Clear Sky Science · nl
Deep learning-gestuurde pseudonimisering ter bescherming van privacy van financiële identificatoren in openbare documenten in India
Waarom je handtekening op een ID-kaart risico loopt
De meesten van ons zetten onze handtekening op overheids-ID-kaarten, bankformulieren en belastingdocumenten zonder erbij stil te staan dat die kronkelende lijnen gekopieerd, vervalst of door kwaadwillenden uitgelezen kunnen worden. Naarmate kantoren deze documenten vaker scannen en online delen, zijn handgeschreven handtekeningen—die op veel plaatsen nog steeds als juridisch bindend worden beschouwd—een aantrekkelijk doelwit voor identiteitsdiefstal geworden. Dit artikel onderzoekt een nieuwe manier om handtekeningen op Indiase belasting-ID-kaarten te verbergen, terwijl de documenten bruikbaar blijven voor administratie, audits en toekomstige verificatie.
Reële handtekeningen omzetten in veilige vervangers
De auteurs richten zich op India’s Permanent Account Number (PAN)-kaart, veelgebruikt voor financiële transacties en belastingaangifte. Deze kaarten duiken steeds vaker op in e-mails, cloudopslag en publieke inzendingen, waarbij blootgestelde handtekeningen gekopieerd of op valse documenten gedrukt kunnen worden. Handtekeningen simpelweg vervagen of zwart maken beschermt de privacy, maar maakt het document onbruikbaar voor latere verificatie of onderzoek. In plaats daarvan gebruiken de onderzoekers een strategie die pseudonimisering heet: de oorspronkelijke handtekening wordt gedetecteerd en vervangen door een synthetische look‑alike die positie en structuur van het merkteken behoudt, maar niet meer dicht genoeg op het echte handschrift lijkt om misbruikt te worden.
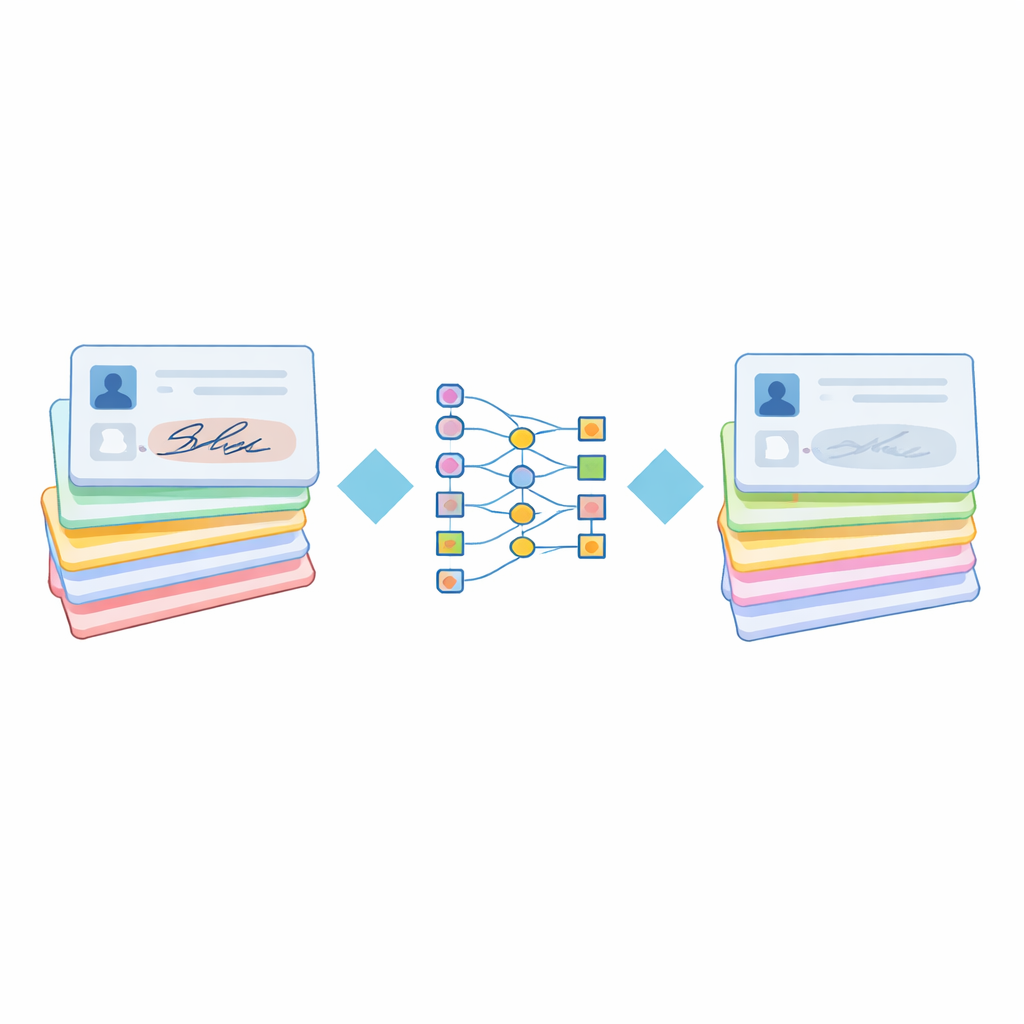
Hoe een slim visiesysteem vindt wat te verbergen
Om dit proces te automatiseren bouwt het team voort op een deep‑learningmodel bekend als SuperPoint, oorspronkelijk ontworpen om belangrijke punten in beelden te vinden—zoals hoeken en randen—die betrouwbaar blijven zelfs als de afbeelding ruisig, gekanteld of licht vervaagd is. De methode verwerkt PAN-kaartscans eerst door ze te schalen en naar grijsschaal om te zetten om de berekening te vereenvoudigen. Vervolgens wordt het gebied met de handtekening geïsoleerd. In dat gebied werkt het SuperPoint-netwerk als een gespecialiseerde vergrootglas: een deel van het netwerk produceert een heatmap die aangeeft waar onderscheidende pennenstreken liggen, en een ander deel genereert compacte numerieke beschrijvingen van die streken. Deze combinatie stelt het systeem in staat precies vast te stellen welke delen van het handschrift het meest onderscheidend zijn en dus het gevaarlijkst om bloot te laten.
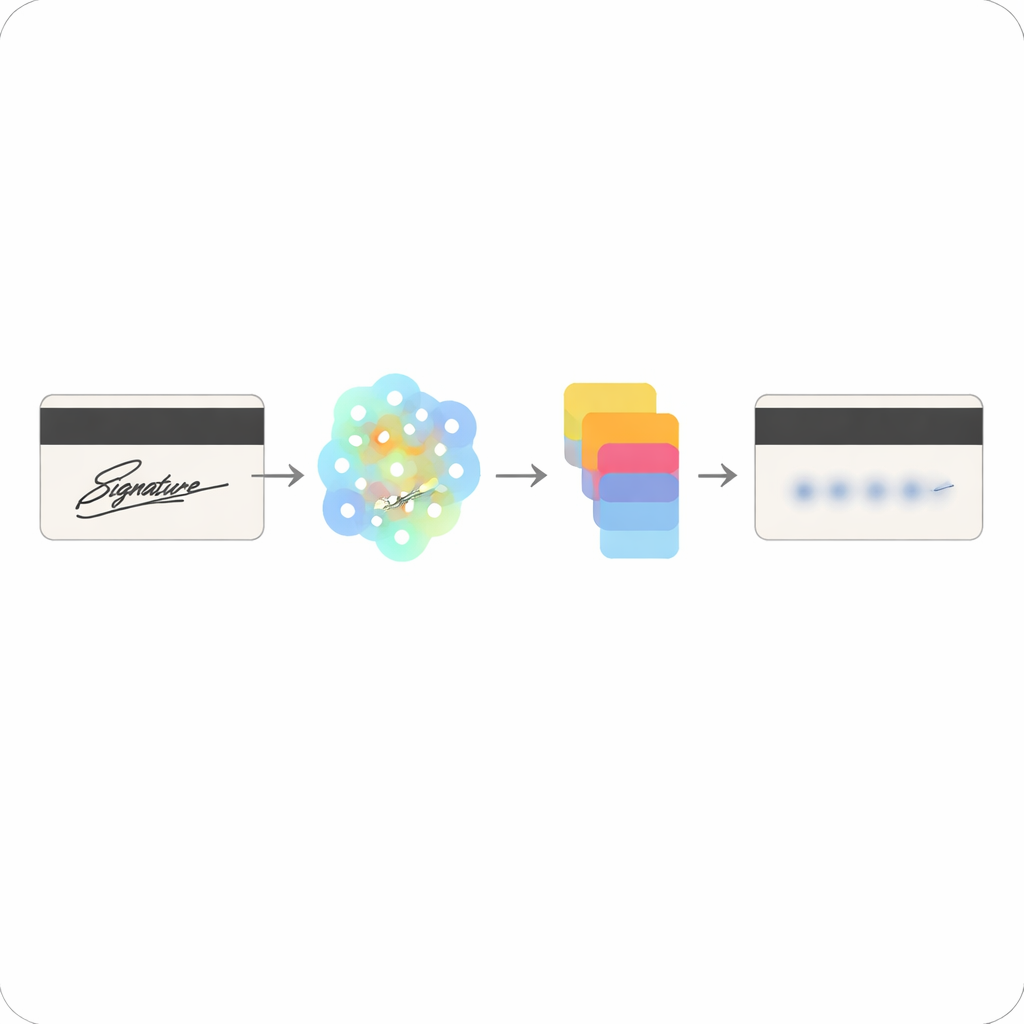
Van streken en keypoints naar gemaskeerde markeringen
Zodra de belangrijke locaties in de handtekening zijn geïdentificeerd, vervangt het systeem ze door neutrale vormen die het uiterlijk van een ondertekend gebied behouden zonder de persoonlijke stijl van de schrijver prijs te geven. In plaats van het originele inktpatroon op te slaan, vertrouwt het model op abstracte feature maps—wiskundige samenvattingen van waar de sleutelpunten zaten—waardoor het veel moeilijker wordt voor een aanvaller om de echte handtekening te reconstrueren. De auteurs gebruiken ook een hulpmiddel genaamd Kornia om de ruwe outputs van het netwerk om te zetten in precieze coördinaten, schalen en oriëntaties, wat helpt te waarborgen dat het gemaskeerde gebied netjes uitlijnt met het oorspronkelijke handtekeninggebied en werkt over verschillende kaartindelingen en scankwaliteit heen.
Hoe goed de nieuwe aanpak presteert
Het raamwerk is getest op meer dan 500 echte PAN-kaartafbeeldingen verzameld uit open datasets, met veel handschriften en kaartontwerpen. De prestatie wordt vergeleken met veelgebruikte traditionele feature‑vindmethoden—ORB, FAST en SIFT—alsook met een diepe residuele netwerkarchitectuur. De onderzoekers meten hoe nauwkeurig het systeem handtekeningdetails vindt, hoe dicht het gemaskeerde document visueel bij het origineel blijft en hoeveel rekenkracht en opslag vereist zijn. Hun methode behaalt hoge precisie en recall bij het lokaliseren van cruciale delen van de handtekeningen en bereikt een structurele gelijkenheidsscore van ongeveer 97 procent, wat betekent dat de gepseudonimiseerde kaarten vrijwel identiek lijken aan de originelen, behalve voor de beschermde markeringen. Tegelijkertijd gebruikt het een bescheiden aantal keypoints en compacte descriptors, wat een balans biedt tussen nauwkeurigheid, snelheid en geheugengebruik.
Wat dit betekent voor alledaagse privacy
Voor niet‑specialisten is de kernboodschap dat het nu mogelijk is automatisch een van de meest gevoelige elementen op een ID-kaart—je handgeschreven handtekening—te beschermen zonder het document te veranderen in een nutteloos zwart blok. Door echte handtekeningen te vervangen door zorgvuldig geconstrueerde vervangers, stelt het voorgestelde systeem overheden en organisaties in staat gescande ID’s te delen, op te slaan en te analyseren, terwijl het risico op vervalsing en identiteitsdiefstal sterk vermindert. De auteurs suggereren dat soortgelijke deep‑learningtools ingebouwd kunnen worden in publieke documentworkflows, waarmee landen kunnen voldoen aan moderne privacyregels zoals de AVG, en dat de aanpak uiteindelijk verder kan worden uitgebreid dan PAN-kaarten naar paspoorten, rijbewijzen en andere identiteitsdocumenten wereldwijd.
Bronvermelding: Roopalakshmi, R., Kailas, S. & Sreelatha, R. Deep learning enabled pseudonymization for preserving data privacy of financial identifiers in public documents in India. Sci Rep 16, 8120 (2026). https://doi.org/10.1038/s41598-026-39309-6
Trefwoorden: handtekeningprivacy, identiteitsbescherming, documentanonimisering, deep learning beveiliging, overheids-ID-kaarten