Clear Sky Science · nl
Gen-gedreven analytisch leermodel voor nauwkeurige borstkankerdetectie
Waarom dit onderzoek belangrijk is voor patiënten en families
Borstkanker is nu wereldwijd de meest gediagnosticeerde vorm van kanker bij vrouwen, en patiënten die op papier hetzelfde ziektebeeld lijken te hebben, kunnen heel verschillende uitkomsten kennen. Deze studie laat zien hoe patronen in duizenden genen, gecombineerd met een zorgvuldig ontworpen systeem voor kunstmatige intelligentie, artsen kunnen helpen betrouwbaarder vast te stellen wie kanker heeft en hoe ernstig die kan zijn—gebaseerd op echte patiëntgegevens en een compacte set sleutelgenen.
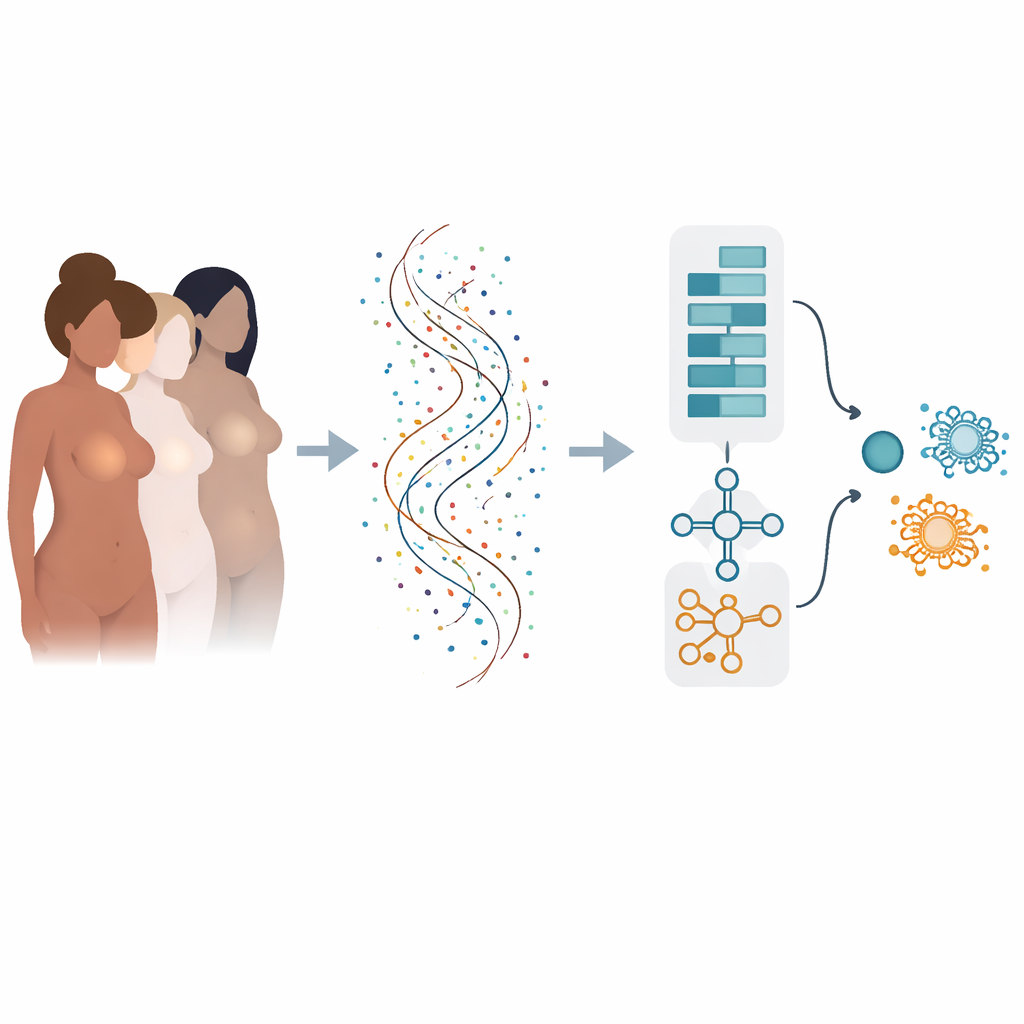
Van veel risicofactoren naar de taal van genen
Het risico op borstkanker wordt door veel factoren bepaald: erfelijke genetische veranderingen, hormonen, lichaamsgewicht, leefstijl en meer. Zodra kanker ontstaat, wordt het gedrag ervan bepaald door welke genen in ieder tumor zijn aan- of uitgeschakeld. Moderne sequencing kan de activiteit van tienduizenden genen tegelijk meten, maar van deze oceaan aan getallen heldere ja/nee-antwoorden voor diagnose en prognose maken is moeilijk. Traditionele computermethoden bekijken genen vaak één voor één en kunnen daarmee missen hoe groepen genen samen werken, of ze presteren goed op één dataset maar falen wanneer ze op een andere worden getest.
Een model met twee ‘hersendelen’ leren genpatronen te lezen
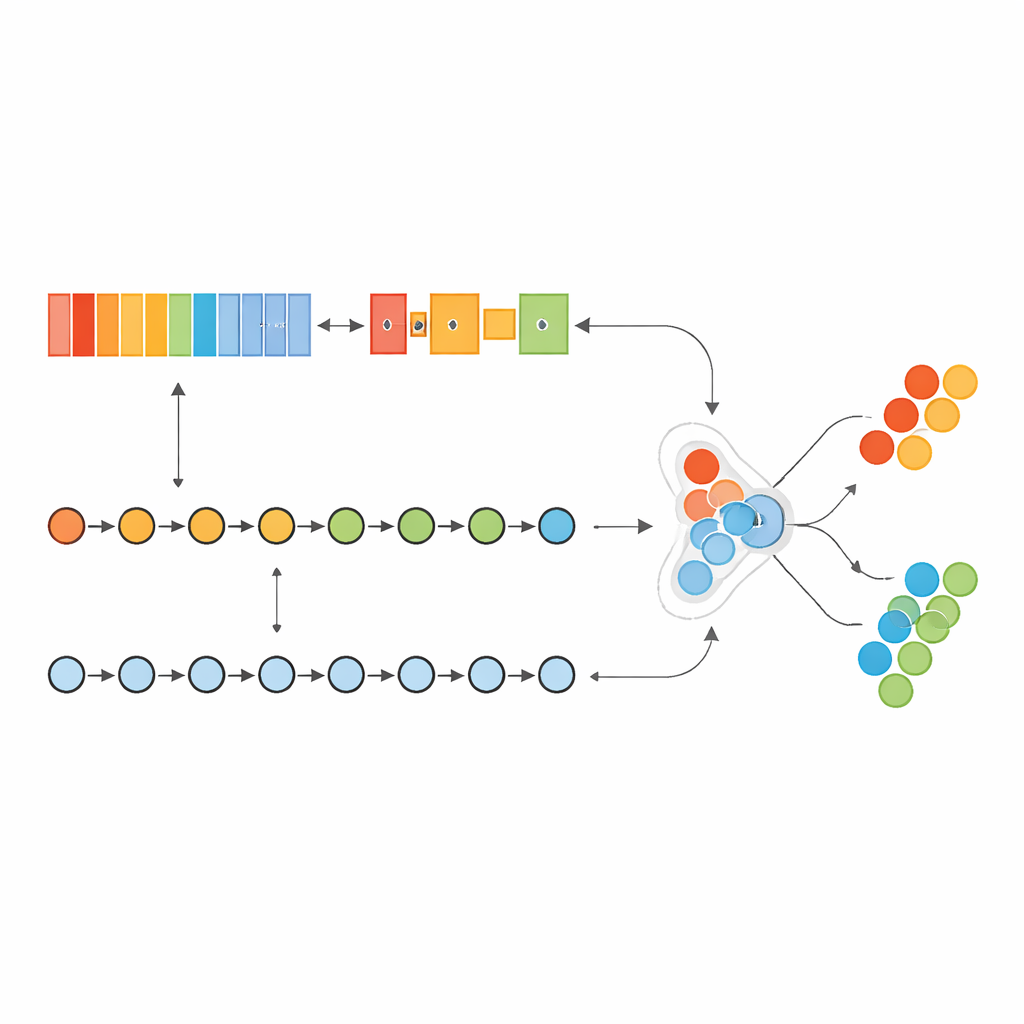
De auteurs bouwden een “hybride” deep learning-model dat een beetje werkt als twee gespecialiseerde hersendelen die samenwerken. Het ene deel, geïnspireerd op beeldanalyse, scant een geordende lijst van genen om lokale patronen te detecteren—clusters van genen waarvan de gezamenlijke activiteit op kanker wijst. Het andere deel behandelt dezelfde genen als een sequentie en leert hoe vroege “driver”-genen en latere “downstream”-genen elkaar beïnvloeden over de lijst heen. Door deze twee gezichtspunten te combineren, kan het model zowel kortetermijn- als langetermijnrelaties binnen het genetische vingerafdruk van de tumor vastleggen.
Het vinden van een stabiele kernset signaalgenen
In plaats van alle 17.815 gemeten genen in het model te stoppen, ontwierp het team een strikte, “leakage-vrije” pijplijn om alleen de meest informatieve eruit te selecteren. Met een standaard maat voor correlatie binnen herhaalde kruiscontrole-lussen rangschikten ze genen herhaaldelijk op hoe sterk hun activiteit samenhing met de kankertoestand. Ze behielden vervolgens alleen de genen die consequent bovenaan kwamen in alle trainingssplits, wat resulteerde in een stabiele signatuur van 236 genen. De onderzoekers brachten ook in kaart hoe deze genen met elkaar interacteren en toonden aan dat velen nauw verbonden netwerken vormen die gerelateerd zijn aan tumorgroei, metabolisme, immuunsysteem en de omliggende weefselomgeving—bewijs dat de gekozen set echte biologische signalen weerspiegelt, geen willekeurige ruis.
Het model op de proef stellen
Het hybride systeem werd getraind en afgestemd op borstkankermonsters uit The Cancer Genome Atlas en vervolgens getest op een volledig aparte dataset bekend als METABRIC. Om om te gaan met het feit dat kankermonsters veel talrijker zijn dan normale monsters, creëerden de auteurs geen kunstmatige data; in plaats daarvan pasten ze aan hoeveel het model zich iets aantrok van fouten op de zeldzamere klasse. Na een geautomatiseerde zoektocht naar de beste instellingen behaalde het model bijna perfecte scores op de hoofddataset, waarbij het vrijwel alle kankergevallen correct markeerde en bijna geen valse alarmen gaf. Belangrijk is dat de prestaties extreem hoog en zeer stabiel bleven toen het model op de externe METABRIC-cohort werd toegepast, wat suggereert dat de aanpak kan generaliseren buiten één studie of ziekenhuis.
Wat dit betekent voor toekomstige zorg
In eenvoudige bewoordingen levert dit werk een fijn afgestemde, tweedelige AI op die een compacte 236-genen-code leest om met opmerkelijke nauwkeurigheid en consistentie kankervrije van kankerrijke borstmonsters te onderscheiden, zelfs onder rumoerige omstandigheden. Hoewel de huidige studie alleen naar genactiviteit kijkt en historische patiëntgegevens gebruikt, vormen de methoden de basis voor toekomstige hulpmiddelen die meerdere soorten gegevens kunnen combineren—zoals weefselbeelden en extra moleculaire lagen—en duidelijke uitleg kunnen geven over welke genen elke voorspelling aandrijven. Met verdere validatie in prospectieve klinische studies zou zo’n systeem een universele ruggengraat kunnen worden voor precisiebepaling bij borstkankerdetectie, waardoor artsen behandelingen beter kunnen afstemmen op de genetische “handtekening” van ieders tumor.
Bronvermelding: Hesham, F., Abbassy, M.M. & Abdalla, M. Gene driven analytical learning model for accurate breast cancer diagnosis. Sci Rep 16, 8155 (2026). https://doi.org/10.1038/s41598-026-39430-6
Trefwoorden: borstkankerdetectie, genexpressie, deep learning, CNN-BiLSTM, precisiegeneeskunde