Clear Sky Science · nl
CGDFNet: een duale-tak realtime netwerk voor semantische segmentatie met context-gestuurde detailfusie
Auto’s leren de hele straat te zien
Moderne auto’s en robots vertrouwen steeds meer op camera’s om de wereld om hen heen te begrijpen—wegen, trottoirs, mensen, voertuigen en verkeersborden in realtime detecteren. Dit artikel introduceert CGDFNet, een nieuw computervisiesysteem dat is ontworpen om dit soort ‘scènebegrip’ sneller en nauwkeuriger uit te voeren, vooral in drukke stadsstraten. Door tegelijkertijd zowel fijne details (zoals lantaarnpalen of fietswielen) als het grote geheel (zoals wegen en gebouwen) scherp te houden, wil CGDFNet geautomatiseerd vervoer en andere realtime visietaken veiliger en betrouwbaarder maken.
Waarom pixelniveau‑visie zo veeleisend is
Bij semantische segmentatie kent een computer elke individuele pixel in een afbeelding een categorie toe: weg, auto, voetganger, lucht, enzovoort. Dat is veel veeleisender dan enkel een kader om een auto tekenen, omdat het systeem objectgrenzen en kleine vormen met hoge precisie moet volgen. Er bestaan veel methoden met hoge nauwkeurigheid, maar die zijn vaak traag en energieintensief, wat slecht past bij realtime systemen in auto’s, drones of draagbare apparaten. Lichtgewicht methoden die snel draaien, offeren daarentegen vaak detail op of verliezen het overzicht, wat problematisch is bij kleine objecten, dunne structuren of drukke stedelijke omgevingen.
Twee paden: één voor detail, één voor context
CGDFNet pakt dit spanningsveld aan met een duale‑takarchitectuur: de ene tak richt zich op scherpe details, de andere op brede context. Gebouwd op een efficiënte backbone voeden lagere lagen een ‘detailtak’ die een hogere resolutie behoudt om randen en texturen te bewaren. Diepere lagen voeden een ‘contexttak’ die de scène in een meer gecomprimeerde vorm bekijkt, geschikt om de algemene structuur en relaties tussen objecten te vatten. In tegenstelling tot eerdere twee‑taksontwerpen die deze stromen grotendeels gescheiden houden en ze vervolgens ruw optellen, stimuleert CGDFNet communicatie tussen beide takken gedurende de verwerking, zodat fijne details continu worden getoetst aan wat het netwerk weet over het gehele beeld.
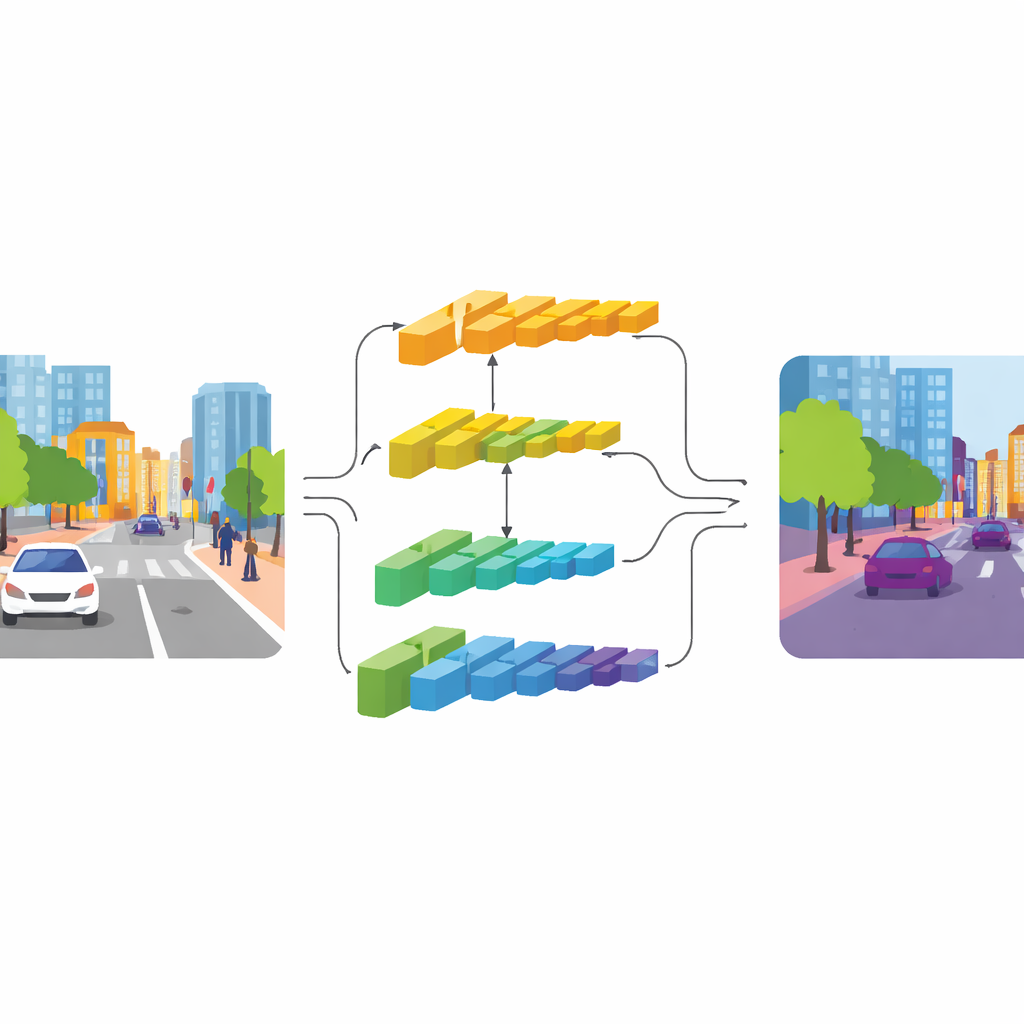
Details begeleiden met betekenis
Twee kernelementen versterken deze interactie. In de contexttak leert een Semantic Refinement Module de meest informatieve regio’s en kanalen in zijn feature‑maps te benadrukken. Dat gebeurt door lokale aanwijzingen (welke delen van de scène actief zijn dicht bij elkaar) te combineren met globale aanwijzingen (wat het netwerk over het hele beeld ziet), zodat de representatie zowel buurtig detail als scène‑niveau betekenis draagt. In de detailtak gebruikt een Context‑Guided Detail Module deze semantische informatie om de aandacht te richten op randen en fijne structuren die er toe doen, zoals de omtrek van een bus of het frame van een fiets. Deze module maakt gebruik van een speciaal soort convolutie die gevoeliger is voor verschillen tussen aangrenzende pixels, wat van nature contouren en kleine objecten benadrukt zonder veel extra parameters toe te voegen.
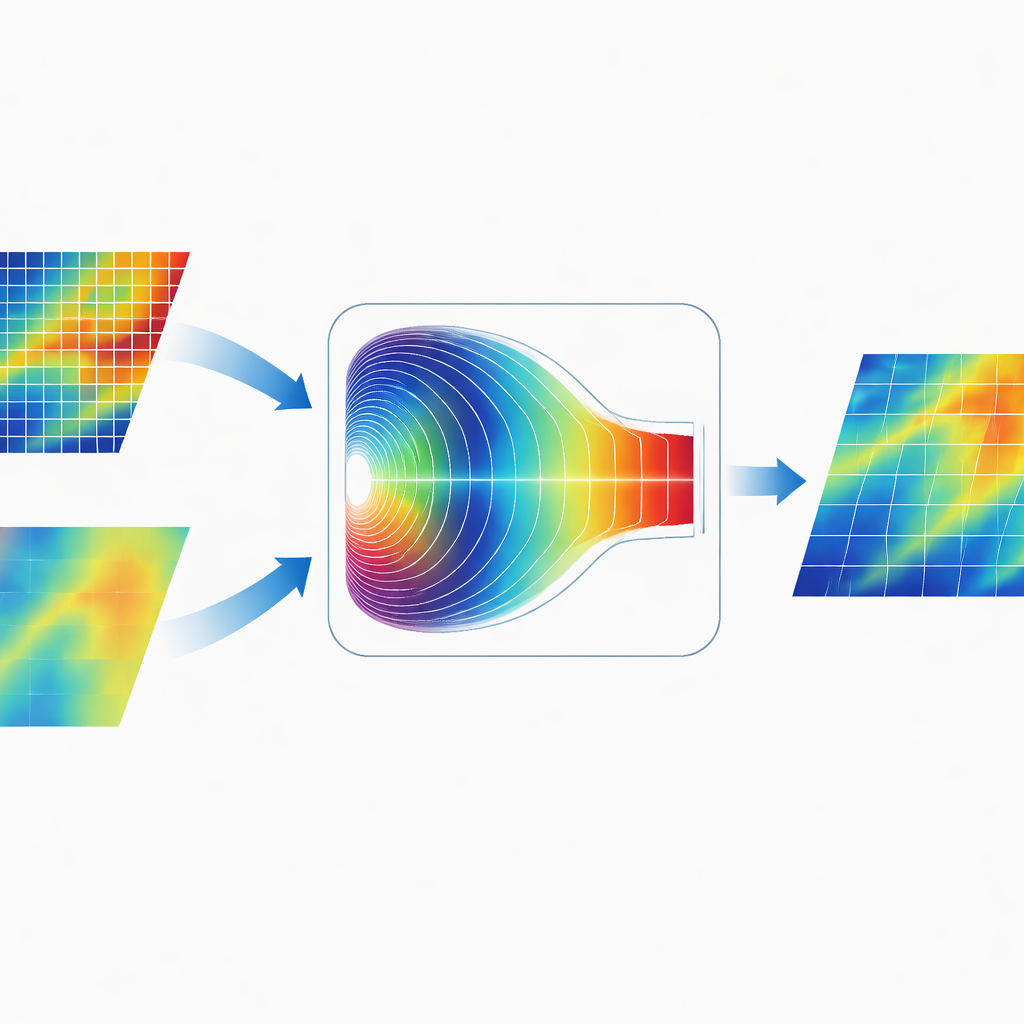
Informatie mengen in het frequentiedomein
Een onderscheidend kenmerk van CGDFNet is de manier waarop het de twee takken samenvoegt. In plaats van hun kaarten eenvoudig in beeldruimte op te tellen, ontwerpen de auteurs een Fourier‑Domain Adaptive Fusion Module. Deze module transformeert de gecombineerde features tijdelijk naar het frequentiedomein, waar patronen worden weergegeven als langzame, brede variaties en snelle, scherpe veranderingen. Een adaptief gating‑mechanisme leert vervolgens welke frequentiecomponenten benadrukt moeten worden vanuit de detailtak en welke vanuit de contexttak. Na deze weging worden de features teruggetransformeerd, wat resulteert in een representatie die scherpe randen en coherente globale structuur effectiever verenigt dan traditionele uitsluitend ruimtelijke fusie.
Resultaten op echte straten
Het team testte CGDFNet op twee veelgebruikte benchmarks voor stedelijke rijscènes: Cityscapes, verzameld in Europese steden, en CamVid, opgenomen vanuit het perspectief van een bestuurder in het Verenigd Koninkrijk. CGDFNet verwerkte grote afbeeldingen op realtime‑snelheden—ongeveer 88 frames per seconde op Cityscapes en ongeveer 129 frames per seconde op CamVid—terwijl het segmentatienauwkeurigheid behaalde die vele state‑of‑the‑art systemen evenaart of overtreft. Het presteerde bijzonder goed op categorieën die gewoonlijk moeilijk te segmenteren zijn, zoals hekken, verkeersborden, bussen en fietsen, waar het behouden van precieze grenzen en kleine structuren cruciaal is.
Wat dit betekent voor alledaagse technologie
In praktische zin laat CGDFNet zien dat het mogelijk is om visionsystemen te bouwen die zowel snel genoeg zijn voor realtime gebruik als nauwgezet genoeg om kleine, veiligheidkritische details in complexe stedelijke scènes te respecteren. Door een detailgerichte tak, een contextgerichte tak en een slimme fusiestap in het frequentiedomein te combineren, behoudt het netwerk een gebalanceerd beeld van de straat: het weet waar alles is en waar elk object begint en eindigt. Hoewel uitdagingen blijven—zoals dicht opeengepakte menigten of slecht weer—biedt de aanpak een veelbelovend blauwdruk voor toekomstige on‑device visie, van zelfrijdende auto’s tot slimme verkeerscamera’s en assistieve robots.
Bronvermelding: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Trefwoorden: realtime semantische segmentatie, autonoom rijzicht, duale-tak neurale netwerk, Fourier-gebaseerde featurefusie, stedelijke scènebegrip