Clear Sky Science · nl
Vergelijkende prestatietest van quantum feature maps voor machine learning op basis van quantum-kernels
Waarom dit buiten het laboratorium van belang is
Naarmate onze data en problemen complexer worden, hebben zelfs de beste huidige machine-learningmethoden moeite om heldere patronen te vinden. Quantumcomputers beloven nieuwe manieren om zulke problemen aan te pakken, maar het is nog onduidelijk wanneer en hoe ze daadwerkelijk voordeel bieden. Dit artikel onderzoekt een praktisch deel van die puzzel: hoe quantum-gebaseerde classifiers ontworpen en afgestemd moeten worden zodat ze kunnen concurreren met, en soms rivaliseren met, gevestigde klassieke methoden op zowel eenvoudige voorbeelden als een echte medische dataset.
Van gelijkenis naar quantumkracht
Veel succesvolle leermethoden, zoals support vector machines, vertrouwen op “kernels” die meten hoe vergelijkbaar twee gegevenspunten zijn nadat ze op een onzichtbare manier zijn getransformeerd naar een rijkere featurespace. Quantumcomputers kunnen zulke transformaties op natuurlijke wijze uitvoeren door data in quantumtoestanden te coderen en vervolgens te vergelijken hoeveel twee toestanden overlappen. De auteurs richten zich op deze quantumkernels en op de “feature maps” die een quantumcircuit vertellen hoe gewone getallen in quantumtoestanden worden omgezet. Een goede feature map maakt verwarde data makkelijker te scheiden; een slechte verspilt de quantumhardware. Het werk stelt twee kernvragen: welke feature maps werken het beste, en hoeveel kan zorgvuldige afstemming ze verbeteren?
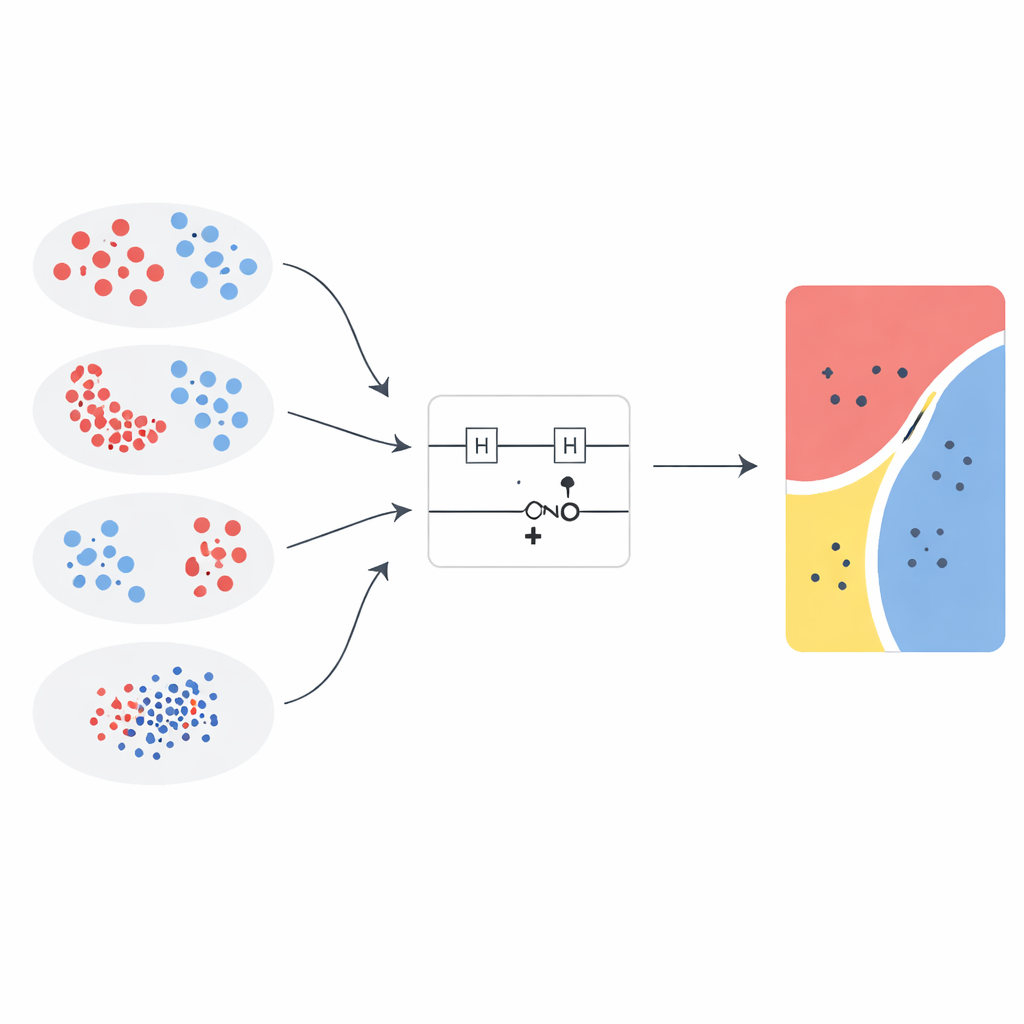
Verschillende quantumrecepten getest
De onderzoekers introduceren een nieuwe feature map van hogere orde en vergelijken deze met vijf state-of-the-art ontwerpen uit eerder werk. Elke map gebruikt een eenvoudige twee-qubitcircuit dat single-qubitrotaties en een verstrengelingspoort toepast, maar de wiskundige formules die die rotaties aansturen verschillen. Om de studie scherp te houden, worden de structuur van het quantumcircuit, de instellingen van de support vector machine en de evaluatieprocedure constant gehouden, terwijl alleen de feature map en de interne “rotatiesterkte” variëren. Hierdoor is het mogelijk om prestatieverbeteringen rechtstreeks toe te schrijven aan de manier waarop data in quantumtoestanden worden gecodeerd, in plaats van aan extra bijsturing van het klassieke leeralgoritme daaromheen.
Van eenvoudige patronen tot kankerdiagnose
Het team evalueert de quantumkernels op drie klassieke tweedimensionale testproblemen—concentrische cirkels, sikkelvormige manen en een XOR-patroon—en op een gereduceerde versie van de Wisconsin Breast Cancer Diagnostic-dataset. Voor de medische gegevens worden twee van de meest informatieve beeldgebaseerde kenmerken geselecteerd met een standaard feature-selectiemethode. Alle invoerwaarden worden vervolgens naar hetzelfde bereik geschaald en in ondiepe twee-qubitcirkels gevoerd, waardoor de experimenten realistisch blijven voor de huidige noisy intermediate-scale quantum-apparaten. De prestaties worden vergeleken met een breed scala aan klassieke modellen, waaronder lineaire en radial-basis-functie support vector machines, decision trees, random forests, boosting, naïeve Bayes, lineaire discriminantanalyse en multilayer perceptrons, waarbij zowel nauwkeurigheid als de Matthews correlatiecoëfficiënt worden gebruikt om zowel correctheid als klassenbalans vast te leggen.
Wat de vergelijkingen aantonen
Op de eenvoudigere benchmarkdatasets behalen de verbeterde quantumkernels—vooral die gebouwd met de nieuwe feature map en twee van de bestaande—bijna perfecte classificatie, waarmee ze de meeste klassieke concurrenten evenaren of overtreffen. Op de zwaardere borstkankerdata blijven de beste quantum feature maps concurrerend met sterke klassieke baselines zoals radial-basis-functiekernels en neurale netwerken. Een belangrijke draaiknop is de rotatiefactor, die schaalt hoe sterk invoerwaarden de quantumrotaties beïnvloeden. Door deze factor over meerdere waarden te variëren, laten de auteurs zien dat een goede keuze de prestatie duidelijk kan verbeteren, en dat de beste waarde afhankelijk is van de dataset. Visualisaties van de featurespaces en de resulterende beslissingsgrenzen maken duidelijk dat sommige maps fijnmazig, goed uitgelijnde scheidingsregio’s vormen, terwijl andere vervormde of slecht geplaatste grenzen achterlaten, wat de spreiding in resultaten verklaart.
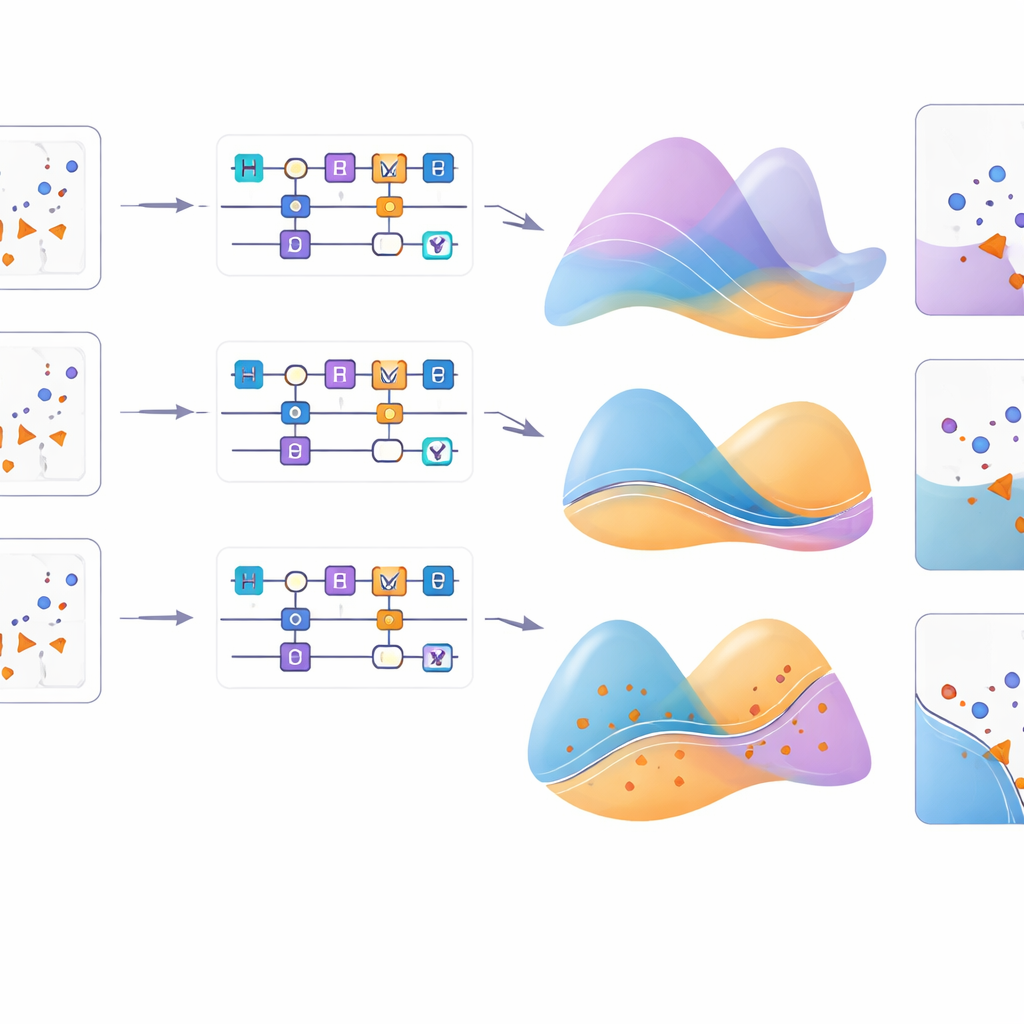
Inzoomen op hoe het werkt
Om deze effecten beter te begrijpen, visualiseert de studie hoe elke feature map een raster van invoerpunten herschikt voor verschillende problemen. Voor het cirkelpatroon reproduceren de meeste maps met succes de onderliggende structuur, maar voor de sikkelmanen en de echte kankergegevens sluiten slechts enkele maps goed aan op de werkelijke distributie. Aanvullende experimenten variëren het type single-qubitrotatie dat wordt gebruikt en bevestigen dat, voor bepaalde patronen zoals XOR, de keuze van de rotatie-as even belangrijk kan zijn als de gedetailleerde coderingsformule. In het algemeen behoort de nieuwe feature map consequent tot de besten, met name wanneer deze wordt gecombineerd met een geschikte rotatiefactor, wat de subtiele wisselwerking tussen quantumpoorten, coderingsformules en hyperparameterinstellingen benadrukt.
Wat dit voortaan betekent
Voor niet-specialisten is de belangrijkste boodschap dat quantumvoordeel in machine learning niet “gratis” zal komen door gewoon standaardmodellen op quantumhardware te draaien. Succes hangt in plaats daarvan af van het zorgvuldig ontwerpen van de manier waarop data in quantumcirkels worden gevoed en van het afstemmen van enkele kritische instellingen zodat de quantumtoestanden de structuur van het probleem vastleggen. Dit artikel biedt een stappenplan om precies dat te doen met quantumkernels en laat zien dat doordacht ontworpen en afgestemde quantum feature maps sterke, soms superieure prestaties kunnen opleveren, zelfs met zeer kleine circuits. Tegelijk merken de auteurs op dat hun resultaten zijn gebaseerd op simulaties zonder hardwareruis en op relatief bescheiden datasets, dus het volledig realiseren van deze verbeteringen op echte quantummachines en op grotere schaal blijft een belangrijke uitdaging voor toekomstig werk.
Bronvermelding: Jha, R.K., Kasabov, N., Bhattacharyya, S. et al. Comparative performance analysis of quantum feature maps for quantum kernel-based machine learning. Sci Rep 16, 8142 (2026). https://doi.org/10.1038/s41598-026-39392-9
Trefwoorden: quantum machine learning, quantum kernels, feature maps, hyperparameterafstelling, classificatie