Clear Sky Science · nl
Een end-to-end convolutioneel neuraal netwerk voor veilige beeldoverdracht via gezamenlijke encryptie en steganografie
Waarom het verbergen van afbeeldingen in andere afbeeldingen ertoe doet
Dagelijks versturen ziekenhuizen, banken en gewone mensen enorme aantallen foto’s via internet — van medische scans tot identiteitskaarten en familiefoto’s. Deze beelden privé houden betekent meestal dat ze worden versleuteld, waardoor ze op willekeurige ruis gaan lijken, of dat ze worden verborgen in andere afbeeldingen, een truc die steganografie wordt genoemd. Beide benaderingen hebben een zwakte: versleutelde beelden trekken aandacht, en verborgen beelden kunnen door slimme analyse worden ontdekt. Dit artikel introduceert een nieuw deep‑learningsysteem dat beide ideeën combineert, met als doel geheime afbeeldingen op een manier te verzenden die voor het menselijk oog natuurlijk oogt maar moeilijk te kraken is voor aanvallers.
Het probleem met de huidige beschermingsmethodes
Traditionele encryptietools zoals AES en DES zijn wiskundig sterk, maar ze veranderen een foto in een blok visuele ruis dat duidelijk aangeeft: “hier zit iets belangrijks.” Klassieke steganografie doet het tegenovergestelde: informatie wordt verstopt in de fijne details van een normaal ogende afbeelding, maar vaak zonder sterke cryptografische bescherming. Als een aanvaller de truc detecteert, kan het verborgen bericht makkelijk worden uitgelezen. Recente deep‑learningmethoden verbeterden ofwel encryptie ofwel verbergen, maar de meeste behandelen ze als twee aparte stappen. Die scheiding verspilt rekenkracht en kan fouten uit de ene fase laten doorwerken in de andere. De auteurs stellen dat wat ontbreekt een enkel systeem is dat end‑to‑end leert hoe het beelden gelijktijdig moet camoufleren en beschermen.
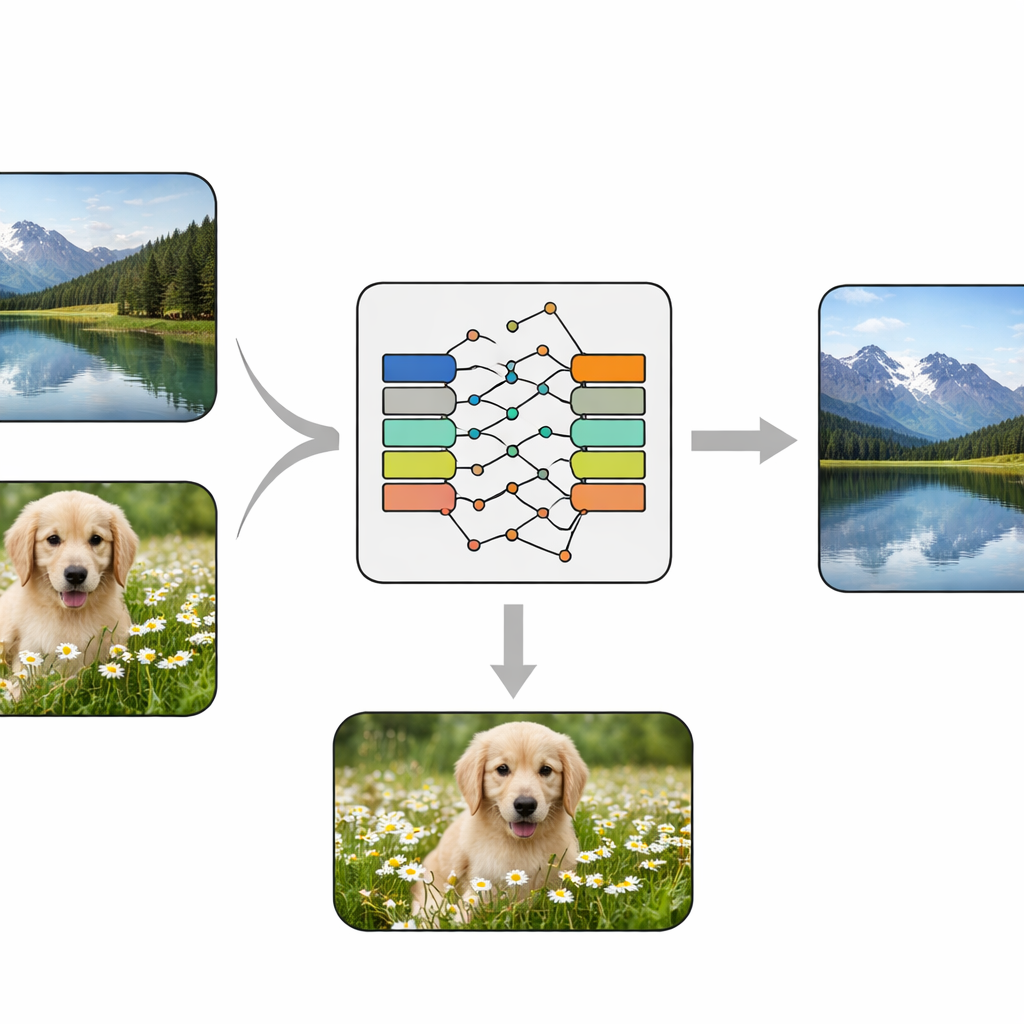
Een enkel brein dat vercijfert en verbergt
De onderzoekers ontwerpen een end‑to‑end convolutioneel neuraal netwerk — feitelijk een trainbare beeldverwerkingspijplijn — die twee afbeeldingen als invoer neemt: een normale “cover” foto en een “geheime” foto die beschermd moet worden. Eerst transformeert een speciaal module, de KeyMixer, de geheime afbeelding met trainbare numerieke sleutels. In tegenstelling tot vaste, handgemaakte ciphers leert deze mixer content‑afhankelijke wijzigingen die afhankelijk zijn van texturen en vormen in de afbeelding, waardoor subtiele, niet‑voor de hand liggende vervormingen ontstaan. Vervolgens mengt een Encoder‑netwerk deze getransformeerde geheim zachtjes in de cover afbeelding, en creëert zo een “container” afbeelding die nog steeds natuurlijk moet lijken. Aan de ontvangende kant reconstrueert een corresponderend Decoder‑netwerk alleen op basis van de container afbeelding het verborgen geheim, zonder dat extra sleutels of zijinformatie nodig zijn tijdens het herstel.
Het netwerk leren geheimhouding en uiterlijk in balans te houden
Het trainen van dit systeem betekent dat het twee doelen tegelijk moet bereiken: de container afbeelding visueel dicht bij de oorspronkelijke cover houden, en het geheime beeld zo nauwkeurig mogelijk herstellen. De auteurs doen dit met een dubbel‑verliesstrategie die zowel zichtbare veranderingen aan de cover als fouten in het gereconstrueerde geheim straft. Ze gebruiken een populaire benchmarkcollectie van natuurlijke foto’s, de STL‑10 dataset, en passen standaard data‑augmentatietrucs toe zoals spiegelen en kleine rotaties zodat het netwerk diverse scènes ziet. Tijdens het trainen verbetert het model gestaag totdat beide doelstellingen stabiliseren, wat aangeeft dat het een werkbaar midden vindt tussen onzichtbaarheid en getrouwe reconstructie.
Hoe goed de verborgen afbeeldingen overleven
Om de kwaliteit te beoordelen, meet het team hoe gelijk de container afbeeldingen zijn aan de covers en hoe nauw de gereconstrueerde geheimen overeenkomen met de originelen, met behulp van standaard beeldkwaliteitscores. Op de testafbeeldingen behaalt de methode hoge structurele gelijkenis voor zowel cover als geheim, met waarden boven 0,90, wat betekent dat vormen en details grotendeels bewaard blijven. Geheime afbeeldingen bereiken met name zeer hoge gelijkenis, wat wijst op vrijwel perfecte perceptuele reconstructie. Vergeleken met verschillende moderne deep‑learningsteganografiesystemen en hybride pijplijnen levert het nieuwe end‑to‑endmodel de beste reconstructie van het geheime beeld, ook al behouden sommige rivalen de cover iets beter. Statistische tests van pixeldistributies, willekeurigheid en gevoeligheid voor veranderingen suggereren dat de containers geen duidelijke aanwijzingen geven dat er iets verborgen is.
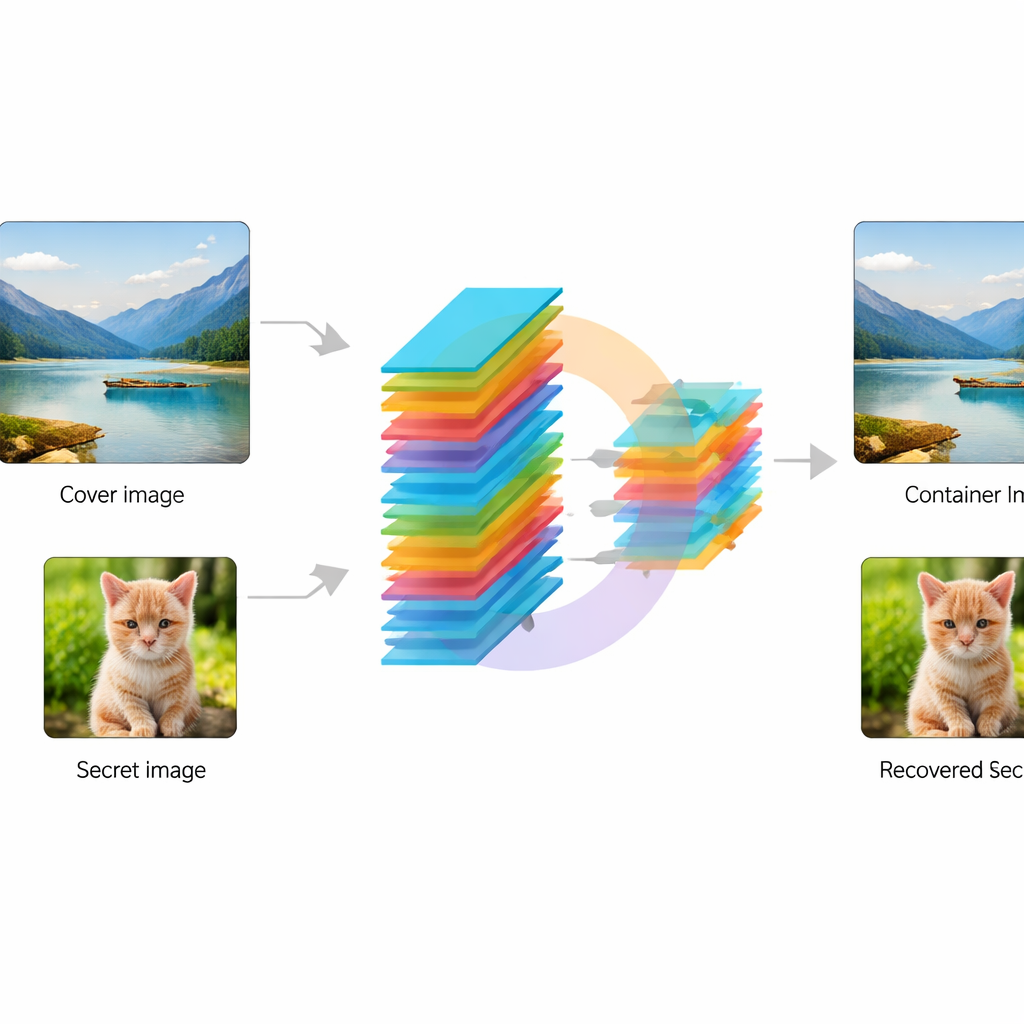
Wat dit kan betekenen voor alledaagse privacy
Kort gezegd laat dit werk zien dat een enkel deep‑learningmodel kan leren om beelden tegelijk te camoufleren en te beschermen, zodat een verborgen afbeelding met hoge helderheid kan worden teruggewonnen terwijl de gedeelde afbeelding er nog steeds gewoon uitziet. In plaats van encryptie en steganografie lomp achter elkaar te zetten, leert het systeem een vloeiende compromis tussen visuele subtiliteit en veiligheid. Hoewel het momenteel krachtige hardware vereist en verdere tests tegen geavanceerde aanvallen nodig heeft, wijst de aanpak op toekomstige tools die medische scans, persoonlijke foto’s of andere gevoelige afbeeldingen stilletjes kunnen beveiligen in routinematige online communicatie, zonder te verraden dat er iets geheim is.
Bronvermelding: Iqbal, A., Sattar, H., Shafi, U.F. et al. An end-to-end convolutional neural network for secure image transmission via joint encryption and steganography. Sci Rep 16, 8228 (2026). https://doi.org/10.1038/s41598-026-39351-4
Trefwoorden: beeldbeveiliging, steganografie, deep learning, neurale encryptie, privacybescherming