Clear Sky Science · nl
Een robuust text-to-SQL-framework voor natuurlijke taal met dynamische strategieën gebaseerd op LLM's
Dagelijkse vragen omzetten in database-antwoorden
Moderne organisaties zitten vol data, maar de meeste mensen spreken niet de technische taal die nodig is om ernaar te vragen. Dit artikel introduceert TriSQL, een systeem waarmee gebruikers in gewone taal vragen kunnen stellen die automatisch worden omgezet in precieze databasecommando's. Door zorgvuldig te sturen hoe grote taalmodellen met complexiteit omgaan, streeft het raamwerk ernaar gegevens toegankelijker te maken en tegelijkertijd de nauwkeurigheid en betrouwbaarheid te vergroten, zelfs bij de lastigste vragen.
Waarom praten met databases zo moeilijk is
Wanneer iemand een vraag typt zoals “Welke klanten hebben vorige maand meer dan vijf producten gekocht?” moet een computer dat vertalen naar SQL, de gespecialiseerde taal die door de meeste databases wordt gebruikt. Deze taak, text-to-SQL genoemd, klinkt eenvoudig maar is verrassend lastig. Het systeem moet begrijpen wat de gebruiker wil, de juiste tabellen en kolommen vinden in een soms enorme en rommelige database, en vervolgens een query construeren die zowel structureel geldig is als trouw aan de oorspronkelijke intentie. Eerdere systemen, waaronder die aangedreven door grote taalmodellen, falen vaak wanneer vragen veel tabellen, geneste logica of subtiele voorwaarden bevatten. Ze kunnen queries genereren die er op het oog correct uitzien maar niet uitvoerbaar zijn of bij uitvoering verkeerde resultaten opleveren.
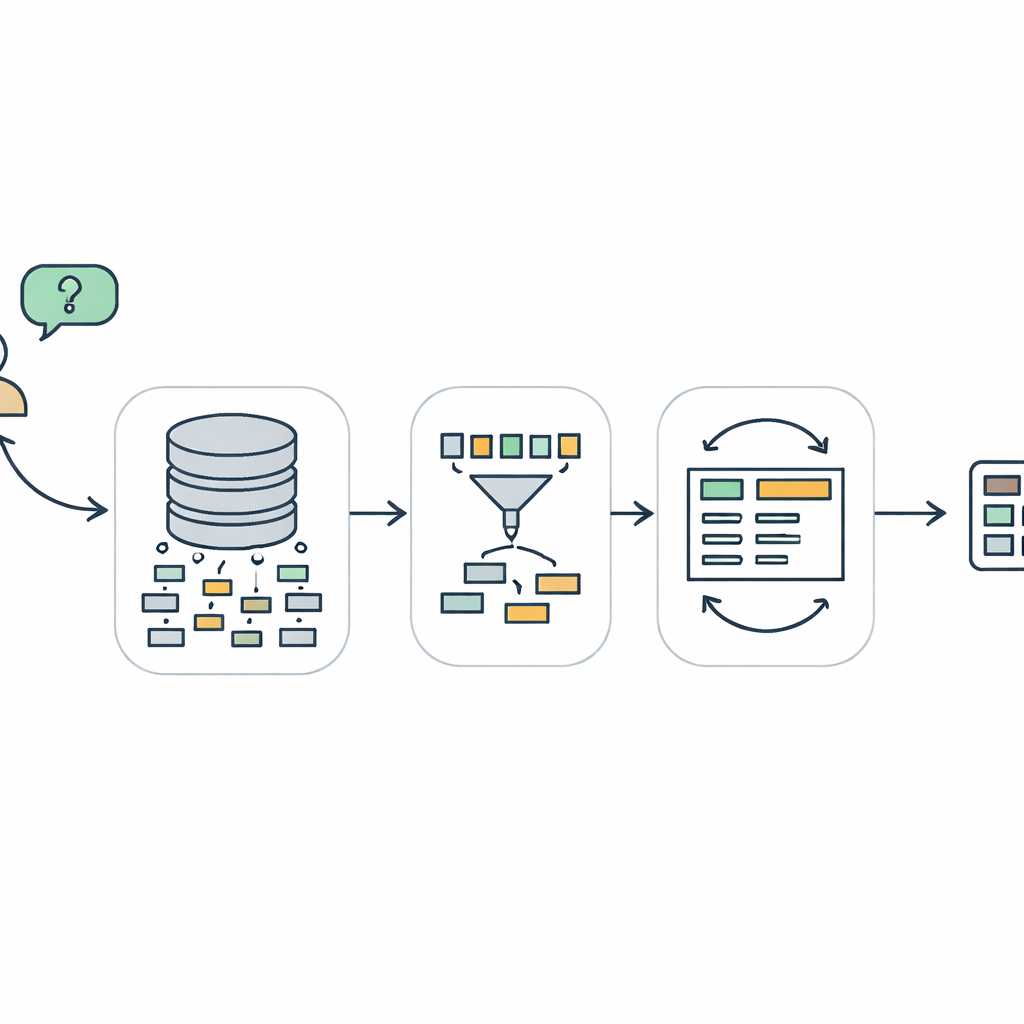
Een driestappenpad van vraag naar query
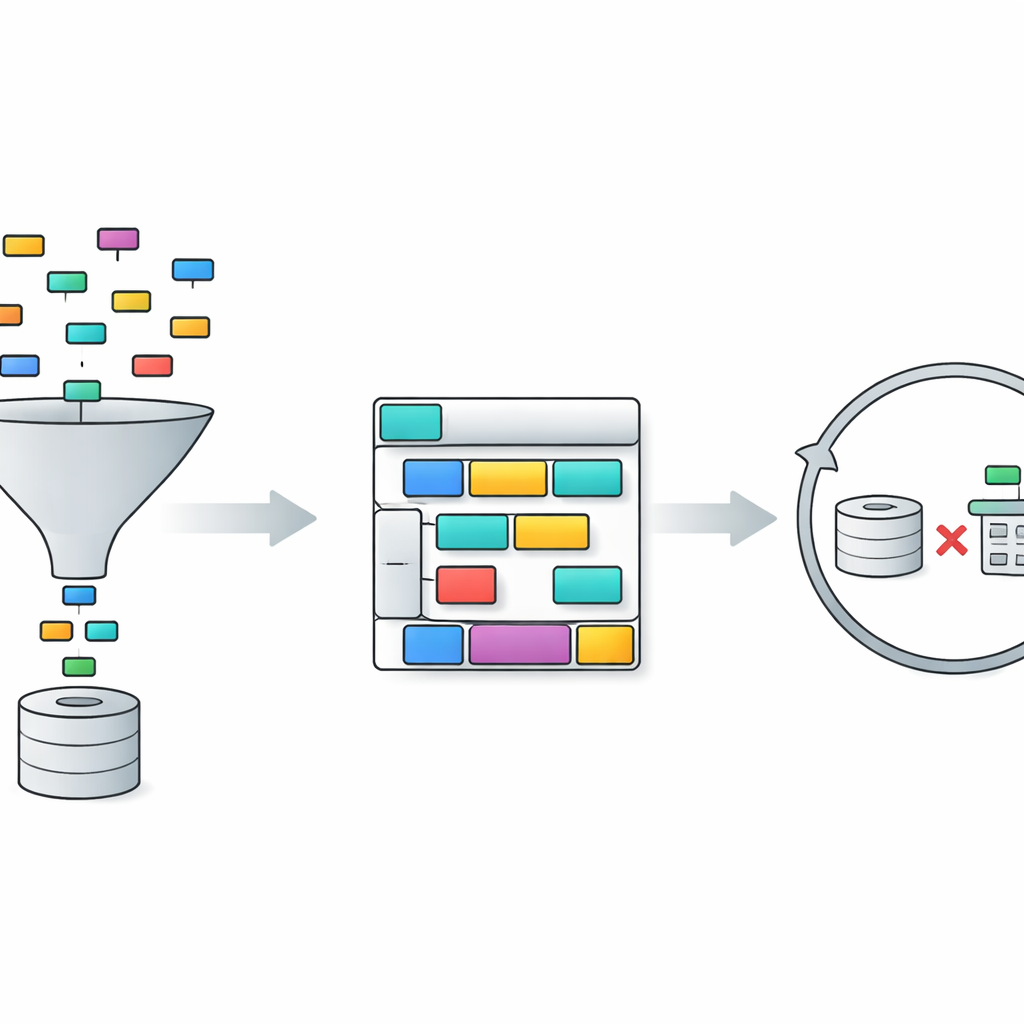
TriSQL pakt deze problemen aan met een pijplijn in drie fasen. Eerst bekijkt een vraag-gestuurde selector de woorden van de gebruiker en de volledige databaseschema en bepaalt welke tabellen en kolommen daadwerkelijk relevant zijn. In plaats van het taalmodel blindelings aan het hele schema bloot te stellen, beperkt het de weergave tot alleen de relevante onderdelen. Ten tweede plant een structureel-bewuste generator de vorm van de SQL-query voordat details worden ingevuld. Die schetst eerst een hoog-niveau skelet—welke clausules nodig zijn en hoe ze samenhangen—en vult daarna specifieke tabellen, joins en voorwaarden in. Deze aanpak “eerst structuur, dan inhoud” helpt de strikte grammatica van SQL te behouden, vooral bij lange en verwarde queries. Ten slotte controleert en verbetert een complexiteitsbewuste verfijner de initiële query, waarbij verschillende strategieën worden toegepast afhankelijk van hoe moeilijk de vraag lijkt te zijn.
De inzet afstemmen op de moeilijkheid van de vraag
De verfijningsfase is waar TriSQL bijzonder vernieuwend gebruikmaakt van grote taalmodellen. Het systeem beoordeelt hoe complex elke vraag en conceptuele query is, rekening houdend met factoren zoals het aantal gekoppelde tabellen, de diepte van eventuele nesting en welke soorten beperkingen worden gebruikt. Voor eenvoudige gevallen past het alleen lichte correcties toe, zoals het herstellen van kleine syntaxisfoutjes. Voor middelzware gevallen herstructureert het clausules en zorgt het ervoor dat de query overeenkomt met het gekozen schema. Voor de meest veeleisende vragen roept het het taalmodel op voor diepgaander redeneren, soms door het probleem op te delen in subtaken en alternatieve queries uit te voeren. Cruciaal is dat TriSQL zowel de originele als de verfijnde queries tegen de database uitvoert en hun gedrag—of ze draaien, hoe lang ze duren en wat ze teruggeven—gebruikt om te beslissen welke versie te behouden of of een nieuwe verfijningsronde nodig is.
Het systeem op de proef stellen
Om te testen hoe goed TriSQL werkt, toetsen de auteurs het aan een veelgebruikt benchmark genaamd Spider, samen met meerdere zwaardere varianten die domeinkennis, ongebruikelijke zinsconstructies en realistischere querystructuren introduceren. Ze meten twee zaken: exact match, wat controleert of de gegenereerde SQL-tekenreeks identiek is aan een door een mens geschreven referentie, en uitvoeringsnauwkeurigheid, wat controleert of het bij uitvoering daadwerkelijk het juiste antwoord oplevert. Over deze datasets heen behaalt TriSQL de hoogste gerapporteerde uitvoeringsnauwkeurigheid tot nu toe, terwijl de exact match concurrerend blijft met de beste eerdere systemen. Het is ook robuuster: naarmate vragen van gemakkelijk naar extreem moeilijk gaan, daalt de prestatie van TriSQL veel geleidelijker dan die van concurrerende methoden. Aanvullende experimenten op een real-world dataset voor netbeheer tonen dat hetzelfde raamwerk niet alleen gegevensopvraging aankan, maar ook insert-, update-, delete- en table-creation-commando's. Pilot-aanpassingen voor grafendatabases (Cypher) en MongoDB-pijplijnen suggereren dat het driestapsontwerp zich kan uitstrekken buiten klassiek SQL.
Wat dit betekent voor dagelijks datagebruik
Simpel gezegd brengt dit werk ons dichter bij een wereld waarin mensen met complexe databases kunnen communiceren net zo gemakkelijk als ze nu met zoekmachines praten. Door zorgvuldig te kiezen welke delen van de database in aanmerking komen, door de structuur van een query te plannen voordat details worden ingevuld, en door het gebruik van grote taalmodellen af te stemmen op de moeilijkheid van elke vraag, produceert TriSQL queries die waarschijnlijker correct uitvoeren en de beoogde resultaten opleveren. Hoewel er nog uitdagingen overblijven—zoals omgaan met dubbelzinnige vragen en onbekende databases—laat de studie zien dat een doordacht, gelaagd ontwerp natuurlijke taalinterfaces naar data zowel krachtiger als voorspelbaarder kan maken voor alledaagse gebruikers.
Bronvermelding: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Trefwoorden: text-to-SQL, interfaces voor natuurlijke taal, databasevragen, grote taalmodellen, query-robuustheid