Clear Sky Science · nl
Een CNN-RNN Siamese-kader met multi-level aggregatie voor video-gebaseerde persoonsherkenning
Waarom het volgen van mensen over camera’s ertoe doet
Moderne steden zijn volgehangen met camera’s, maar die camera’s "praten" zelden met elkaar. Wanneer iemand van een straathoek naar een treinstation loopt, zien verschillende camera’s die persoon vanuit nieuwe hoeken, bij verschillend licht en vaak door menigten heen. Automatisch herkennen dat het in verschillende videoclips om dezelfde persoon gaat — video-gebaseerde persoonsherkenning — kan onderzoekers helpen bewegingen na een incident te reconstrueren, ondersteuning bieden bij vermissingszaken of analyses aandrijven in drukke openbare ruimten. Dit betrouwbaar en efficiënt doen, vooral op bescheiden hardware, blijft echter een belangrijke technische uitdaging.
Een eenvoudiger ‘brein’ om bewegende personen te matchen
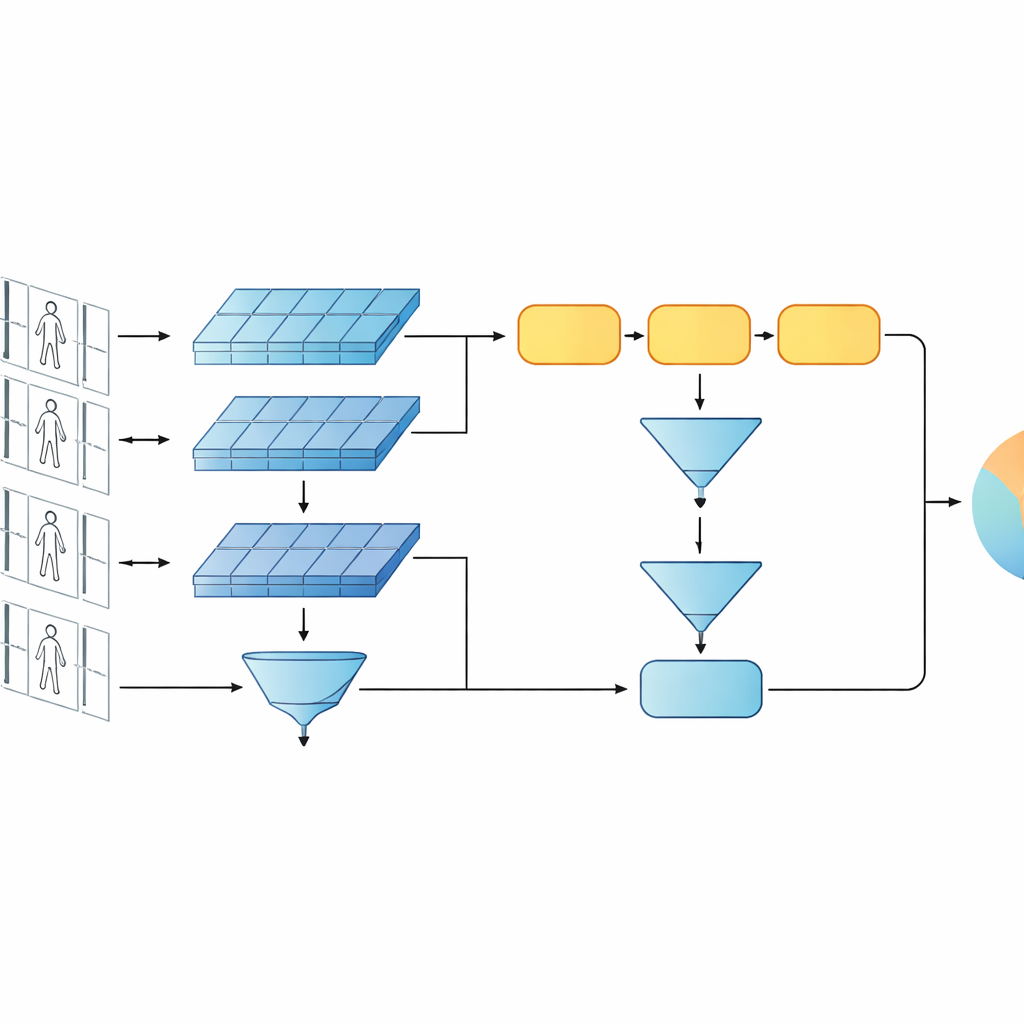
Deze studie introduceert een compact AI-systeem dat bedoeld is om te bepalen of twee korte videoclips dezelfde persoon tonen. In plaats van de huidige trend naar zeer diepe of transformergebaseerde netwerken te volgen, bouwen de auteurs voort op een zuiniger ontwerp dat twee klassieke elementen combineert: een convolutioneel netwerk dat elke videoframe analyseert en een gated recurrent unit (GRU) die volgt hoe het uiterlijk in de tijd verandert. Deze twee takken zijn opgezet in een Siamese indeling — in wezen twee identieke kopieën van hetzelfde netwerk die alle interne instellingen delen. Elke kop verwerkt één videosequentie en het systeem leert interne signaturen te produceren die vergelijkbaar zijn voor clips van dezelfde persoon en duidelijk verschillen voor verschillende personen.
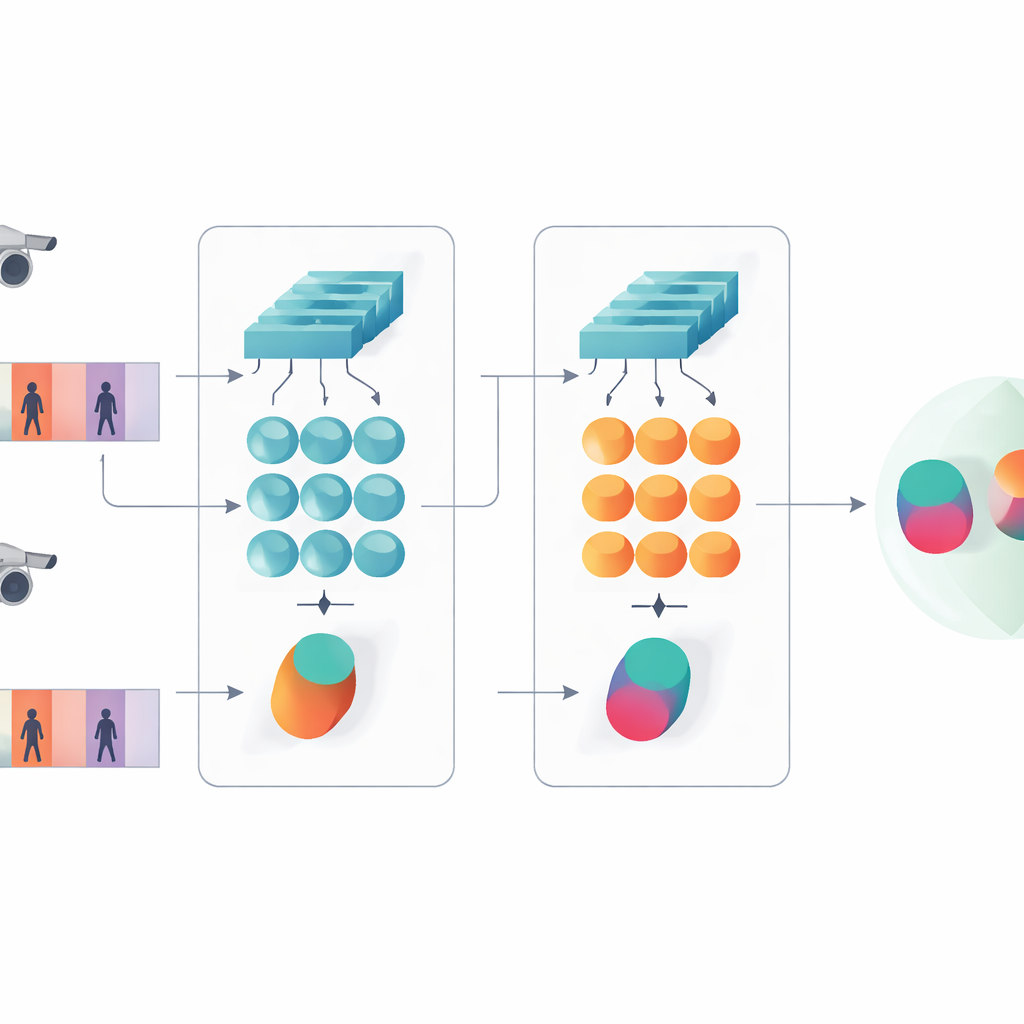
Zowel details als patronen in de tijd zien
Een kernidee van het werk is dat herkenning niet alleen mag steunen op de diepste, meest abstracte features van een netwerk. Vroegere lagen bevatten nog steeds scherpe visuele details zoals de structuur van een jas, strepen op een broek of de contour van een rugzak — aanwijzingen die vaak standhouden bij veranderende camerahoeken. Het voorgestelde model behoudt daarom twee niveaus van beschrijving. De ene tak pooled de features uit vroege lagen over alle frames om fijnmazige texturen en lokale patronen samen te vatten. De andere tak voert latere features in de GRU, die de sequentie frame voor frame volgt en vervolgens zijn interne toestanden over de tijd gemiddeld. Deze gemiddeldestap voorkomt dat de laatste paar frames te sterk tellen en vangt in plaats daarvan een consensusbeeld van hoe de persoon er door de hele clip uitziet en beweegt.
De tweelingen trainen om het eens te zijn en te classificeren
Om het systeem te leren wat belangrijk is, combineren de auteurs twee trainingsdoelen. Ten eerste stimuleert een verificatiedoel dat de twee takken nabijgelegen signaturen produceren voor video’s van dezelfde persoon en ver uiteenliggende signaturen voor verschillende personen. Ten tweede vraagt een classificatiedoel het netwerk om elke trainingsclip aan een specifieke identiteit toe te wijzen. Door beide doelen gelijktijdig te optimaliseren, en dat zowel op laag als hoog feature-niveau, leert het model interne beschrijvingen die niet alleen onderscheidend tussen personen zijn maar ook robuust tegen ruis, occlusie en occasionele frames van matige kwaliteit. Het ontwerp blijft ondiep qua lagen en parameters, wat helpt overfitting op relatief kleine videodatasets te voorkomen.
Getest op surveillance‑achtige video’s
Het kader is geëvalueerd op twee veelgebruikte video-benchmarks, PRID-2011 en iLIDS-VID, die korte loopsequenties van honderden individuen bevatten, vastgelegd door paren van niet-overlappende camera’s. De studie onderzoekt zorgvuldig verschillende ontwerpkeuzes: het vervangen van de GRU door andere recurrente eenheden, het wijzigen van het aantal recurrente lagen, het aanpassen van hoe features over de tijd worden gepooled en het in- of uitschakelen van de laag- of hoog-niveau takken. Over deze tests presteert een enkel‑laags GRU met gemiddelde pooling en de volledige multi-level opzet consequent het best. Het model evenaart of overtreft veel complexere recurrente en Siamese systemen en concurreert met sommige attention-gebaseerde ontwerpen, terwijl het veel minder parameters en rekenkracht gebruikt.
Efficiëntie voor toepassingen in de echte wereld
Naast nauwkeurigheid legt het werk de nadruk op toepasbaarheid. Het volledige netwerk heeft slechts ongeveer één tot twee miljoen trainbare parameters — ordes van grootte minder dan populaire diepe residual- of transformer-backbones — en vereist een fractie van hun rekencost per frame. Dat maakt het geschikter voor inzet op apparaten met beperkte geheugen- en verwerkingscapaciteit, zoals edge-servers nabij camera’s. Experimenten tonen ook dat langere galerijsequenties, waarbij het systeem meer frames van elke opgeslagen persoon ziet, de herkenning substantieel verbeteren, zij het met een lineaire toename van de verwerkingskosten. De auteurs betogen dat dergelijke compacte, zorgvuldig ontworpen architecturen betrouwbare persoonsherkenning kunnen leveren zonder de hoge prijs van de grootste hedendaagse modellen.
Wat dit betekent voor alledaagse surveillancesystemen
In eenvoudige bewoordingen laat dit artikel zien dat slim ontwerp zware omvang kan verslaan: door ondiepe beeldanalyse, lichtgewicht sequentiemodellering en een tweelaagse kijk op visuele gelijkenis te combineren, is het mogelijk om mensen betrouwbaar over camera’s heen te volgen terwijl het model klein en snel blijft. Voor toekomstige systemen die op veel camera’s moeten draaien, vaak met strakke hardware- en energiebudgetten, kan dit soort efficiënte, multi-level benadering helpen om meer capabele en verantwoorde video‑analyses in de praktijk te brengen.
Bronvermelding: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Trefwoorden: persoonsherkenning, video‑surveillance, Siamese neurale netwerken, temporale modellering, efficiënt deep learning