. Deze studie laat zien dat de oplossing misschien te vinden is in iets wat we zelden opmerken: de kleine, stabiele vlekjes en imperfecties verspreid over onze gezichten. Door deze moedervlekken, vlekken en poriën te behandelen als een soort "huidkaart", bouwden de onderzoekers een geautomatiseerd systeem dat eeneiige tweelingen betrouwbaar van elkaar kan onderscheiden, wat wijst op preciezere en beter uitlegbare biometrische hulpmiddelen.
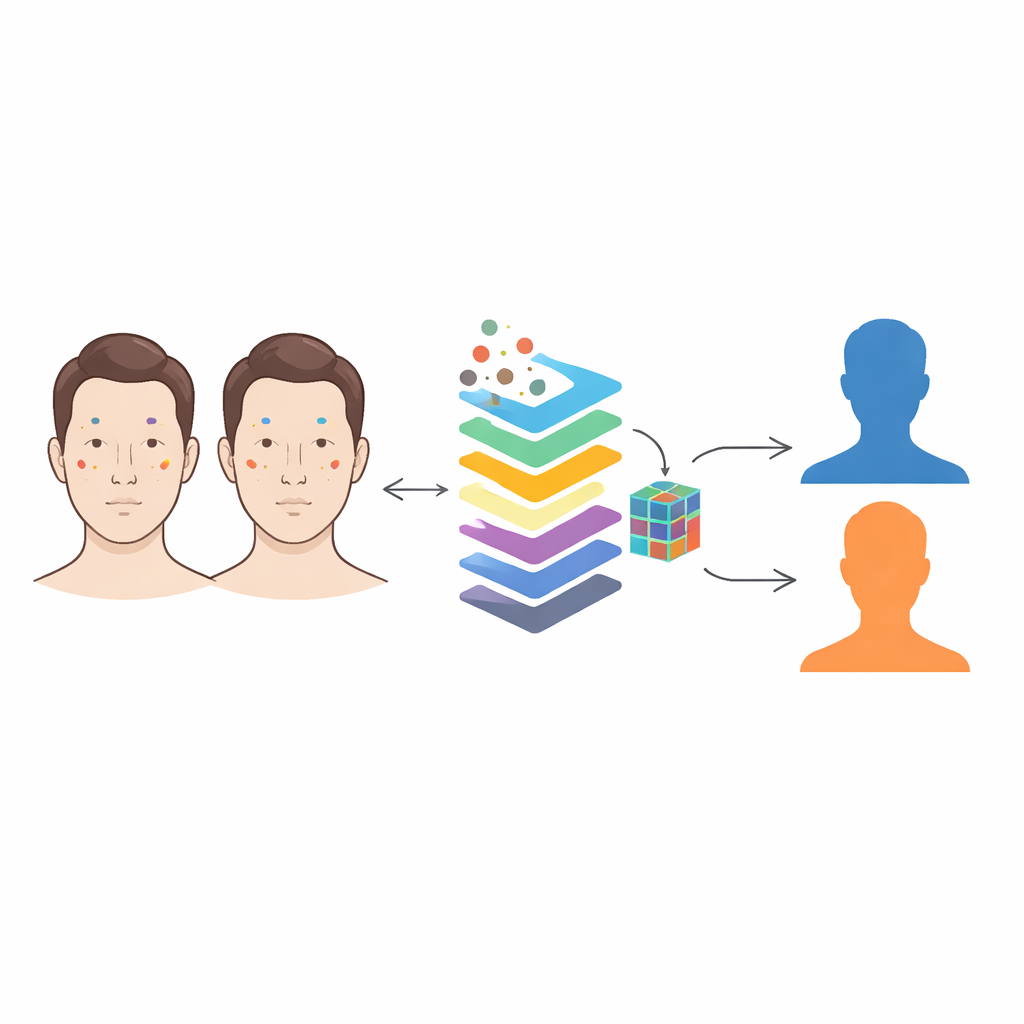
Van verwarrende gezichten naar heldere huidkaarten
Traditionele gezichtsherkenningssystemen richten zich op de algemene gezichtstructuur—de afstand tussen de ogen, de vorm van de neus, de kaaklijn. Bij eeneiige tweelingen zijn deze kenmerken bijna identieke kopieën, wat verklaart waarom zelfs geavanceerde algoritmen en DNA-analyse vaak niet kunnen bepalen welke tweeling het betreft. De auteurs concentreren zich in plaats daarvan op de kleine, grotendeels permanente details van de huid: littekens van acne, donkere vlekken, poriën en rimpels. Deze merktekens vormen doorgaans unieke patronen in iemands leven, zelfs bij mensen die vrijwel al hun genen delen. Het kernidee is eenvoudig maar krachtig: terwijl tweelinggezichten op het eerste gezicht hetzelfde kunnen lijken, doen hun constellaties van huidmerken dat niet.
Hoe het systeem ziet wat wij missen
Het team werkte met 319 gezichtsfoto’s van 74 paar tweelingen uit een bekende onderzoeksverzameling. Eerst gebruikten ze een voorgetraind computer vision-model om elk gezicht te scannen en verschillende typen huidkenmerken te detecteren—zoals acne, donkere kringen of poriën—en daarbij onzichtbare kaders rond elk kenmerk te tekenen. Belangrijk is dat ze de detector zeer gevoelig instelden, bereid om zelfs zwakke merktekens op te pikken ten koste van het meevangen van enige ruis. In plaats van elke detectie op zich te vertrouwen, vatten ze alle merktekens samen in een rijk profiel voor iedere persoon: hoeveel merktekens van elk type verschijnen, hoe dicht ze clusteren, hoe ze over het gezicht verspreid zijn en hoe groot ze gemiddeld zijn.
Huidpatronen omzetten in tweelingbeslissingen
Vervolgens vergeleken de onderzoekers deze huidprofielen tussen paar beelden—soms echte tweelingen, soms niet-verwante personen—om te meten hoe gelijk of verschillend ze waren. Ze combineerden verschillende intuïtieve vergelijkingsstappen: hoe goed de samenstelling van type merktekens overeenkomt, hoe vergelijkbaar de gemiddelde grootte van merktekens is, hoe gelijk merktekens verdeeld zijn tussen links en rechts of boven en onder van het gezicht, en hoe de merktekens ruimtelijk gerangschikt zijn, inclusief hun afstand tot het midden van het gezicht en hun clustervorm. Deze gelijkenheidsscores werden vervolgens gevoed aan een machine learning-model dat leerde een ja–nee-vraag te beantwoorden: behoren deze twee gezichten tot hetzelfde tweelingpaar of niet?
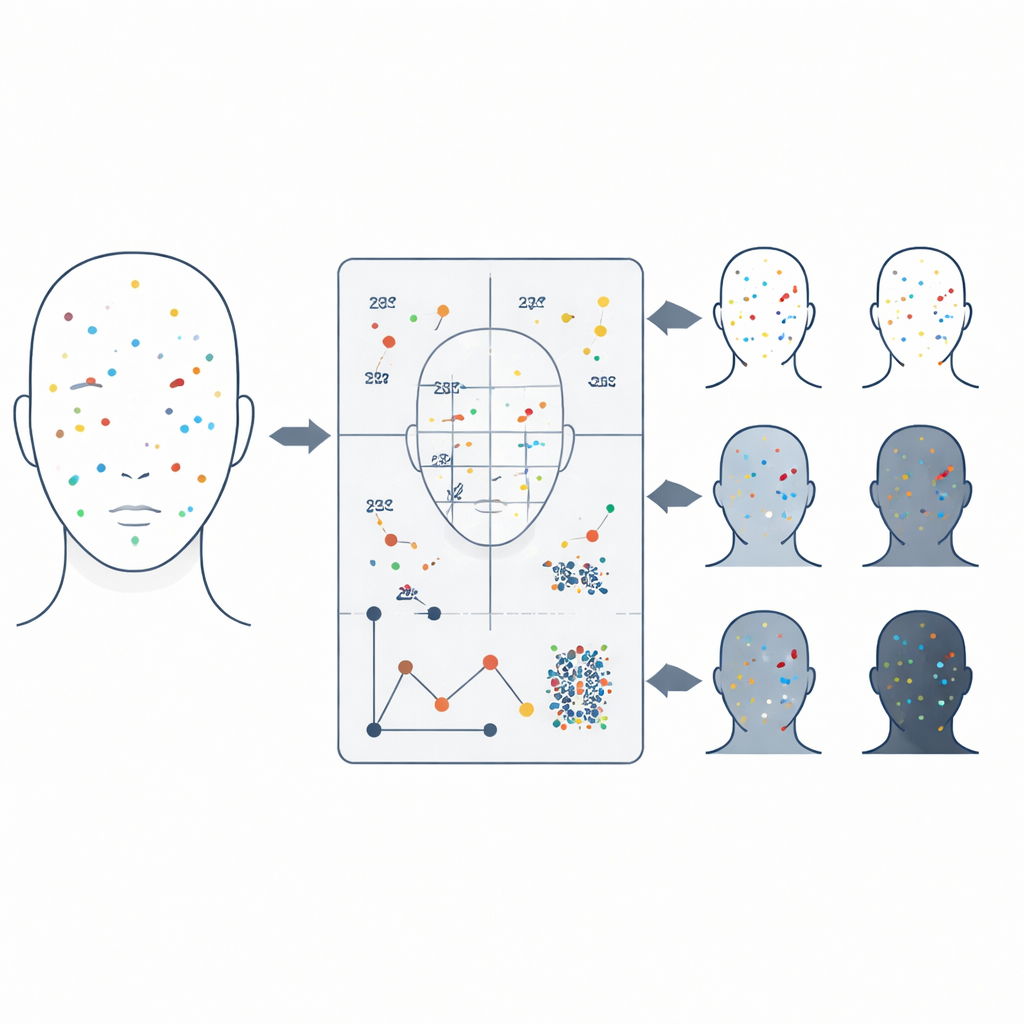
Slim afstemmen zonder tijd te verspillen
Het bouwen van zo’n classifier gaat niet alleen over welke informatie je erin stopt, maar ook over hoe je de vele interne "knoppen" afstelt, zoals hoe complex het model mag worden. De studie vergeleek systematisch vier verschillende strategieën om de beste instellingen te zoeken, variërend van een uitputtend raster van mogelijkheden tot meer verkennende methoden geïnspireerd door willekeurige sampling en zwermgedrag in de natuur. Terwijl een zwerm-gebaseerde methode in de tests net iets beter scoorde op ruwe nauwkeurigheid, leverde een eenvoudigere willekeurige zoekmethode vrijwel dezelfde prestaties in een fractie van de tijd. Deze balans is van praktisch belang: een systeem dat zowel nauwkeurig als efficiënt is, heeft veel meer kans op werkelijke toepassing in politielaboratoria, grensposten of medisch onderzoek.
Wat de huid zegt over identiteit
Al met al bereikte het raamwerk ongeveer 96,6% nauwkeurigheid in kruisvalidatie en een sterke score in tests die meten hoe goed het tweelingen van niet-tweelingen scheidt, met minimale tekenen van overfitting. Het meest doorslaggevende signaal was niet welke typen merktekens mensen hadden, maar waar die merktekens op het gezicht verschenen—het ruimtelijke patroon fungeerde als een unieke handtekening. Aantallen per type merkteken, verschillen tussen gezichtsregio’s en subtiele clustergedragingen voegden extra betrouwbaarheid toe. Belangrijk is dat de beslissingen van het systeem gevisualiseerd en verklaarbaar zijn, waardoor onderzoekers kunnen zien welke aspecten van de huidkaart een match of non-match veroorzaakten. Voor niet-specialisten is de boodschap opvallend: zelfs bij de meest gelijkende mensen die we kennen, legt de huid stilletjes genoeg individuele details vast zodat machines ze van elkaar kunnen onderscheiden, wat de deur opent naar eerlijkere rechtszaken, veiligere biometrie en nieuwe manieren om te bestuderen hoe onze omgeving ons uiterlijk in de loop van de tijd vormgeeft.
Bronvermelding: Brahmbhatt, K.J., Prakasha, K. & Sanil, G. Facial mark based biometric differentiation of identical twins using dynamic feature enhancement. Sci Rep 16, 9249 (2026). https://doi.org/10.1038/s41598-026-39470-y
Trefwoorden: eeneiige tweelingen, gezichtsbiometrie, huidmerken, forensische identificatie, machine learning