Clear Sky Science · nl
Topologie-gemaskerde voorspelling van skeletbeweging en contrastief leren voor zelfgestuurde herkenning van menselijke acties
Computers leren lichaamstaal te lezen
Van videodeurbellen tot slimme revalidatiehulpmiddelen: veel moderne systemen moeten kunnen begrijpen wat mensen doen alleen door te kijken hoe ze bewegen. Maar computers trainen om menselijke acties te herkennen vereist doorgaans enorme, zorgvuldig gelabelde datasets waarin elke zwaai, trap of handdruk handmatig is geannoteerd. Deze studie introduceert een manier waarop machines kunnen leren van ruwe bewegingsdata alleen, met alleen het bewegende skelet van het lichaam — geen labels, geen gezichten en geen full-color video — waardoor actieherkenning nauwkeuriger, privacyschonender en veel minder afhankelijk van dure menselijke annotatie wordt.
Waarom skeletten genoeg zijn
In plaats van volledige videoframes te analyseren, werkt de methode met 3D-skeletgegevens: de coördinaten van belangrijke gewrichten zoals schouders, ellebogen, heupen en knieën door de tijd heen. Deze uitgeklede weergave van het lichaam heeft meerdere voordelen. Het omzeilt grotendeels privacyproblemen omdat gezichten en kleding zijn verwijderd, en het is compact genoeg om efficiënt te verwerken, zelfs bij lange opnamen. Skeletten zijn ook robuust tegen rommelige achtergronden en lichtveranderingen die reguliere video-gebaseerde systemen in de war kunnen brengen. Toch vertrouwen de meeste bestaande skeletgebaseerde benaderingen nog steeds sterk op gelabelde voorbeelden en slagen ze er niet altijd in om volledig vast te leggen hoe gewrichten samen bewegen in complexe, gecoördineerde acties.
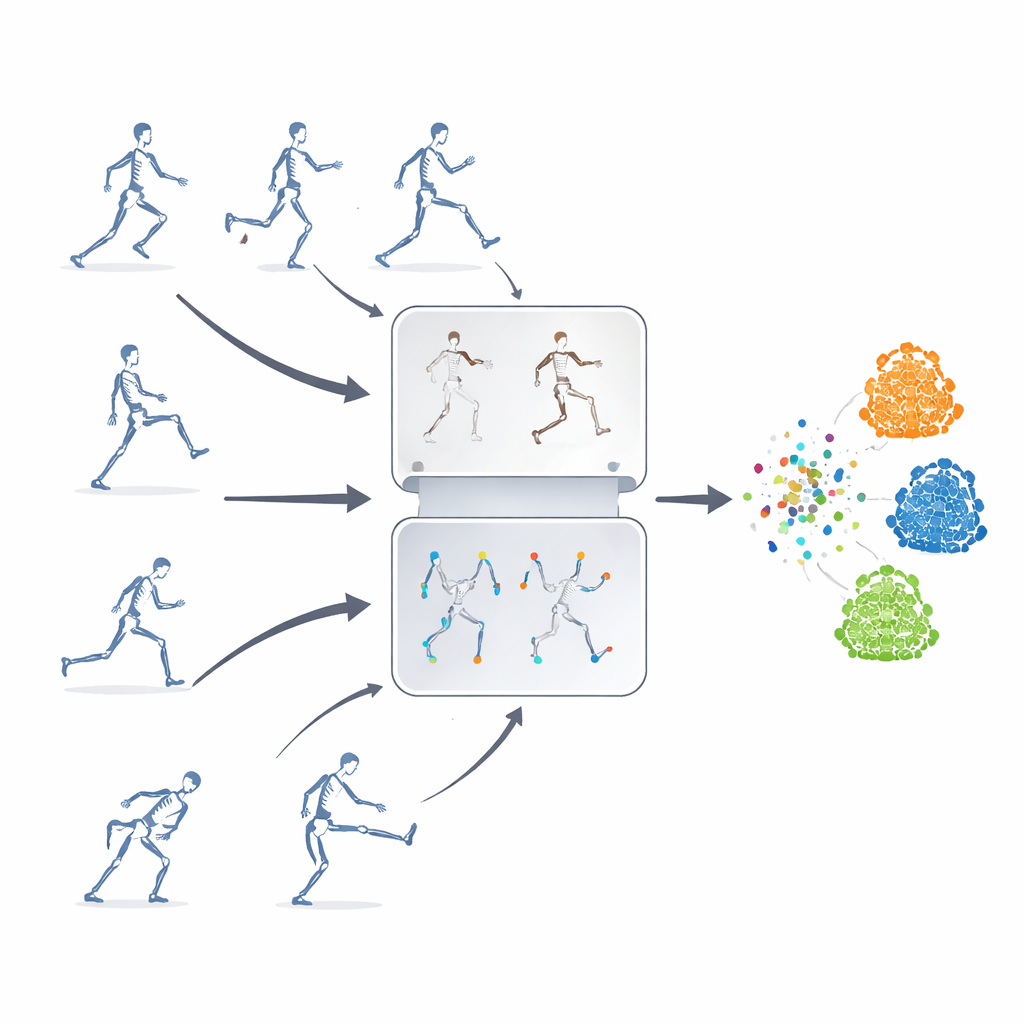
Leren zonder labels
De auteurs stellen een zelfgestuurd leerraamwerk voor, wat betekent dat het systeem zichzelf leert van ongelabelde skeletreeksen. Hun kernidee is twee krachtige strategieën te combineren die gewoonlijk apart worden gebruikt. De ene is “gemaskerde voorspelling”, waarbij delen van de skeletdata opzettelijk worden verborgen zodat het model de ontbrekende beweging uit de resterende context moet raden. De andere is “contrastief leren”, waarbij het model meerdere gewijzigde versies van dezelfde actie te zien krijgt en wordt getraind om te beseffen dat deze variaties nog steeds één onderliggende beweging vertegenwoordigen. Door deze benaderingen te mengen, leert het systeem zowel fijne details van gewrichtsbewegingen als de grote-lijnbetekenis van een actie.
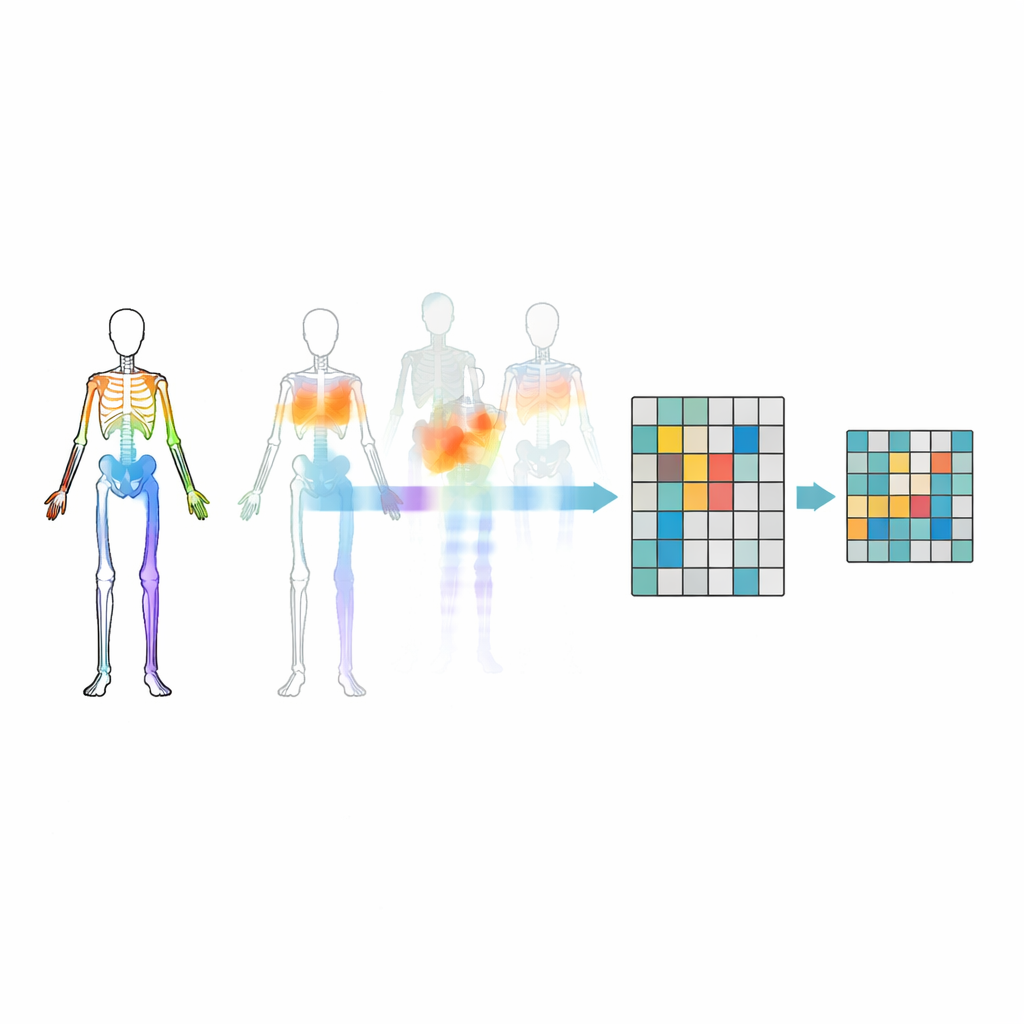
De juiste gewrichten verbergen
Willekeurig gewrichten maskeren is niet voldoende — het model kan belangrijke relaties tussen lichaamsdelen negeren of zich fixeren op de meest voor de hand liggende bewegingen. Om dit te voorkomen introduceren de onderzoekers een motion–topologie-maskingstrategie. Ze groeperen gewrichten in betekenisvolle lichaamsregio’s zoals armen, benen en romp, en meten vervolgens hoe sterk elke regio door de tijd beweegt. Maskerbeslissingen worden geleid door zowel de lichaamsstructuur als hoeveel elke regio beweegt, zodat soms zeer actieve delen worden verborgen en het model gedwongen wordt ze uit de rest van het lichaam af te leiden. Dit gerichte verbergen helpt het systeem te leren hoe gewrichten samenwerken tijdens acties, in plaats van alleen een paar opvallende bewegingen te onthouden.
Acties op veel manieren uitrekken
Om het contrastieve deel van het systeem te trainen wordt dezelfde oorspronkelijke skeletreeks in veel verschillende “views” getransformeerd. Sommige veranderingen zijn subtiel, zoals het bijsnijden van het tijdvenster of het licht vervormen van de trajectorie, terwijl andere extremer zijn, waaronder flips, rotaties en sterkere ruis. Deze meerdere niveaus van augmentatie stellen het model bloot aan een rijke variëteit aan bewegingspatronen en moedigen het aan zich te richten op de kernstructuur van een actie in plaats van oppervlakkige details. Tegelijkertijd volgt een trajectgeïntegreerde feature-droppingmodule welke bewegingskenmerken het model het meest gebruikt en onderdrukt deze opzettelijk tijdens training. Door tijdelijk zijn favoriete aanwijzingen te verwijderen wordt het systeem gedwongen alternatieve signalen te ontdekken en meer algemene, overdraagbare representaties te leren.
Hoe goed werkt het?
Het raamwerk is getest op drie grote openbare benchmarks voor 3D-menselijke acties, met voorbeelden van alledaags gedrag, medische bewegingen en interacties tussen mensen. Hoewel het slechts skeletgewrichtsdata en een relatief lichtgewicht recurrent neuraal netwerk gebruikt, evenaart of overtreft de methode veel state-of-the-art systemen die afhankelijk zijn van complexere invoer of architecturen. Het is bijzonder sterk wanneer annotatie schaars is of wanneer sommige lichaamsdelen zijn geoccludeerd, omstandigheden die vaak in reële omgevingen voorkomen. Hoewel het vermogen om kennis over zeer verschillende datasets te transfereren nog verbetering behoeft, verkleint de aanpak de kloof tussen gelabelde en ongelabelde training voor actieherkenning aanzienlijk.
Wat dit betekent voor systemen in de praktijk
Voor niet-specialisten komt het erop neer dat dit werk laat zien hoe computers veel beter lichaamstaal kunnen lezen zonder expliciet te worden verteld wat elke beweging betekent. Door tijdens training skeletdata slim te verbergen en te vervormen, leert het model robuuste bewegingspatronen die standhouden onder slechte belichting, visuele rommel of ontbrekende gewrichten, en doet dat met veel minder door mensen aangeleverde labels. Dit opent de deur naar actieherkenningssystemen die privacyschonender, schaalbaarder en aanpasbaarder zijn voor toepassingen variërend van thuisbewaking en sportcoaching tot medische revalidatie en mens-robotinteractie.
Bronvermelding: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Trefwoorden: herkenning van menselijke acties, 3D skeletgegevens, zelfgestuurd leren, contrastief leren, bewegingsanalyse